基础(C++、计算机基础)大杂烩
1. C++内置基础类型大小
- char 1 字节
- short 2 字节
- int 4 字节
- long 4(Win VS)/8 (Linux)字节
- long long 8字节
- float 4 字节
- double 8 字节
- bool 1 字节
2. 值传参和引用传参的区别
2.1 值传递
- 形参是实参的副本;
- 对形参的修改不会影响实参。
2.2 引用传递
- 形参是实参的引用(本质是其内存地址);
- 对形参的修改会影响实参。
2.3 应用场景
2.3.1 不需要修改实参
- 值传递
- 小实参,内置基本数据类型或小型结构体。
- 引用传递
- 数组,使用 const 指针;
- 大实参,大结构、类,使用 const 指针 或 引用。
2.3.2 需要修改实参
- 内置基本数据使用指针,方便一看 func(&x) 就知道要改 x;
- 原生数组只能指针;
- 结构体用指针或引用;
- 类用引用。
2.3.3 值传参和引用传参传递效率的区别, 对于内置类型也是引用传参的效率高吗?
效率区别主要在需不需要为大量数据做副本,结合上文,不要修改实参且传递数据较小时,值传递较为高效和简单,否则用值传递是比较好的。在处理内置数据类型时,效率差别较小,根据需不需要改变实参,并保证代码的清晰易读,选择即可。
3. int最小值, 最大值的二进制表示
在 C++ 中,int 类型的最小值和最大值可以通过 std::numeric_limits 头文件获取。
点击查看代码
#include <iostream>
#include <limits>
int main() {
// 获取 int 类型的最小值和最大值
int minInt = std::numeric_limits<int>::min();
int maxInt = std::numeric_limits<int>::max();
// 输出最小值和最大值的二进制表示
std::cout << "Minimum value of int: " << minInt << " (Binary: ";
for (int i = sizeof(int) * 8 - 1; i >= 0; --i) {
std::cout << ((minInt >> i) & 1);
}
std::cout << ")" << std::endl;
std::cout << "Maximum value of int: " << maxInt << " (Binary: ";
for (int i = sizeof(int) * 8 - 1; i >= 0; --i) {
std::cout << ((maxInt >> i) & 1);
}
std::cout << ")" << std::endl;
return 0;
}

负数用补码表示,负数补码 = 原码取反(反码) + 1 后替换符号位为原码符号位。
- 最小值:int 类型的最小值为 -2147483648,二进制表示为 10000000000000000000000000000000。补码为 01111111111111111111111111111111 + 1 = 10000000000000000000000000000000,然后替换符号位为 1。因此,10000000000000000000000000000000 表示 -2147483648。
- 最大值:int 类型的最大值为 2147483647,二进制表示为 01111111111111111111111111111111。
4. 有符号整数和无符号整数的右移操作
主要区别是符号位扩展。
- 有符号整数的右移操作:
- 如果有符号整数的值为正数,则右移操作会向右移动,高位用 0 填充。
- 如果有符号整数的值为负数,则右移操作会向右移动,高位用 1 填充。
- 无符号整数的右移操作:
- 对于无符号整数,右移操作符 >> 会简单地向右移动,高位用 0 填充。
例子:无符号整数最大值, 右移一位最高位是1还是0?

