
层次(树型)数据的存储与访问(一)
在软件项目中,经常会遇到层次数据的处理问题,比如产品分类、树型目录、企业组织结构等等。一般情况下,这些数据不得不存储在关系数据库中,由于关系数据库表是扁平的二维结构,所以必须将层次数据平面化,才能适应关系模型的存储访问模式。目前基于此的转换方法很多,流行的主要有四种:多表模式、邻接表模式、编码模式、改进的前序前历模式。本文在收集整理的基础上,通过实例对比、分析、探讨,希望给不熟悉的朋友提供一些参考。
首先给出一个问题,是一个商品分类的例子,需要在关系数据库中存储和处理,为了简便起见,分类的层次尽量的少,并且在下文中只讨论处理分类,而并不涉及到具体产品内容。如图所示。
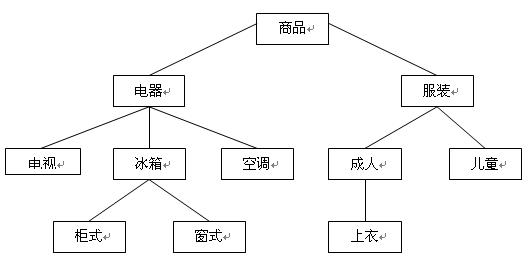
一、多表模式:
多表模式就是用多表来存储层次数据,方法是每一层用一张表表示,这是一种非常原始的方法,不过很好理解,在数据层次很少的,三层以下,特别是两层中得到了广泛的应用。上面的问题可以用三张表分解,根“商品”这一层在此可以是虚拟的,表中可以省略。
1、 一级分类表(table1):
|
Id |
Title |
|
1 |
电器 |
|
2 |
服装 |
2、 二级分类表(table2):
|
Id |
Title |
Parent |
|
11 |
电视 |
1 |
|
12 |
冰箱 |
1 |
|
13 |
空调 |
1 |
|
14 |
成人 |
2 |
|
15 |
儿童 |
2 |
3、 三级分类表(table3):
|
Id |
Title |
Parent1 |
Parent2 |
|
111 |
柜式 |
1 |
12 |
|
112 |
窗式 |
1 |
12 |
|
113 |
上衣 |
2 |
14 |
在上面表的设计中,每层保存上级Id字段,在三级分类表中,更保存了所有上级分类(只保留直接上级即可),可能不符合范式,但这样可以方便于数据库访问;表中Id字段值做了特别处理,是为了显而易见,实际当然不是这样的。
在多表模式下,每个分类节点都处在相应级别的表中,分类节点的增加、更新、删除操作都很方便,删除时需要先删除下级表中相关信息。
例一, 在“成人”分类节点下,增加一个新的分类节点“长裤”。
Insert into table3(Id,Title,Parent1,Parent2) values(114,”长裤”,2,14)
例二, 删除“成人”节点:
A, 先删除“成人”节点的下级节点:
delete from table3 where Parent2=14
B,再删除“成人”节点:
Delete from table3 where Id=114
查询操作根据需要有不同的复杂度,经常要横跨多表,不甚方便。
例三, 查询获取“窗式”节点的路径:
Select Title from table3 where Id=112 /*查询本层*/
Union
Select Title from table2 where Id=(select Parent2 from table3 where Id=112) /*上层*/
Union
Select Title from table1 where Id=(select Parent1 from table3 where Id=112)/*再上层*/
例四, 遍历并打印所有分类树:
通过循环,分别从第一级迭代到第三级,用C#实现(注:为了简便易阅读,其中数据库操作,使用了本人编写的数据库操作组件,在本人博客中有完整代码,可以下载使用)
Db db=new Db();
DataTable table1=db.RunDataTable("select * from table1",CommandType.Text); //获取一级分类
for(int i=0;i< P>
DataRow row1=table1.Rows[i];
Console.WriteLine(row1["Title"].ToString()+" ");
string sql="select * from table2 where Parent="+row1["Id"].ToString();
DataTable table2=db.RunDataTable(sql,CommandType.Text);//获取二级分类
for(int j=0; j< P>
DataRow row2=table2.Rows[j];
Console.WriteLine("----"+row2["Title"].ToString()+" ");
sql="select * from table3 where Parent2="+row2["Id"].ToString();
DataTable table3=db.RunDataTable(sql,CommandType.Text);//获取三级分类
for(int k=0;k< P>
