mysql学习
 介绍一下Mysql的初级使用
介绍一下Mysql的初级使用
mysql语法规范
- 不区分大小写,但建议关键字大写, 表名和列名小写
- 每条命令用英文的分号结尾
- 每条命令根据需要, 可以进行缩进或换行
- 注释
单行:#注释文字
单行注释:-- 注释文字(注意--后面必须有空格)
多行注释: /*注释文字*/
Navicat for Mysql的使用
- 首先建立连接
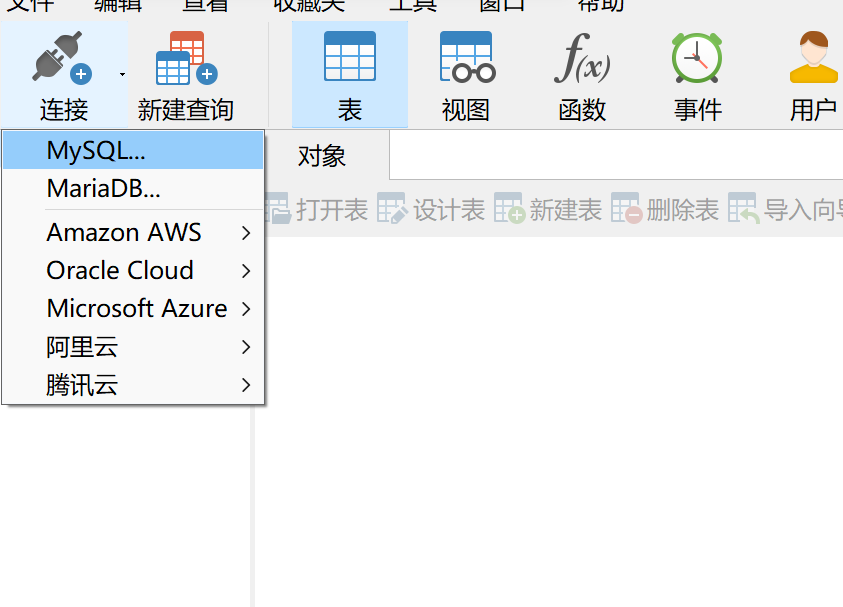
- 双击激活连接,并建立数据库
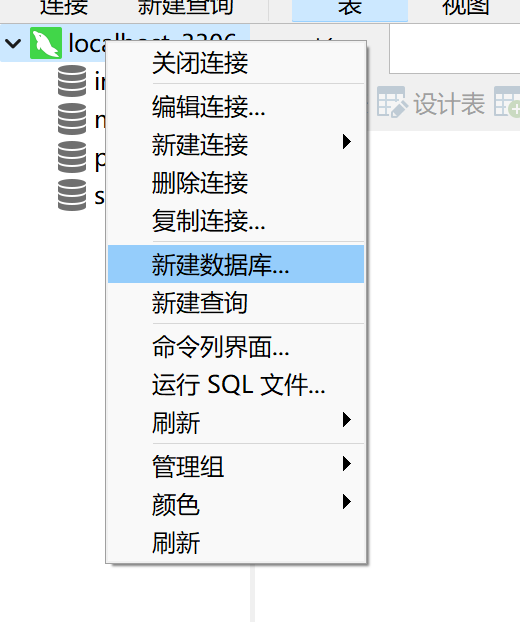
- 使用utf8mp4编码,这里是指每个character占用4 bytes
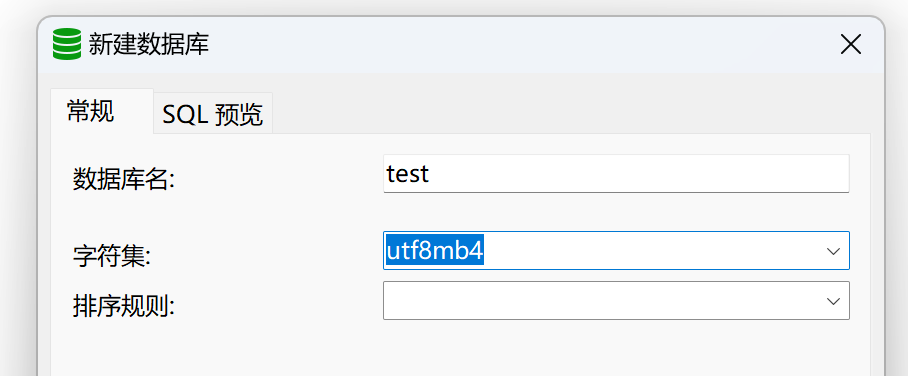
- 在新建的数据库中可以导入表了
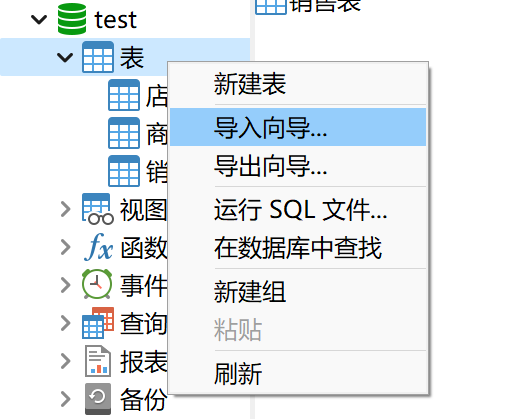
- 点击新建查询, 注意选择正确的数据库
正常其实有use test的语句, 但是这是第三方软件所以没有g
SELECT运行的本质
- 其实Mysql的SELECT语句可以理解为一种创造性的语句或者说每个语句的结果都是返回一个表,比如
select 100;就会出现列名和值都是100的表, 所以需要给列中的值增加东西时就可以利用这个特性,具体参考CONCAT() - ``符号表示列名, ""符号表示字符
