
linux命令(12)cut
1. 作用
cut是一个选取命令,就是将一段数据经过分析,取出我们想要的。一般来说,选取信息通常是针对“行”来进行分析的,并不是整篇信息分析的。
2. 用法
cut 【参数】【file or stdin】
参数:
-d:后面接分隔字符,与-f一起使用,默认的字段分隔符为制表位TAB;
-f:依据-d的分隔字符将一段信息切割开,用-f取出第几段;
-b:以字节为单位进行分割;
-c:以字符为单位进行分割;
-n:与-b连用,不分割多字节字符;
--complement:提取指定字段之外的列。
范围表示:
N-:从第N个字节、字符、字段到结尾;
N-M:从第N个字节、字符、字段到第M个(包括M)字节、字符、字段;
-N:从第1个字节、字符、字段到第N个(包括N)字节、字符、字段。
3. 举例子
3.1 cut -d ':' -f 1
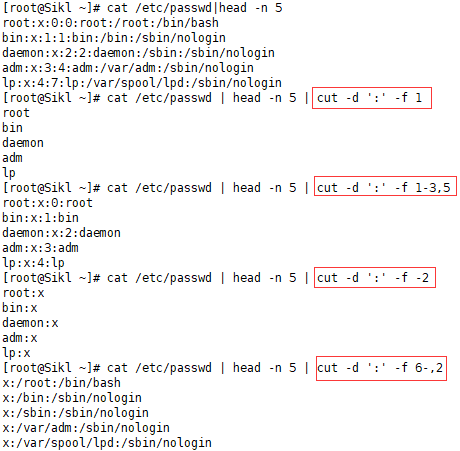
注:cut会先把-f后面所有的定位进行从小到大排序,然后再提取,所以结果不会颠倒顺序。
注:结果是输出整行,不会出现第3个字段的重复出现。
问题:在cut -d中用什么符号来设定制表符或空格呢?
多个空格和制表位tab怎么看出来,用sed -n l file命令,l为字母L的小写:
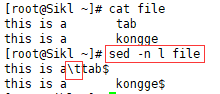
注:空格还是按原来显示,制表位tab显示为\t,换行符为$
默认分隔符为制表位tab:

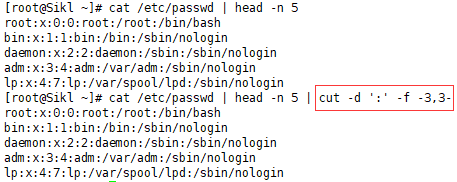
以空格作为分隔符,-d后的引号里直接敲一个空格即可:

-d后的引号里多敲一个空格会出错:

注:如果文件里面的某些域是由若干个空格来间隔的,那么用cut就有点麻烦了,因为cut只擅长处理“以一个字符间隔”的文本内容。
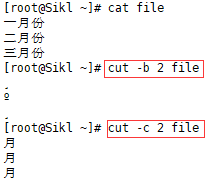
3.2 cut -b 2
取出每行的第2个字节:
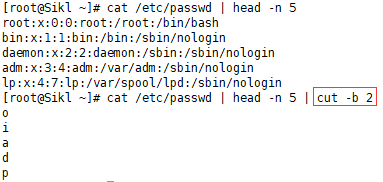
3.3 cut -c 2
取出每行的第2个字符:

注:英文字母都是单字节字符,所以-b和-c的结果一样,若为中文则不同:
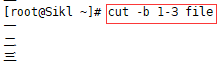
3.4 cut -nb 1-3 file

注:当遇到多字节字符时,可以使用-n选项,-n用于告诉cut不要将多字节字符拆开。
但是不加-n也可以,尴尬。。。
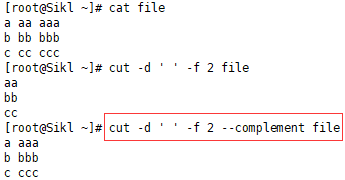
3.5 cut -d ' ' -f 2 --complement file
提取指定字段之外的列:
posted on 2017-10-28 14:58 seabiscuit0922 阅读(269) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号