Console.WriteLine("--------"+table3.rows[k]["Title"].ToString()+" ");
}
}
}
可以看到,在多表模式下,查询操作经常要扫描所有表,效率确实不高,同时随着层次的增加,查询复杂性也成倍增长,所以多表模式只能用于数据层次固定且层次很少的场合,当然如果只有两层,却是首选。
二、邻接表模式:
邻接表模式是使用最频繁的层次数据到关系表的转换方法,有数据结构基础的朋友,首先会想到这种方法,与多表方式不同,邻接表模式,把层次数据平面化到一张表中,而在每个分类节点中保存一个父节点的信息,根节点的父节点表示为空。如图
商品分类表(table1):
|
Parent |
Title |
|
|
商品 |
|
商品 |
电器 |
|
商品 |
服装 |
|
电器 |
电视 |
|
电器 |
冰箱 |
|
电器 |
空调 |
|
服装 |
成人 |
|
服装 |
儿童 |
|
冰箱 |
柜式 |
|
冰箱 |
窗式 |
|
成人 |
上衣 |
在表中Parent字段直接使用父节点的Title值,这不是一个好的设计,应该使用数据标识表示较好,如此是因为这样比较容易看明白。
实际应用中,也可增加一个字段表示分类节在所在的层次。这样可是简化一些操作,如果合理使用索引也能提高访问效率。
下面看一些基本访问操作。
例一、在“成人”节点下增加一个新分类“长裤”:
insert into table1(Parent,Title) values("成","长裤")
例二、获取某一节点的子树:
在邻接表访问操作中,经常要用到递归方法,可以使用数据库的存储过程或函数实现,但存储过程或函数中,递归调用一般有层数限制,比如sql server2000被限制在32层之内。在下面的例子中都用C#函数实现。
public void DisplayTree(string title){
string sql="select title from table1 where Parent='"+title+"'";
Db db=new Db();
DataTable table=db.RunDataTable(sql,Command.Text);
for(int i=0;i
Console.WriteLine("----"+table.Rows[i]["Title"].ToString()+" ");
DisplayTree(table.Rows[i]["Title"].ToString());
}
}
例三、获取某一节点的路径:
public string NodePath(string title){
Db db=new Db();
string sql="select Parent from table1 where Title='"+title+"'";
string? path=db.RunScalar("sql,CommandType.Text).ToString();
if(path==null){
path+=","+title;
}
else{
path+=","+NodePath(path);
}
return path;
}
例四,删除一个分类节点:
public void DeleteTree(string title){
string sql="select Title from table1 where Title='"+title+"'";
Db db=new Db();
DataTable dt=db.RunDataTable(sql,Command.Text);
if(dt.Rows.Count<1) return;
sql="select Title from table1 where Parent='"+dt.Rows[0]["Title"].ToSting();
DataTable dt1=db.RunDataTable(sql,Command.Text);
if(dt1.Rows.Count<1){
db.RunNon("delete from table1 where Title='"+title+"'",CommandType.Text);
}
else{
for(int i=0;i
DeleteTree(dt1.Rows[i]["Title"].ToString());
}
}
}
邻接表模式,直观、简明、操作简单、容易理解,并且可以实现无限级分类,是使用最多也是比较好的一种方法,但是在数据操作时,通常需要使用“递归”调用,并反复扫描数据库表,效率不高,cpu占用很大,如果数据量很大,运行会很慢,对于网络应用可能会引起超时。
上面先介绍两种常用方法。其它在《层次数据的存储与访问(二)》中继续探讨。
原文链接:https://blog.csdn.net/kkeemmgg/article/details/2747502

 浙公网安备 33010602011771号
浙公网安备 33010602011771号