从头学pytorch(二十):残差网络resnet
残差网络ResNet
resnet是何凯明大神在2015年提出的.并且获得了当年的ImageNet比赛的冠军. 残差网络具有里程碑的意义,为以后的网络设计提出了一个新的思路.
googlenet的思路是加宽每一个layer,resnet的思路是加深layer.
论文地址:https://arxiv.org/abs/1512.03385
论文里指出,随着网络深度的增加,模型表现并没有更好,即所谓的网络退化.注意,不是过拟合,而是更深层的网络即便是train error也比浅层网络更高.
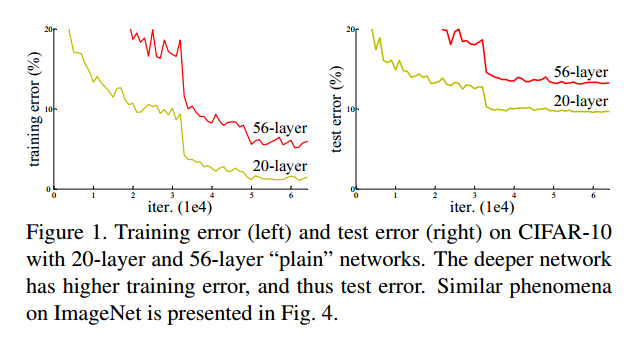
这说明,深层网络没有学习到合理的参数.
然后,大神就开始开脑洞了,提出了残差结构,也叫shortcut connection:
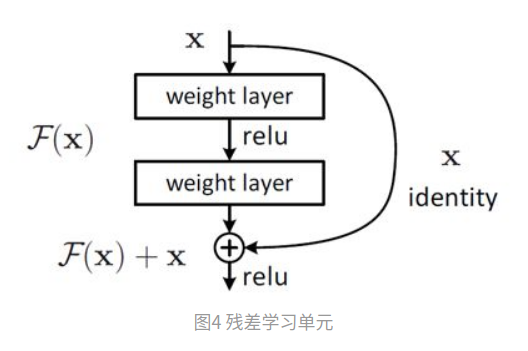
以前学习的是F(x)(就是每一层的映射关系,输入x,输出F(x)),现在学的是F(x)-x,那为啥学习F(x)-x就更容易呢?
关于残差网络为何有效的分析,参考:https://zhuanlan.zhihu.com/p/80226180
目前并没有一个统一的结论,我比较倾向于模型集成这个说法.
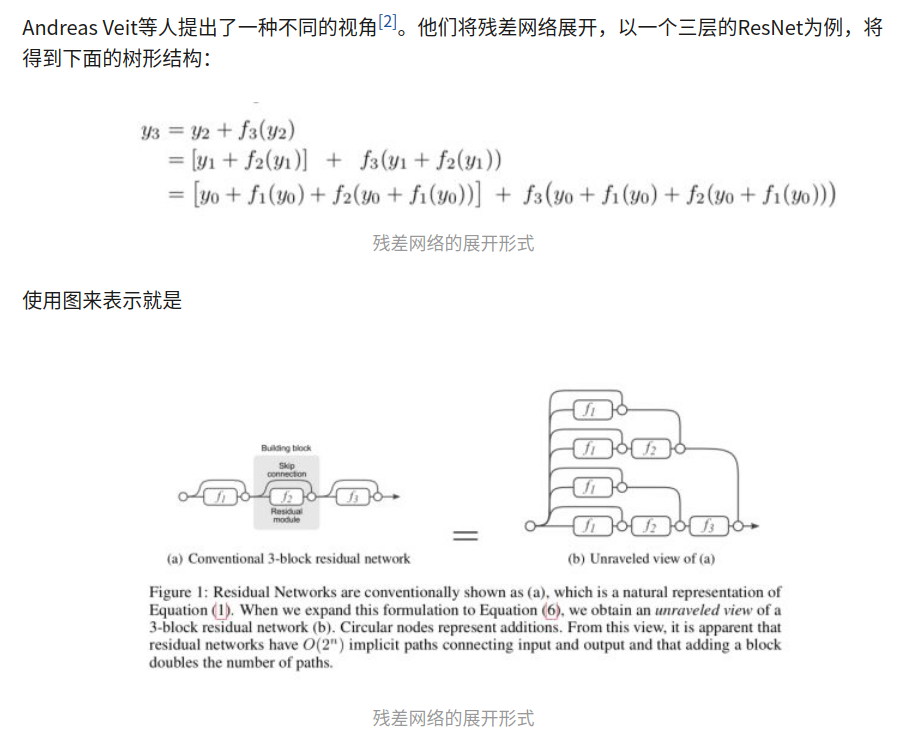
残差网络就可以被看作是一系列路径集合组装而成的一个集成模型,其中不同的路径包含了不同的网络层子集。Andreas Veit等人展开了几组实验(Lesion study),在测试时,删去残差网络的部分网络层(即丢弃一部分路径)、或交换某些网络模块的顺序(改变网络的结构,丢弃一部分路径的同时引入新路径)。实验结果表明,网络的表现与正确网络路径数平滑相关(在路径变化时,网络表现没有剧烈变化),这表明残差网络展开后的路径具有一定的独立性和冗余性,使得残差网络表现得像一个集成模型(ensemble)
模型结构
大神的思路咱跟不上,管他娘的为啥有效呢,深度学习里的玄学事情还少吗,这种问题留给科学家去研究吧. 咱们用深度学习是来做产品的,实际提高生产力的.