基础查询语句
最简单的查询
- 语法:
SELECT 查询列表 FROM 表名;
例1:
注意, 如果列名和表名与关键字有重合时, 使用 ` 来区分SELECT date,price FROM table1; # 可以多个列一起查
可以选中某一行单独运行
查询字段重命名AS
-
语法:
SELECT 原名 AS 别名 FROM 表名; -
语法:
SELECT 原名 别名 FROM 表名;# 注意有空格注意: 别名中包含特殊符号时, 要用双引号括起来。【例如空格,#号等】
例:SELECT 商品编码 AS "product code" FROM \`销售表\`;
去重复DISTINCT
- 语法:
SELECT DISTINCT 字段 FROM 表名;
例1:
例2:SELECT DISTINCT 店名 FROM 销售表;# 这样的结果每列不会重复
DISTINCT的优先级比较高放在前面, 但是多个列中也会出现重复,不过是会选择第二个中出现过一次的。SELECT DISTINCT 大类编码, 小类名 FROM 商品表;
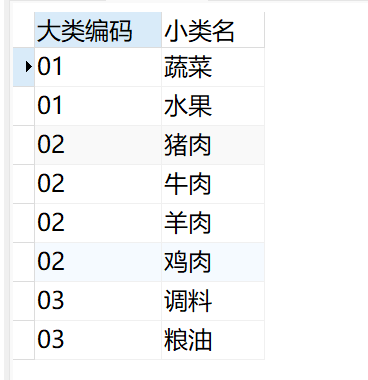
字段连接CONCAT()
- 语法:
SELECT CONCAT(字段1, 字段2,...) AS 别名 FROM 表名;
顾名思义, CONCAT()可以选择多个表的数据组合成为一列.