4.1 移位的概念
移位是指在二进制数的表示中,将数的各个位向左或向右移动一定的位数。
移位操作分为两种:逻辑移位 和 算术移位。
- 逻辑移位(Logical Shift):
- 移动操作不考虑符号位,只是简单地将数的各个位向左或向右移动,并在移动后的空位填充 0。
- 在逻辑右移中,最高位补 0;在逻辑左移中,最低位补 0。
- 算术移位(Arithmetic Shift):
- 移动操作会考虑符号位,并且在移动后保持符号位不变,即将符号位一起移动。
- 在算术右移中,最高位保持不变,即符号位不变;在算术左移中,最低位补 0。
举例说明:
假设有一个 8 位有符号整数 11011011,表示的是一个负数。
进行逻辑右移一位和算术右移一位的结果如下:
- 逻辑右移一位:01101101,高位补 0。
- 算术右移一位:11101101,保持符号位不变。
5. 位段/位域
位段(Bit-fields)或称为位域(Bit-fields)是 C 和 C++ 中的一种特性,允许程序员在定义结构或联合体时,将变量的位分割成多个部分,并指定每个部分的位数。
- 位段的语法如下:
// 其中,type 表示位段的数据类型,fieldName 是位段的名称,width 表示该位段的位数。
struct MyStruct {
type fieldName : width;
};
- 位段的使用场景主要是为了节省内存空间,特别是在需要大量的布尔值或者需要精细控制内存布局时。例如,在嵌入式系统中,位段可以用来访问硬件寄存器的各个位。
#include <iostream>
struct Flags {
unsigned int a : 4; // 使用 4 位来存储 a
unsigned int b : 5; // 使用 5 位来存储 b
};
// 在这个示例中,Flags 结构体包含两个位段 a 和 b,分别使用 4 位和 5 位来存储。
// 通过位段,我们可以节省内存空间,并对结构体的布局进行精细控制。
int main() {
Flags flags;
flags.a = 6; // 将 a 设置为 6
flags.b = 14; // 将 b 设置为 14
std::cout << "Size of Flags: " << sizeof(Flags) << " bytes" << std::endl;
std::cout << "Value of a: " << flags.a << std::endl;
std::cout << "Value of b: " << flags.b << std::endl;
return 0;
}
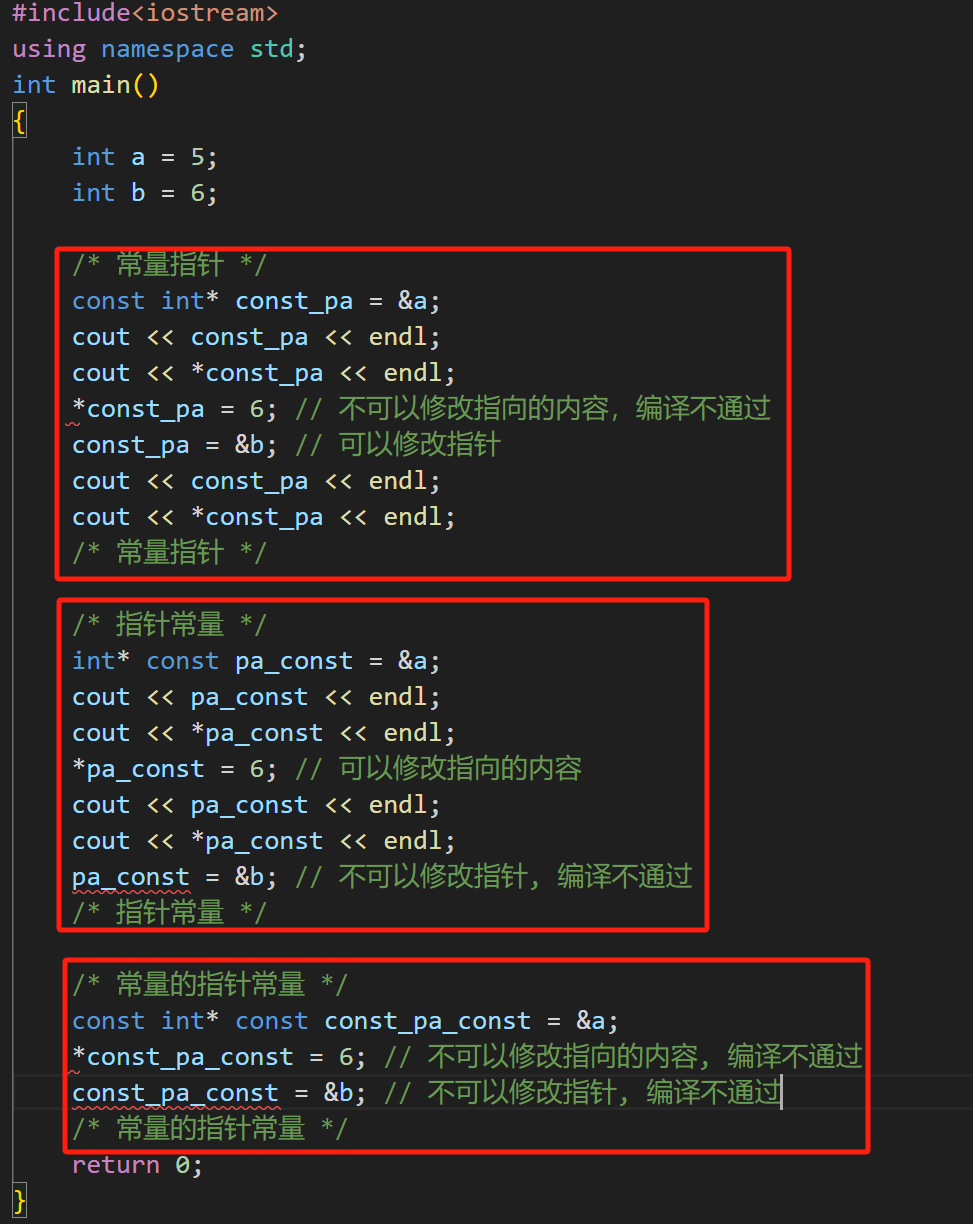
6. const 的使用
原理:编译时期的保护,可读标记,但可以利用地址修改内容。
6.1 修饰变量
使用 const 关键字声明的变量是常量,其值不能被修改。例如:
const int x = 5;
6.2 修饰指针
指针本身可以是常量,也可以指向常量。常量指针表示指针本身可修改,指向的内容不可以修改;指向常量的指针表示指针本身不可以修改,但指向的内容可修改。例如:
const int* ptr1; // 常量指针,指针本身可修改,指向的内容不可修改
int* const ptr2; // 指针常量,指针本身不可修改,指向的内容可修改
const int* const ptr3; // 指针和指向的内容都不可修改
6.3 修饰引用
使用 const 修饰的引用表示引用的对象不能被修改。例如:
int x = 5;
const int& ref = x; // ref 是对 x 的常量引用,不可修改 x 的值
6.4 修饰函数
- 类中的成员函数可以被声明为常量成员函数,这表示函数不会修改对象的成员变量。例如:
