
linux命令(10)uniq
1. 作用
用于报告或忽略文件中的重复行,一般与sort命令结合使用,因为uniq 不会检查重复的行,除非它们是相邻的行。
2. 用法
uniq 【参数】【file or stdin】
参数:
-c,--count:在该行前加上该行出现的次数;
-d,--repeated:只输出重复的行,重复的行只输出一次;
-D,--all-repeated:只输出重复的行,重复几次输出几次;
-u,--unique:只输出不重复的行;
-f,--skip-fields:忽略前N个字段;
-i,--ignore-case:不区分大小写;
-s,--skip-chars:忽略前N个字符;
-w,--check-chars:忽略位置>N的字符。
3. 举例子
3.1 uniq
去除重复的行后输出:

注:同sort -u file1
3.2 uniq -c
在该行前加上该行出现的次数:

3.3 uniq -d
只输出重复的行,重复的行只输出一次:

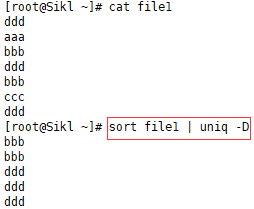
3.4 uniq -D
只输出重复的行,重复几次输出几次:
3.5 uniq -u
只输出不重复的行:

3.6 uniq -f
忽略前N个字段:

注:忽略前1个字段,从字段2(第2列)开始比较。
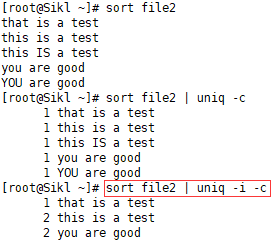
3.7 uniq -i
不区分大小写:
3.8 uniq -s
忽略前N个字符:
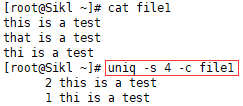

注:比较包含空格。
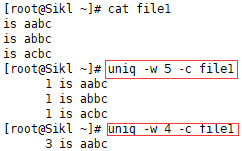
3.9 uniq -w
忽略位置>N的字符:
posted on 2017-10-27 15:51 seabiscuit0922 阅读(209) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号