例:SELECT CONCAT(商品编码,"\_") AS 商品编码 FROM 销售表;
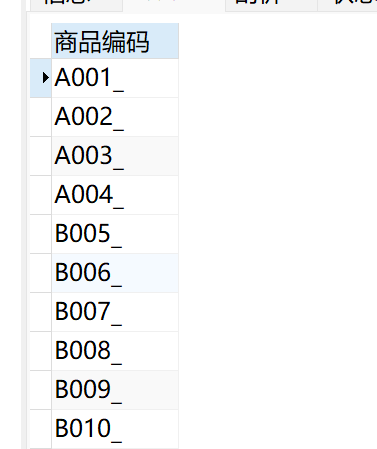
字段值为空怎么填值
- 使用
IFNULL()函数
例如:SELECT IFNULL(字段名,"替代值") AS 别名 FROM 表名; # 这样就会把原来为空的替代为别的 IFNULL()也可以与CONCAT()一起用
例:SELECT CONCAT(商品编码,"_",IFNULL(销售数量,0)) AS 别名 FROM 销售表;
条件查询where
-
语法
SELECT 列名 FROM 表名 where 筛选条件; -
常见的运算符有,
=(等于,注意是一个等号),<>(不等于,!=也偶尔用), <(小于),<=(小于等于),>(大于), >=(大于等于) -
常用的逻辑运算
and, or, not,and :左右两边都为True才为True,否则为False
or: 左右两边有一个为True就为True,两边都为False才为False
not: 取反!例:
SELECT * FROM 销售表 where 销售数量>250 and 销售数量<300; # 实际这种区间并不会这样写,只是举个例子
模糊查询
-
like: 通配搜索, 一般与通配符搭配使用,
%代表任意多个字符, 包含0个字符,_表示任何单个字符.例如:
1. 商品编码有A的 SELECT * FROM 销售表 WHERE 商品编码 LIKE '%a%' #不区分大小写 2. 商品编码第一个字符为A SELECT * FROM 销售表 WHERE 商品编码 LIKE "A%"; #""与''都可以 3. 商品编码地三个字符为B,第五个字符为C SELECT * FROM 销售表 WHERE 商品编码 LIKE "__b_C"; # 一个下划线替代一个字符 4. 第二个字符为下划线 SELECT * FROM 销售表 WHERE 商品编码 LIKE '_\_' # 使用转义字符就好
BETWEEN .... AND ...
-
语法:
SELECT 查询列 FROM 表名 WHERE 销售数量 BETWEEN 150 AND 250;between…and 这两个值是包含本身的,就相当于是大于等于或小于等于。
这两个值的位置不能交换,他的意思是大于等于左边,小于等于右边。 -
使用
NOT可以排除, 如:SELECT * FROM `销售表` WHERE 销售数量 NOT BETWEEN 150 AND 250;
in 指定条件范围
-
例如: 店号为1,3,7这三家店铺的销售数据
SELECT * FROM 销售表 WHERE 店号=1 OR 店号=3 OR 店号=7; # 这样写不够方便,可以用下面的 SELECT * FROM 销售表 WHERE 店号 IN(1,3,7);in列表的值类型必须是一致类型
in列表的值不支持通配符,所以不要用下划线百分号之类的了
IS NULL为空值
- =号运算符不能判断NULL值,必需使用is null
- 如果相查非空值, 可以使用
SELECT * FROM 销售表 WHERE 销售数量 IS NOT NULL
排序查询ORDER BY
升序
- 语法:
SELECT 字段名 FROM 表名 ORDER BY 字段名 ASC;# ASC可以省略
降序
-
语法:
SELECT 字段名 FROM 表名 ORDER BY 字段名 DESC在同时使用 ORDER BY 和 WHERE 子句时,应该让 ORDER BY 位于 WHERE 之后,否则报错
如:SELECT * FROM 商品表 where 小类名="调料" ORDER BY `进价` DESC;
排序优先级
-
比较
SELECT 字段名 FROM 表名 ORDER BY 字段名1 DESC,字段名2 ASC;ORDER BY语句中,优先排序的字段放在前面,不同字段可以指定不同的排序规则,如果没有指定排序规则,则默认为升序(ASC)排列。
例如:
SELECT * FROM `销售表` ORDER BY 销售数量 DESC,日期 ASC;
按长度排序LENGTH()
- 例如:
SELECT * FROM 店铺表 ORDER BY LENGTH(`店号`) DESC;
中文列排序
-
中文列排序往往需要自定义的排序, 如名字顺序, 月份顺序等, 所以用到的
INSTR()有些类似EXCEL里面的自定义排序 -
INSTR函数有些类似于工作表函数FIND,查找一个字符串在另一个字符串中的位置,和FIND不同的是,当找不到相关值时,结果返回0,而非错误值。
INSTR(str, substr),返回substr在str中的位置,若不存在,则返回0。例:
SELECT * FROM `测试` ORDER BY INSTR('五月,四月,三月,二月,一月',月份) SELECT * FROM 商品表 ORDER BY INSTR("果菜, 肉, 副食",`大类名`); #前面是主字符串名,后面是子字符串名这里的INSTR函数里面就自定义了排序的序列, 后面的
大类名就是列名.