class MyClass {
public:
void myFunc() const {
// 函数体
}
};
- mutable 可以突破 const 限制,被 mutable 修饰的成员变量将永远可变。
- 非 const成员函数可以调用 const 和 非const 成员函数。
- const 成员函数 只能调用 const 成员函数。
- 非 const 对象 可以调用 const 和 非const 修饰的成员函数。
- const 对象 只能调用 const 成员函数(构造函数除外,且构造函数不能加 const)。
class MyClass {
public:
void normalFunc() { /* 函数体 */ }
void constFunc() const { /* 函数体 */ }
};
int main() {
MyClass obj1;
obj1.normalFunc(); // 可以调用非常量成员函数
const MyClass obj2;
obj2.constFunc(); // 可以调用常量成员函数
return 0;
}
6.4.1 是否可以修饰静态或全局函数?
不可以,静态成员函数访问的值为其参数, 静态成员数据和全局变量, 都不属于对象;const表示不会修改函数访问目标对象的数据成员. 静态成员函数根本不访问非静态数据成员, 没有必要使用const。
6.5 const、static型数据在内存中如何存储?(变量存放位置)
① static无论是全局变量还是局部变量都存储在全局/静态区域,在编译期就为其分配内存,在程序结束时释放。
② const 全局变量存储在只读数据段,编译期最初将其保存在符号表中,第一次使用时为其分配内存,在程序结束时释放,const 局部变量存储在栈中,代码块结束时释放。
③ 全局变量存储在全局/静态区域,在编译期为其分配内存,在程序结束时释放。
④ 局部变量存储在栈中,代码块结束时释放。
注: 当全局变量和静态局部变量未赋初值时,系统自动置为0。
7. 引用 和 指针的区别
- 语法和操作:
- 指针使用 * 和 -> 运算符来访问所指向对象的值和成员,而引用使用 . 运算符来访问对象的成员。
- 指针需要通过取地址运算符 & 来获取变量的地址,而引用则不需要,它是变量的别名。
- NULL值:
- 指针可以为空(nullptr 或 NULL),表示不指向任何有效的对象,而引用必须总是引用某个对象。
- 修改:
- 指针可以被重新赋值,指向不同的对象,而引用在创建后不能被重新绑定到另一个对象。
- 通过指针可以修改所指向对象的值,而引用本身不是对象,它只是对象的别名,因此通过引用修改的值会反映到原始对象上。
- 初始化:
- 引用必须在声明时初始化,而指针可以在声明后再进行初始化。
- 一旦引用被初始化,它将一直指向同一个对象,而指针可以在程序运行过程中指向不同的对象。
- 内存占用:
- 通常情况下,引用在内存中不会占用额外的空间,而指针需要分配内存来存储地址。
8. void* 的用法
void* 为「无类型指针」,它可以指向任意类型的指针。
- 通用指针:void* 可以作为一种通用的指针类型在函数参数中使用,或者在数据结构中使用。
- 内存分配和管理:在动态内存分配中,malloc、calloc 和 realloc 等函数返回的指针类型是 void*,因为它们不知道要分配的具体数据类型。
- 函数回调:在函数回调中,使用 void* 可以传递任意类型的数据给回调函数,通过类型转换可以在回调函数中使用这些数据。
- 跨平台开发:在涉及跨平台开发或者需要与外部库进行交互时,void* 可以提供一种通用的数据传输方式。
8.1 void* 类型是否能做算术运算?