我们来看看resnet模型结构.

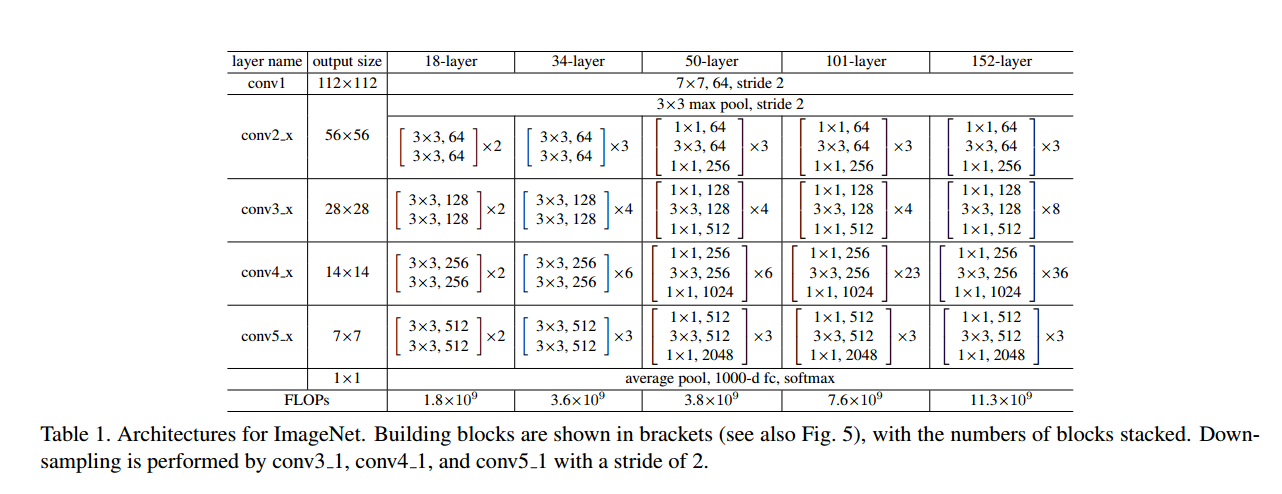
实现残差结构
按照论文里的34-layer这个来实现.
仔细看上面两个图可知,残差块用的卷积核为kernel_size=3.模型的conv3_1,conv4_1,conv5_1之前做了宽高减半的downsample.conv2_x是通过maxpool(stride=2)完成的下采样.其余的是通过conv2d(stride=2)完成的.
resnet采取了和vgg类似的堆叠结构,只不过vgg堆叠的是连续卷积核,resnet堆叠的是连续残差块.和vgg一样,越往后面的层,channel相较于前面的layer翻倍,h,w减半.
代码不是一蹴而就的,具体如何一步步实现可以去看github提交的history.
残差块的实现注意两点
- 第一个卷积需要传入stride完成下采样
- 卷积后改变了输入shape的话,为了完成相加的操作,需要对输入做1x1卷积
class Residual(nn.Module):
def __init__(self,in_channels,out_channels,stride=1):
super(Residual,self).__init__()
self.stride = stride
self.conv1 = nn.Conv2d(in_channels,out_channels,kernel_size=3,stride=stride,padding=1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(out_channels,out_channels,kernel_size=3,padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
# x卷积后shape发生改变,比如:x:[1,64,56,56] --> [1,128,28,28],则需要1x1卷积改变x
if in_channels != out_channels:
self.conv1x1 = nn.Conv2d(in_channels,out_channels,kernel_size=1,stride=stride)
else:
self.conv1x1 = None
def forward(self,x):
# print(x.shape)
o1 = self.relu(self.bn1(self.conv1(x)))
# print(o1.shape)
o2 = self.bn2(self.conv2(o1))
# print(o2.shape)
if self.conv1x1:
x = self.conv1x1(x)
out = self.relu(o2 + x)
return out
在卷积层完成特征提取后, 每张图可以得到512个7x7的feature map.做全局平均池化后得到512个feature.再传入全连接层做特征的线性组合得到num_classes个类别.