使用函数处理数据
函数调用与分类
- 调用
SELECT 函数名(实参列表) FROM 表名;# 如果函数名的括号里有字段名, 就要加表名, 否则不用加
1. 单行函数
单行函数是传入一个值, 返回一个值, 之前已经接触了几个函数, 如CONCAT(), LENGTH(), IFNULL(), INSTR()
如:
SELECT CONCAT(商品名称,"_",LENGTH(商品名称)) AS 信息 FROM 商品表
SELECT LENGTH("李");
常用文本函数
- LEFT(字段名,数字). 这个函数可以选择截取值的前两个字符.
- LOWER(字段名). 可以让值变为小写
- UPPER(字段名). 可以让值变成大写
- TRIM(字段名). 去掉左右两边的空格
- LTRIM(字段名). 去掉左边的空格
- RTRIM(字段名). 去掉右边的空格
- 字符截取SUBSTR(字段名,起始位置,结束位置), 结束位置可以缺省. 注意起始位置为1
- INSTR(主字符串,子字符串)
SELECT INSTR('哈哈你好呀','你好') - LPAD(字符串,字符位数,"占位符") # 左填充到几个字符
- RPAD(字符串,字符位数,"占位符") # 左填充到几个字符
- REPLACE(字符串,替换谁,换成什么)
SELECT REPLACE(商品名称,"黄瓜","西瓜") AS 商品名称 FROM 商品表;
数学函数
- 四舍五入
ROUND(字段名, 位数)如果不指定位数则四舍五入为整数 - 向上取整
CEIL() - 向下取整
floor() - 截断
truncate(字段名, 小数点后位数)#截取小数点后几位,1则小数点后一位 - 取余数
MOD(除数, 被除数)
日期函数
-
返回当前系统日期
SELECT now( ) -
返回当前系统日期,不包含时间
SELECT CURDATE() -
返回当前时间,不包含日期
SELECT curtime() -
获取指定的部分,年、月、日、小时、分钟、秒.
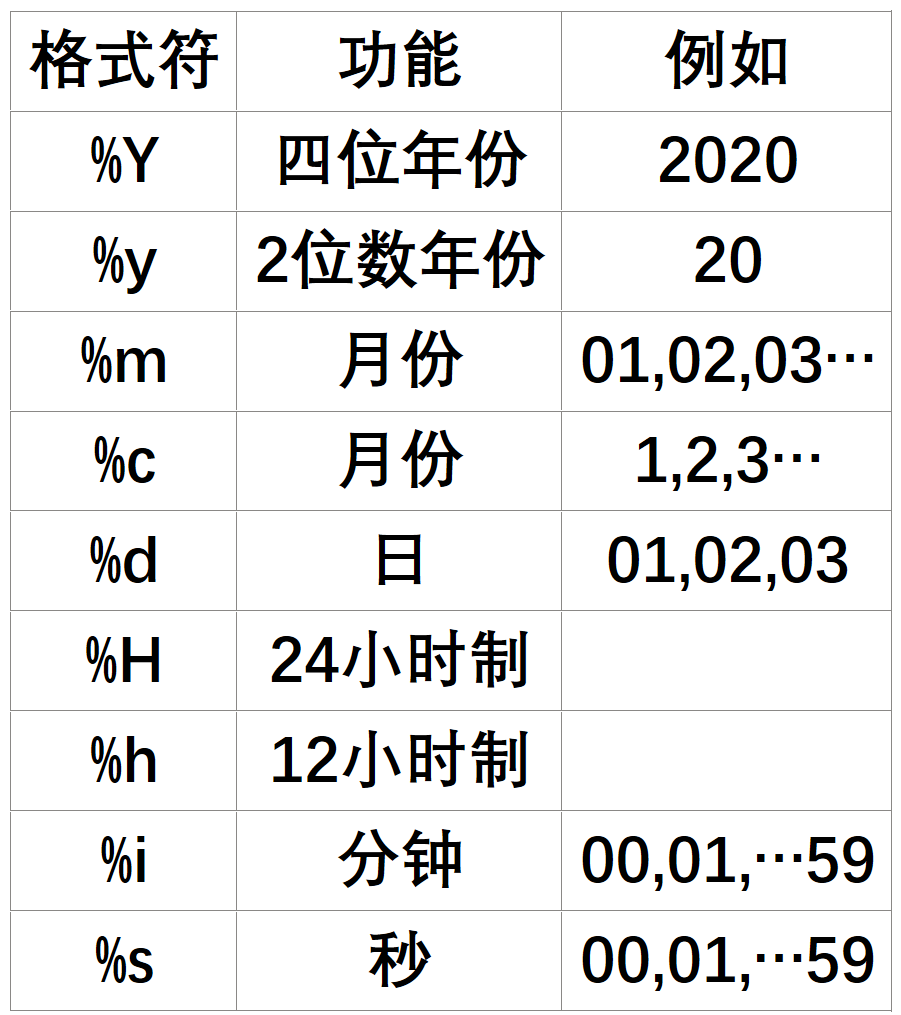
如YEAR(NOW()) 或 YEAR(日期字段) Month(日期) # 返回:数字月份 monthname() # 返回: 英文月份 Day(now()) # 天 Hour(now()) # 小时 minute(now()) # 分钟 second(now()) # 秒 -
将日期格式的字符串转换成指定的日期格式
SELECT str_to_date('3-30-2020','%m-%d-%y') -
将日期格式转成字符
-
注意这个与第5个的不同之处在于这是个日期格式的, 电脑已经可以识别了,然后可以设置成想要展示的格式.
如SELECT DATE_FORMAT('2020/3/30','%Y年%m月%d日'); SELECT DATE_FORMAT(日期,'%Y年%m月%d日') AS 日期 FROM 销售表;