编译器无法推导其指向的元素类型. 不安全,但可以执行算术运算, 加1移动一个字节,不建议使用。
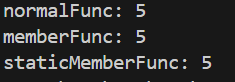
9. 普通函数指针和成员函数指针的区别
调用 普通函数 和 静态成员函数 时只需提供参数,而调用 成员函数 时需要提供对象的地址和 * 解析。
#include<iostream>
using namespace std;
class MyClass
{
public:
MyClass(){}
// 类成员函数
void memberFunc(const int x)
{
cout << "memberFunc: " << x << endl;
}
// 类静态成员函数
static void staticMemberFunc(const int x)
{
cout << "staticMemberFunc: " << x << endl;
}
};
// 普通函数
void normalFunc(const int x)
{
cout << "normalFunc: " << x << endl;
}
int main()
{
// 普通函数指针
void (*normalFuncPtr)(int) = &normalFunc;
normalFuncPtr(5);
// 类成员函数指针
void (MyClass::*memberFuncPtr)(int) = &MyClass::memberFunc; // 指定哪个类
MyClass mc;
(mc.*memberFuncPtr)(5); // 需要具体对象和 *
// 类静态成员函数指针
void (*staticMemberFuncPtr)(int) = &MyClass::staticMemberFunc;
staticMemberFuncPtr(5);
return 0;
}
10. 字节序
字节序是指在存储多字节数据类型(如整数、浮点数)时,字节的存储顺序。
主要有两种字节序:
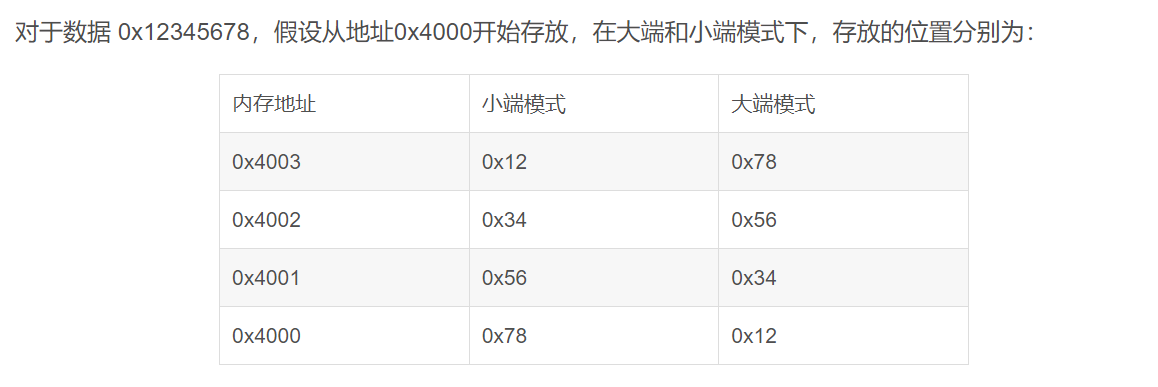
- 大端字节序(Big Endian):高位字节(Most Significant Byte,MSB)存储在低地址,低位字节(Least Significant Byte,LSB)存储在高地址。
- 小端字节序(Little Endian):低位字节(LSB)存储在低地址,高位字节(MSB)存储在高地址。
10.1 高低位 与 高低地址
- 高低位:在十进制中靠左边的是高位,靠右边的是低位,在其他进制也是如此。例如 0x12345678,从高位到低位的字节依次是0x12、0x34、0x56和0x78。
- 高低地址:

10.2 需要注意字节序的情况
- 在进行网络通信时,不同的系统可能采用不同的字节序。为了确保数据的正确传输,发送方和接收方需要对数据进行字节序的转换。
- 网络字节序 就是 大端字节序:4个字节的32 bit值以下面的次序传输,首先是0 ~ 7bit,其次8 ~ 15bit,然后16 ~ 23bit,最后是24 ~ 31bit
- 主机字节序 就是 小端字节序,现代PC大多采用小端字节序。
- 在进行文件存储时,如果文件要在不同字节序的系统上进行读取,也需要考虑字节序的问题。
- 在进行跨平台开发时,不同的系统可能采用不同的字节序,需要确保数据的正确解释和处理。
10.3 判断本机的字节序可以使用的方法
- 使用 C/C++ 中的联合体(union)进行字节序的检测。
#include<iostream>
using namespace std;