我们来实现34-layer的resnet
class ResNet(nn.Module):
def __init__(self,in_channels,num_classes):
super(ResNet,self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels,64,kernel_size=7,stride=2,padding=3),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True)
)
self.conv2 = nn.Sequential(
nn.MaxPool2d(kernel_size=3,stride=2,padding=1),
Residual(64,64),
Residual(64,64),
Residual(64,64),
)
self.conv3 = nn.Sequential(
Residual(64,128,stride=2),
Residual(128,128),
Residual(128,128),
Residual(128,128),
Residual(128,128),
)
self.conv4 = nn.Sequential(
Residual(128,256,stride=2),
Residual(256,256),
Residual(256,256),
Residual(256,256),
Residual(256,256),
Residual(256,256),
)
self.conv5 = nn.Sequential(
Residual(256,512,stride=2),
Residual(512,512),
Residual(512,512),
)
# self.avg_pool = nn.AvgPool2d(kernel_size=7)
self.avg_pool = nn.AdaptiveAvgPool2d(1) #代替AvgPool2d以适应不同size的输入
self.fc = nn.Linear(512,num_classes)
def forward(self,x):
out = self.conv1(x)
out = self.conv2(out)
out = self.conv3(out)
out = self.conv4(out)
out = self.conv5(out)
out = self.avg_pool(out)
out = out.view((x.shape[0],-1))
out = self.fc(out)
return out
接下来就还是熟悉的套路
数据加载
batch_size,num_workers=32,2
train_iter,test_iter = learntorch_utils.load_data(batch_size,num_workers,resize=48)
print('load data done,batch_size:%d' % batch_size)
模型定义
net = ResNet(1,10).cuda()
损失函数定义
l = nn.CrossEntropyLoss()
优化器定义
opt = torch.optim.Adam(net.parameters(),lr=0.01)
评估函数定义
num_epochs=5
def test():
acc_sum = 0
batch = 0
for X,y in test_iter:
X,y = X.cuda(),y.cuda()
y_hat = net(X)
acc_sum += (y_hat.argmax(dim=1) == y).float().sum().item()
batch += 1
test_acc = acc_sum/(batch*batch_size)
# print('test acc:%f' % test_acc)
return test_acc
训练
def train():
for epoch in range(num_epochs):
train_l_sum,batch,train_acc_sum=0,1,0
start = time.time()
for X,y in train_iter:
X,y = X.cuda(),y.cuda() #把tensor放到显存
y_hat = net(X) #前向传播
loss = l(y_hat,y) #计算loss,nn.CrossEntropyLoss中会有softmax的操作
opt.zero_grad()#梯度清空
loss.backward()#反向传播,求出梯度
opt.step()#根据梯度,更新参数
# 数据统计
train_l_sum += loss.item()
train_acc_sum += (y_hat.argmax(dim=1) == y).float().sum().item()
train_loss = train_l_sum/(batch*batch_size)
train_acc = train_acc_sum/(batch*batch_size)
if batch % 100 == 0: #每100个batch输出一次训练数据
print('epoch %d,batch %d,train_loss %.3f,train_acc:%.3f' % (epoch,batch,train_loss,train_acc))
if batch % 300 == 0: #每300个batch测试一次
test_acc = test()
print('epoch %d,batch %d,test_acc:%.3f' % (epoch,batch,test_acc))
batch += 1
end = time.time()
time_per_epoch = end - start
print('epoch %d,batch_size %d,train_loss %f,time %f' %
(epoch + 1,batch_size ,train_l_sum/(batch*batch_size),time_per_epoch))
test()
train()
输出如下:
load data done,batch_size:32
epoch 0,batch 100,train_loss 0.082,train_acc:0.185
epoch 0,batch 200,train_loss 0.065,train_acc:0.297
epoch 0,batch 300,train_loss 0.053,train_acc:0.411
epoch 0,batch 300,test_acc:0.684
epoch 0,batch 400,train_loss 0.046,train_acc:0.487
epoch 0,batch 500,train_loss 0.041,train_acc:0.539
epoch 0,batch 600,train_loss 0.038,train_acc:0.578
epoch 0,batch 600,test_acc:0.763
epoch 0,batch 700,train_loss 0.035,train_acc:0.604
epoch 0,batch 800,train_loss 0.033,train_acc:0.628
epoch 0,batch 900,train_loss 0.031,train_acc:0.647
epoch 0,batch 900,test_acc:0.729
epoch 0,batch 1000,train_loss 0.030,train_acc:0.661
epoch 0,batch 1100,train_loss 0.029,train_acc:0.674
epoch 0,batch 1200,train_loss 0.028,train_acc:0.686
epoch 0,batch 1200,test_acc:0.802
epoch 0,batch 1300,train_loss 0.027,train_acc:0.696

 浙公网安备 33010602011771号
浙公网安备 33010602011771号