流程控制函数
-
IF函数
if(表达式成立,返回值,否则返回值)
可以看到IF函数其实已经包含了else, 所以不适用于多条件
如:SELECT *,IF(销售数量>200,'优秀','一般') FROM `销售表` # 也可以看出如果需要表上新加一列只需要*后面加上一列. -
CASE函数
一般有两种写法


如:
SELECT `商品名称`,`进价`,`售价`,
CASE 大类编码
WHEN 01 THEN truncate(售价*1.1,2)
WHEN 02 THEN truncate(售价*1.2,2)
WHEN 03 THEN truncate(售价*1.05,2)
ELSE 售价
END AS 新售价
FROM `商品表`;
SELECT `店号`,`商品编码`,`销售数量`,
CASE
WHEN `销售数量`>250 THEN '优'
WHEN `销售数量`>150 THEN '良'
WHEN `销售数量`>100 THEN '中'
ELSE '差'
END AS 评价
FROM `销售表`;
2. 分组聚合函数
简单的聚合函数
简单聚合函数是传入一组值, 返回一个值, 做统计时使用, 例如Sum
-
常用的聚合函数有
SUM(总和), MAX(最大值), MIN(最小值), AVG(平均值) 以及COUNT(计数)
如:SELECT SUM(销售数量) FROM `销售表`; SELECT AVG(销售数量) FROM `销售表`; SELECT MAX(销售数量) FROM `销售表`; SELECT MIN(销售数量) FROM `销售表`; SELECT COUNT(销售数量) FROM `销售表`; # 统计有多少行, 多少个值的意思SELECT SUM(销售数量) AS 求和,TRUNCATE(AVG(销售数量),2) AS 求平均,MAX(销售数量) AS 最大值,MIN(销售数量) AS 最小值,COUNT(销售数量) AS 计数 FROM `销售表`;

Count(*) 用来统计表中的总行数,比Count(distinct 字段名)用的时候要多一些,它的优点是只要有一列这一行中有数据不为空就计1次数,所有列这一行全为空就不计数了。
分组聚合GROUP BY
-
可以使用group by子句将表中的数据分成若干组
语法:SELECT 字段名,聚合函数(字段名) FROM 表名 WHERE 条件 GROUP BY 分组表达式 ORDER BY 字段名;注意SELECT后面的第一个字段名和GROUP BY的字段名一致, where 和 order by 可以省略
例子:
1、查询每家店铺的商品最小销售数量 SELECT 店号,MIN(销售数量) AS 最小销售量 FROM `销售表` GROUP BY 店号; 2、查询每个大类对应的商品个数 SELECT 大类名,count(*) AS 商品数 FROM `商品表` GROUP BY 大类名;