int main()
{
// 共同体使用同一内存空间,一般是同一数据不同使用场景时创建
union
{
// 输入的 4 字节(32 位)数据
uint32_t val;
// 检查的 1 字节(8 位) 数组(32 / 8 = 4 个)
uint8_t bytes[4];
} data;
// 指定数据 高位 -> 低位
data.val = 0x12345678;
// 检查低地址第 1 个字节
if (data.bytes[0] == 0x78) // 低地址放低位
cout << "Little Endian" << endl;
else if (data.bytes[0] == 0x12) // 低地址放高位
cout << "Big Endian" << endl;
return 0;
}
- 使用库函数如 htonl() 和 ntohl() 来进行字节序转换,这些函数根据本机的字节序进行适当的转换。
这两个函数在 <arpa/inet.h> 头文件中声明,可以在 POSIX 系统上使用。在 Windows 平台上,它们通常位于 <Winsock2.h> 头文件中,并带有 winsock2.h 库。
#include<iostream>
#include<Winsock2.h>
using namespace std;
int main()
{
uint32_t hostInt = 0x12345678; // 主机字节序为小端字节序 :78 开
uint32_t networkInt = htonl(hostInt); // 将主机字节序转换为网络字节序 :12 开
// nltoh(networkInt) 将网络字节序转换为主机字节序
cout << "Network Byte Order: 0x" << hex << networkInt << endl;
return 0;
}
- 在某些编译器或平台上,可能会提供预定义的宏来表示本机的字节序,例如 __ BYTE_ORDER __、_BIG_ENDIAN 和 _LITTLE_ENDIAN。
#include<iostream>
using namespace std;
int main()
{
#if __BYTE_ORDER__ == __ORDER_LITTLE_ENDIAN__
cout << "Little Endian" << endl;
#elif __BYTE_ORDER__ == __ORDER_BIG_ENDIAN__
cout << "Big Endian" << endl;
#else
cout << "Unknown Endian" << endl;
#endif
return 0;
}
11. new 、delete、 malloc、free
11.1 共同点和区别
- 共同点
- 都是在堆上申请空间,并需要用户手动释放。
- 区别
- malloc/free 是库函数,new/delete 是操作符;
- malloc 申请的空间不会初始化,new 可以初始化;
- malloc 申请时需要手动指定空间大小,new 不需要;
- malloc 返回值是 void,使用需要强转*,new 返回对象指针,不需要强转;
- malloc 申请失败返回 NULL,使用需要判空,new 不需要但需要捕获异常;
- 对自定义对象,malloc/free 只申请/释放空间,而 new/delete 申请/释放后还会调用构造/析构函数。
11.2 delete 和 delete[]的区别,delete[] 如何知道要 delete 多少次,在类的成员函数中能否 delete this?
