1.大数据概述
1.列举Hadoop生态的各个组件及其功能、以及各个组件之间的相互关系,以图呈现并加以文字描述。
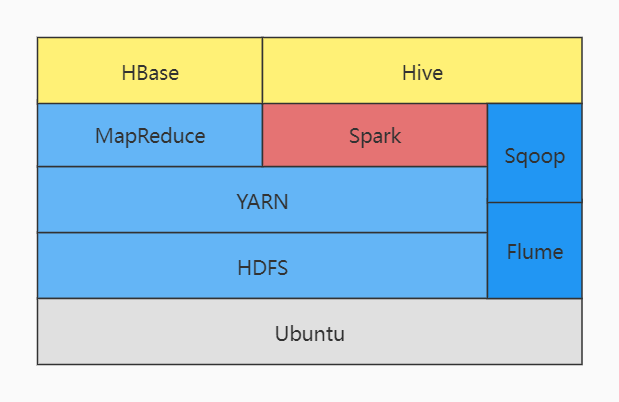
HDFS:
HDFS是整个系统的核心,负责分布式地存储数据。HDFS把整个的分布式存储系统抽象出来,使得用户不需要真正关心它的分布式,只需要关心需要存储和处理的数据本身。HDFS有两种节点,分别是NameNode和DataNode。分别用来做管理,和真正地存储数据。
YARN:
YARN就像是Hadoop的大脑,它为所有的数据处理行为做资源的分配和调度。它有两个主要组件,ResourceManager 和 NodeManager。
MapReduce:
MapReduce是整个Hadoop生态中的核心组件,它负责真正数据处理的逻辑。用户可以通过程序来实现对Hadoop环境中分布式大数据的处理。
MapReduce指的是两个函数,Map()和Reduce()。Map方法负责把基础数据进行筛选、归类、排序等等操作。它的输出是很多的键值对,这些键值对传给Reduce方法处理。Reduce方法垃圾把Map得出的结果进行统计等操作。
SPARK:
Spark是一个可以实时处理分布式大数据的工具。Spark之所以快,是因为它把很多的处理工作放在内存中,而不是每次都把一些中间结果保存回HDFS。
Spark还做了一些其他的优化,使得它的处理速度可能比常规的MapReduce快上上百倍。但这要看应用场景,并不是所有的都适合用Spark。
FLUME:
Flume可以帮助把非结构化的和半结构化的数据导进HDFS。Flume还可以把一些流数据导入HDFS,比如网络上的数据流,实时的社交数据,日志等。
SQOOP:
Sqoop和Flume很像,也是用来把数据导入HDFS或导出。但是它可以搞定结构化的数据,把数据从其他结构化的数据库和HDFS之间传输。
HBase:
HBase是一种建立在HDFS上的NoSQL数据库,让hdfs拥有海量存储功能,并且在大数据量的情况下实现秒级查询,本质还是建立在HDFS上。HBase里可以保存任何类型的数据,所以理论上所有保存在HDFS里的,以及经过处理的和处理过程中的各种数据都可以保存在HBase里面,当然,实际的使用要看具体情况。
HIVE:
让hadoop集群拥有关系型数据库的sql体验。Hive是对MapReduce的一种封装。Hive使得对数据的处理过程就像SQL查询一样简单,语句也更像是SQL,其实它支持绝大部分的SQL语句格式。
2.对比Hadoop与Spark的优缺点。
MapReduce框架局限性:
1)仅支持Map和Reduce两种操作
2)处理效率低效
Map中间结果写磁盘,Reduce写HDFS,多个MR之间通过HDFS交换数据; 任务调度和启动开销大;无法充分利用内存;Map端和Reduce端均需要排序;
3)不适合迭代计算(如机器学习、图计算等),交互式处理(数据挖掘))和流式处理(点击日志分析)
Spark相比的优势:
高效(比MapReduce快)
1)内存计算引擎,提供Cache机制来支持需要反复迭代计算或者多次数据共享,减少数据读取的IO开销
2)DAG引擎,减少多次计算之间中间结果写到HDFS的开销
3)使用多线程池模型来减少task启动开稍,shuffle过程中避免 不必要的sort操作以及减少磁盘IO操作
易用:
1)提供了丰富的API,支持Java,Scala,Python和R四种语言
2)代码量比MapReduce少
3)与Hadoop集成 读写HDFS/Hbase 与YARN集成
成本:
Spark已证明在数据多达PB的情况下也轻松自如。它被用于在数量只有十分之一的机器上,对100TB数据进行排序的速度比Hadoop MapReduce快3倍。
Spark速度很快(最多比Hadoop MapReduce快100倍)。Spark还可以执行批量处理,然而它真正擅长的是处理流工作负载、交互式查询和机器学习。
相比MapReduce基于磁盘的批量处理引擎,Spark赖以成名之处是其数据实时处理功能。Spark与Hadoop及其模块兼容。实际上,在Hadoop的项目页面上,Spark就被列为是一个模块。
Spark有自己的页面,因为虽然它可以通过YARN(另一种资源协调者)在Hadoop集群中运行,但是它也有一种独立模式。它可以作为 Hadoop模块来运行,也可以作为独立解决方案来运行。
MapReduce和Spark的主要区别在于,MapReduce使用持久存储,而Spark使用弹性分布式数据集(RDDS)
3.如何实现Hadoop与Spark的统一部署?
由于Hadoop生态系统中的一些组件所实现的功能,目前还是无法由Spark取代的,比如Storm。所以在许多实际应用中,Hadoop和Spark的统一部署是一种比较现实合理的选择。Spark可以运行在资源管理框架YARN之上,因此,可以在YARN之上进行统一部署。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号