HAVING与WHERE字句
-
条件这个字段不存在于这张表中的时候,我们使用
HAVING,如果存在,那么使用WHERE -
HAVING在分组后使用,WHERE在分组前使用
-
运算顺序:WHERE优先于HAVING
-
作用对象不同,WHERE只作用于表,而HAVING作用于GROUP BY子句的分组结果,如果不存在GROUP BY子句,则作用于WHERE子句的搜索结果,如果WHERE子句也不存在,则直接作用于表
例1:2020年1月1日这一天,各店铺最小销售数量 SELECT 店号,MIN(销售数量) AS 最小销售量 FROM `销售表` WHERE 日期 = '2020-01-01' GROUP BY 店号; 例2:哪个小类的商品个数大于2 (提到个数先想到哪个函数?) count(*)>2 但是他不能做where子句条件,因为哪家表里都没有count(*)这个字段,详见(4) SELECT 小类名,COUNT(*) AS 商品个数 FROM `商品表` GROUP BY 小类名 HAVING COUNT(*)>2; 例3:查询每个店铺2020年1月1日至1月3日最高销量大于250 SELECT 店号,MAX(销售数量) AS 最大销量 FROM `销售表` WHERE 日期 BETWEEN'2020-01-01' AND '2020-01-03' GROUP BY 店号 HAVING 最大销量>250;
ORDER BY放最后
- 可以使用多个字段进行分组
SELECT 日期,商品编码,销售数量 FROM `销售表` GROUP BY 日期,商品编码 ORDER BY 销售数量 DESC;
LIMIT选取前几个
- 选择当前表的前几个, 注意LIMIT不具备排序功能
例如:查询每家店铺,所有日期区间内,总销量的前3名。 SELECT 店号,SUM(销售数量) AS 销售总量 FROM 销售表 GROUP BY 店号 ORDER BY 销售总量 DESC LIMIT 3;
语法结构及顺序
SELECT [DISTINCT] 字段名 FROM 表名
[WHERE] 条件筛选
[GROUP BY] 分组
[HAVING] 分组筛选
[ORDER BY] 排序
[LIMIT] 名次或分页
-
运算顺序
(1)首先运算的是FROM子句,根据FROM子句中指定的一个或多个表创建工作表。
(2)如果存在WHERE子句,则WHERE子句对步骤1获得的工作表进行条件筛选,删除不符合条件的记录。
(3)如果存在GROUP BY子句,则对步骤2生成的结果表按指定字段进行分组,生成一份新的结果表。
(4)如果存在HAVING子句,则对步骤3的结果表按指定条件进行筛选,删除掉不满足筛选条件的记录。