- 基本类型,delete 和 delete[] 效果是一样的,因为系统会自动记录分配的空间,然后释放;
自定义数据类型(比如类)数组,delete 释放数组第一个元素的内存空间,仅调用了第一个对象的析构函数; delete[] 会调用数组所有元素的析构函数,并释放所有内存空间。 - new 创建数组时,会多分配 4 个字节放在数组数据空间头部,保存着数组的大小,delete[] 通过这里,对数组空间进行释放。
- 可以调用 delete this,delete this之后还可以调用该对象的成员函数(非虚函数)。原因:在类对象的内存空间中,只有数据成员和虚函数表指针,并不包含代码内容,类的成员函数单独放在代码段中。

11.3 placement new
在某些特殊情况下,可能需要在程序员指定的特定内存创建对象,这就是所谓的“定位放置new”(placement new)操作。
简单说,就是传递一个已分配内存, 在此内存上构造对象,既可以在栈上生成对象, 也可以在堆上生成对象。
定位放置new操作则使用如下语句 A* p=new (ptr) A。
#include <iostream>
using namespace std;
class A{
int num;
public:
A(){
cout<<"A's constructor"<<endl;
}
~A(){
cout<<"~A"<<endl;
}
void show(){
cout<<"num:"<<num<<endl;
}
};
int main(){
char mem[100];
mem[0]='A';
mem[1]='\0';
mem[2]='\0';
mem[3]='\0';
cout<<(void*)mem<<endl;
A* p=new (mem) A; // placementnew
cout<<p<<endl;
p->show();
p->~A();
getchar();
}
程序运行结果:
0024F924
A’s constructor
0024F924
num:65
~A
12. 内存管理
12.1 C++ 内存模型
- 栈:为函数的局部变量分配内存,能分配较小的内存。
- 堆:使用malloc、free动态分配和释放空间,能分配较大的内存。
- 全局/静态存储区:用于存储全局变量和静态变量。
- 常量存储区:专门用来存放常量。
- 代码区:机器代码指令在编译时生成的,并且在程序运行期间始终存在。代码区通常是只读的,程序不能修改其中的内容。
- 自由存储区:通过new和delete分配和释放空间的内存,具体实现可能是堆或者内存池。
12.2 堆和栈的区别
- 堆中的内存需要手动申请和手动释放,栈中内存是由OS自动申请和自动释放;
- 堆能分配的内存较大(4G(32位机器)),栈能分配的内存较小(1M);
- 在堆中分配和释放内存会产生内存碎片,栈不会产生内存碎片;
- 堆的分配效率低,栈的分配效率高;
- 堆地址从低向上,栈由高向下(符合特性,先进后出)。
12.3 内存对齐
- 内存对齐指的是C++结构体中的数据成员,其内存地址是否为其对齐字节大小的倍数。
- 对齐原则
- 1)结构体变量的首地址能够被其最宽基本类型成员的对齐值所整除;
- 2)结构体内每一个成员的相对于起始地址的偏移量能够被该变量的大小整除;
- 3)结构体总体大小能够被最宽成员大小整除;如果不满足这些条件,编译器就会进行一个填充(padding)。
- 原因:一方面可以节省内存,一方面可以提升数据读取的速度。
关键在于CPU存取数据的效率问题。为了提高效率,计算机从内存中取数据是按照一个固定长度的。比如在32位机上,CPU每次都是取32bit数据的,也就是4字节;若不进行对齐,要取出两块地址中的数据,进行掩码和移位等操作,写入目标寄存器内存,效率很低。
例子如下:
#include <iostream>
using namespace std;
struct Data
{
char c;
int numI;
double numD; // 对其单位
Data* next;
Data() : c('0'), numI(0), numD(0.f), next(nullptr) {}
};
int main()
{
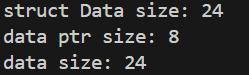
cout << "struct Data size: " << sizeof(Data) << endl; // 24
Data* data = new Data();
cout << "data ptr size: " << sizeof(data) << endl; // 8
cout << "data size: " << sizeof(*data) << endl; // 24
return 0;
}
结果:
- 如何对齐:声明数据结构时,字节对齐的数据依次声明,然后小成员组合在一起,能省去一些浪费的空间,不要把小成员参杂声明在字节对齐的数据之间。
12.3.1 什么时候不希望进行内存对齐?