(5)执行SELECT子句,删除不包含在SELECT 字段名 ,所指定的字段。如果SELECT子句中包含关键字DISTINCT,则执行去重复运算……
(6)如果有ORDER BY子句,则按指定的排序规则对结果表进行排序操作。
(7)如果需要找前几名,用LIMIT 名次 -
总结
(1)来自哪张表
(2)where筛选条件
(3)[GROUP BY] 分组
(4)[HAVING] 分组筛选
(5)排序
(6)名次或分页
多表合并
多表数据合并UNION, 这是列名不变, 扩充数据的方式
-
将2张表合并 (不去重复)
SELECT * FROM 一班 UNION ALL SELECT * FROM 二班; -
将2张表合并 (去重复, 行的值都一致就会去除)
SELECT * FROM 一班 UNION SELECT * FROM 二班;不管是UNION还是UNION ALL,都要求SELECT语句拥有相同的列数,而且字段的排放顺序必须相同。
如果两张原始表的顺序不一致,你需要手动在SELECT后面写字段强行把他顺序变成一致
处理不同列名的合并
-
下面演示遇到列不一致的情况怎么处理, 注意可以将不一致的列名那里放置特殊值
SELECT 姓名,语文,数学,英语 FROM `1班` UNION ALL SELECT 姓名,语文,NULL,英语 FROM `2班` SELECT 姓名,语文,数学,英语 FROM `1班` UNION ALL SELECT 姓名,语文,"未考",英语 FROM `2班`
连接查询
多表配合使用, 这是扩展列名
-
比较复杂的写法
SELECT `销售表`.`店号`,`店铺表`.`店名`,`销售表`.`商品编码`,`销售表`.`销售数量` FROM `销售表`,`店铺表` WHERE `店铺表`.`店号`=`销售表`.`店号`;这里要注意FROM是从两个表中得到的
-
使用别名的方法
SELECT a.`店号`,b.`店名`,a.`商品编码`,a.`销售数量` FROM `销售表`a,`店铺表`b WHERE b.`店号`=a.`店号`; -
更简化的方法
- 凡是字段名在FROM表中是唯一的,字段名前可以省略表名
SELECT a.店号,店名,商品编码,销售数量 FROM `销售表`a,`店铺表`b WHERE b.`店号`=a.`店号`;
内部连接
- 内连列如图所示, 取的是交集
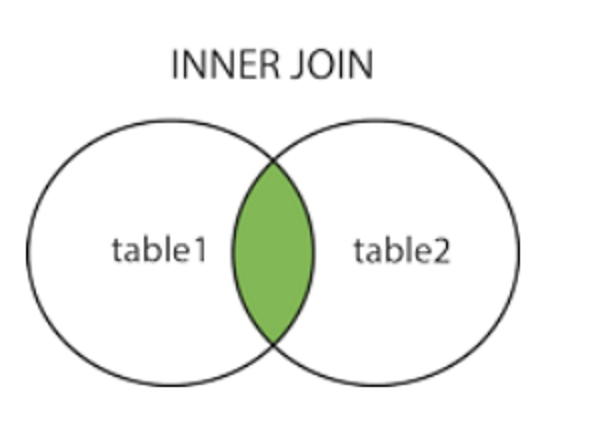
FROM+WhERE 19992年的方法
- 语法:
SELECT 字段名 FROM 表1,表2 WHERE 表1.字段名=表2.字段名
如:
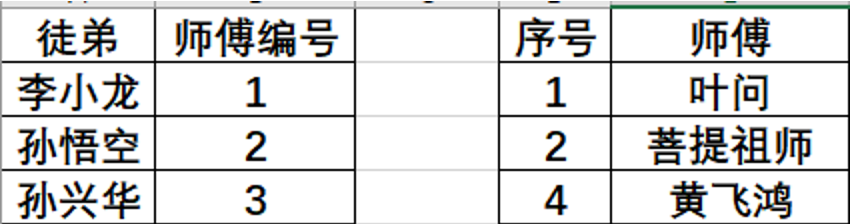
1992年标准:
SELECT 徒弟,师傅 FROM 表a,表b WHERE 表a.师傅编号=表b.序号;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号