# param pack(n)?
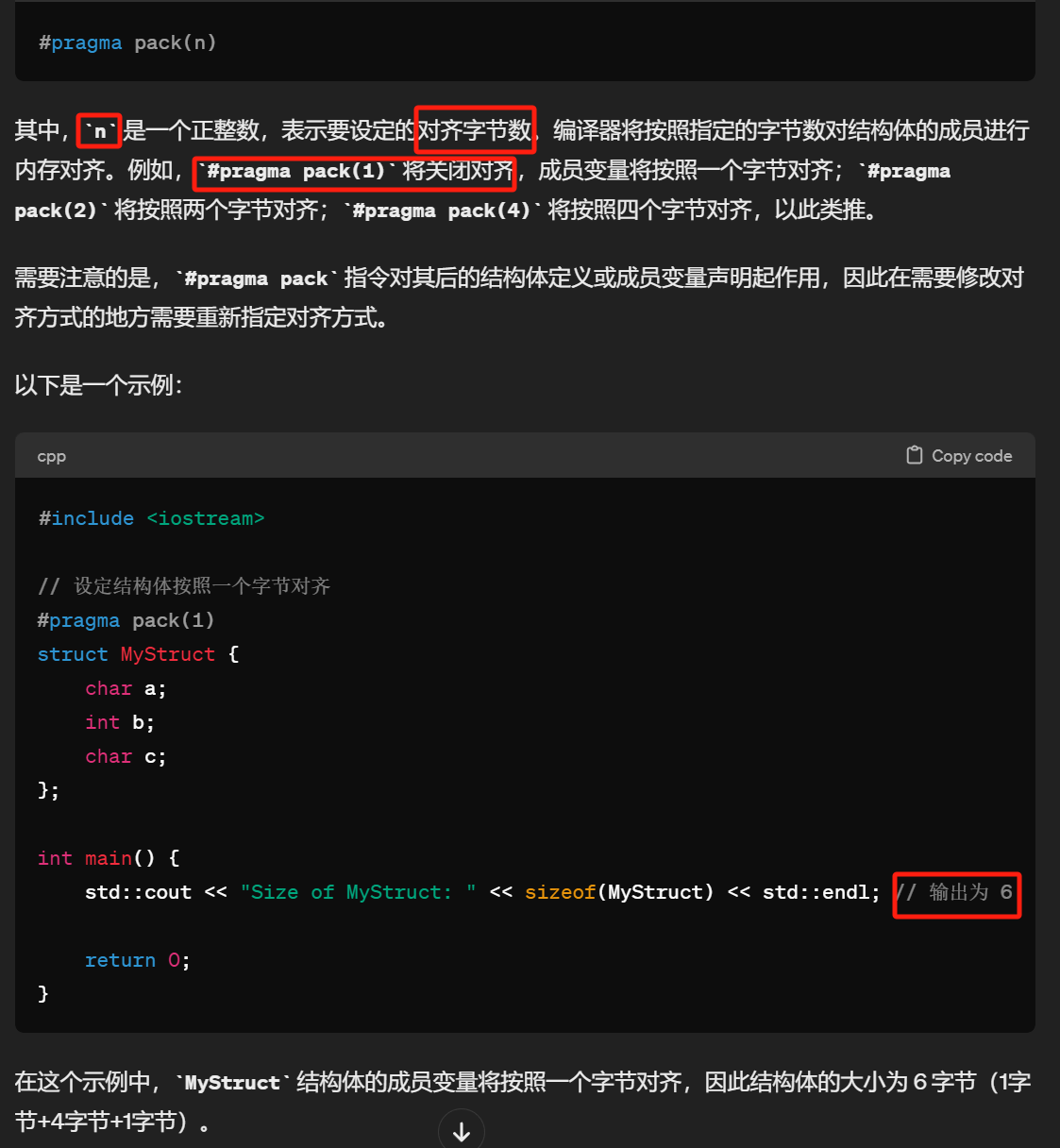
13. C++中一个空的 class 大小
1 字节,如果是空基类, 则在子类中不会增加这一个字节的空间
#include <iostream>
using namespace std;
class A
{
};
class B: public A
{
int a;
};
int main()
{
A a;
cout << sizeof(a) << endl; // 1
B b;
cout << sizeof(b) << endl; // 4
return 0;
}
14. 函数调用过程
视频讲解
查看汇编代码

- 主函数局部变量压栈;
- 函数需要调用,通过使用 EBP(帧指针,指向栈帧首地址)偏移量,从右向左实参压栈;
- call 命令,PC(程序计数器) 内返回地址压栈;
- 保存 目前 EBP 内容,并令 EBP 指向 ESP(栈指针,指向栈顶) 目前位置;
- 保存 EBX 内容,参数超过 6 个,就把之后的参数从右向左形参压栈;
- 函数局部变量压栈,执行函数体;
- 执行完函数体,依次出栈到返回地址;
- PC 取返回地址,跳转回主程序继续执行。
期间还包含各种寄存器的利用,存储结果。
15. CPP代码编译过程
- 预处理(Preprocessing): 源代码文件经过预处理器处理,包括宏展开、头文件包含等,生成预处理后的源文件。
- 编译(Compilation): 预处理后的源文件被编译成汇编代码。
- 汇编(Assembly): 汇编器将汇编代码翻译成目标机器的机器代码,生成目标文件(Object Files)。
- 链接(Linking): 将所有的目标文件以及需要的库文件链接在一起,生成可执行文件(Executable File)。
15.1 链接方式
- 静态链接(Static Linking): 在静态链接时,编译器将所有的目标文件和库文件的代码、数据等合并到最终的可执行文件中。可执行文件独立于外部的库文件,因此它比较大。在运行时,所有需要的代码和数据都已经链接在一起,程序可以直接执行,不需要额外的加载步骤。
- 动态链接(Dynamic Linking): 在动态链接时,目标文件只包含对外部库函数的引用,而不包含库函数的代码和数据。在程序运行时,操作系统将程序所需的库函数加载到内存中,并将这些库函数的地址解析到程序中,从而完成链接。动态链接可以减小可执行文件的大小,但需要依赖外部的库文件。常见的动态链接库包括DLL(在Windows上)和SO(在Unix/Linux上)。
15.2 静动的好与坏
- 静态链接的好处:
- 独立性: 静态链接生成的可执行文件独立于外部的库文件,可以在没有额外依赖的情况下在不同的环境中运行。
- 性能: 静态链接生成的可执行文件可以减少程序启动时的加载和链接时间,因为所有的代码和数据都已经链接在一起,无需动态加载和链接外部的库文件。
- 安全性: 静态链接可以防止库文件被恶意篡改,因为库文件的代码和数据已经与可执行文件合并在一起,不容易被单独修改。
- 动态链接的好处:
- 节省内存空间: 动态链接库(DLL)是共享的,即多个应用程序可以共享同一个动态链接库的代码和数据。因此,如果多个应用程序都使用了同一个库,那么它们在内存中只需要加载一份该库的代码和数据,可以节省大量内存空间。
- 简化更新和维护: 当动态链接库中的代码或数据需要更新时,只需更新动态链接库本身,而不需要重新编译和链接依赖于该库的应用程序。这样可以简化更新和维护的过程,并且可以保证所有使用该库的应用程序都能够使用最新的版本。
- 减少可执行文件的大小: 动态链接库中的代码和数据不会被包含在可执行文件中,因此可以减小可执行文件的大小。这对于需要经常更新的应用程序来说尤其有用,因为用户只需要下载更新的动态链接库,而不需要重新下载整个可执行文件。
- 更快的启动速度: 动态链接库在程序启动时并不会被完全加载到内存中,而是在需要时动态加载。因此,动态链接可以加快程序的启动速度,因为只有在需要时才会加载依赖的库文件。
- 避免版本冲突: 动态链接库可以通过版本控制机制来管理不同版本的库文件。这样可以避免不同应用程序之间的版本冲突,因为每个应用程序可以选择使用特定版本的库文件。
16. 进程与线程
16.1 两者的区别
- 进程(Process)是操作系统中的一个执行实例,拥有独立的内存空间和资源,可以包含多个线程。
- 线程(Thread)是进程内的一个执行单元,共享进程的地址空间和资源,线程之间可以并发执行,但是彼此之间的数据是共享的。
- 主要区别在于,进程拥有独立的地址空间,而线程共享进程的地址空间。因此,线程的创建、销毁和切换开销比进程小,但线程之间的数据共享需要谨慎管理,容易出现同步问题。
16.2 进程拥有多个线程会有多少函数调用栈?
每个线程都有自己的函数调用栈。函数调用栈是用来保存函数调用和返回地址的内存区域,在多线程程序中,每个线程都会有自己的函数调用栈,用于保存该线程执行过程中的函数调用和返回地址。
16.3 系统调用
系统调用(System Call)是操作系统提供给用户程序使用的一组接口,用于请求操作系统提供服务,如文件操作、进程管理、网络通信等。通过系统调用,用户程序可以向操作系统发出请求,由操作系统代为完成某些需要特权级别的操作,如访问硬件设备、分配内存等
系统调用的时候会有函数调用栈吗?它调用过去之后是用的哪个栈?
在内核态中,操作系统会在内核堆栈(Kernel Stack)上保存系统调用的上下文信息,包括调用函数的参数、返回地址等。内核堆栈是操作系统内核运行时使用的栈空间,与用户程序的栈空间是分开的。
17. 用户在输入一个网址之后所进行的流程
- 域名(DNS)解析
- 建立 TCP 连接
- 发送 HTTP 请求
- 服务器处理与返回 HTTP 响应
- 浏览器渲染,显示内容

 浙公网安备 33010602011771号
浙公网安备 33010602011771号