
Apache SeaTunnel 指南
本文是一份面向工程师的 Apache SeaTunnel 上手文档,内容覆盖:
- SeaTunnel 的定位与原理
- 架构组成
- 安装与快速上手
- 配置文件说明(含示例)
- 典型应用场景(如日志采集、数据库同步、湖仓一体场景)
Apache SeaTunnel 上手文档
1. SeaTunnel 简介与定位
Apache SeaTunnel(原名 Waterdrop)是一个 高性能、分布式的海量数据集成框架,支持批处理和流处理两种模式。它的特点是:
- 支持多种数据源与目标:JDBC、Kafka、Elasticsearch、Hive、ClickHouse、Hudi、Iceberg、Doris 等。
- 批流一体:同一套配置既能跑批也能跑实时。
- 插件化架构:Source、Transform、Sink 全部插件化,扩展方便。
- 低代码配置:通过 YAML/JSON 配置文件即可完成数据管道定义,不需要复杂编程。
可以把它理解为 Apache Flink 生态下的“ETL胶水层”,主打 数据同步 + 数据加工。
2. SeaTunnel 架构原理
SeaTunnel 的核心架构采用 Source → Transform → Sink 三段式模型:
┌─────────┐
│ Source │ 数据来源(DB、Kafka、File)
└────┬────┘
│
▼
┌─────────┐
│Transform│ 数据转换(过滤、字段映射、UDF)
└────┬────┘
│
▼
┌─────────┐
│ Sink │ 数据目标(ES、Doris、HDFS、Kafka)
└─────────┘
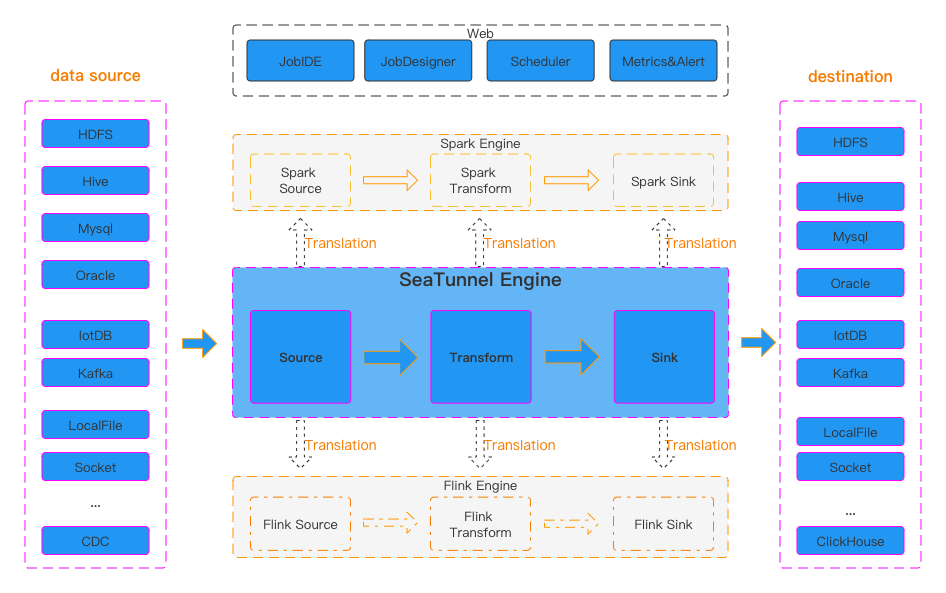
执行模式:
- Seatunnel Engine:SeaTunnel 自带的轻量执行引擎(0依赖,快速上手)。
- Flink Engine:基于 Flink 提供流批处理能力(生产推荐)。
- Spark Engine:适合批量离线处理。
一般场景:实时数仓或日志采集用 Flink Engine;离线批处理或开发测试用 Seatunnel Engine。
3. 安装与快速上手
3.1 环境准备
- Java 8/11/17
- Python 3.x(可选,部分插件需要)
- 下载 SeaTunnel 发布包
wget https://dlcdn.apache.org/seatunnel/2.3.3/apache-seatunnel-2.3.3-bin.tar.gz
tar -zxvf apache-seatunnel-2.3.3-bin.tar.gz
cd apache-seatunnel-2.3.3
3.2 快速运行一个任务
官方自带 Example,演示 读取 FakeSource → 控制台输出:
./bin/seatunnel.sh --config ./examples/seatunnel.streaming.conf.template -e seatunnel
输出类似:
+---------+----------+
| name | age |
+---------+----------+
| Alice | 25 |
| Bob | 30 |
+---------+----------+
说明 SeaTunnel Engine 已经启动并执行了一个数据管道。
4. 配置文件详解(YAML 示例)
SeaTunnel 的任务用配置文件描述,一个典型的 YAML 文件如下:
env:
execution.parallelism: 2
job.mode: BATCH # 可选:BATCH / STREAMING
checkpoint.interval: 10000
source:
- PluginName: Jdbc
driver: com.mysql.cj.jdbc.Driver
url: "jdbc:mysql://127.0.0.1:3306/test"
user: root
password: root123
query: "SELECT id, name, age FROM user"
transform:
- PluginName: Filter
fields: ["age"]
condition: "age > 18"
- PluginName: Replace
source_field: name
pattern: "Alice"
replacement: "ALICE_USER"
sink:
- PluginName: Console
parallelism: 1
配置解读:
- env:全局运行环境(并行度、批流模式、checkpoint 配置)。
- source:数据源,这里是 MySQL。
- transform:数据转换,支持 Filter、SQL、UDF 等。
- sink:输出目标,这里是控制台(生产中一般是 Hive、Kafka、ES)。
5. 典型应用场景
5.1 日志采集 → Kafka
source:
- PluginName: File
path: /var/log/nginx/access.log
format: json
sink:
- PluginName: Kafka
bootstrap.servers: "localhost:9092"
topic: "nginx_logs"
👉 将 Nginx 日志实时采集到 Kafka,用于后续实时分析。
5.2 MySQL → ClickHouse 同步
source:
- PluginName: Jdbc
url: "jdbc:mysql://127.0.0.1:3306/test"
user: root
password: root123
query: "SELECT * FROM orders"
sink:
- PluginName: Clickhouse
host: "127.0.0.1:8123"
database: "dwh"
table: "orders"
username: "default"
password: ""
👉 实现数据库间的数据同步,常见于 ODS → DWD → DWS → APP 的数仓分层。
5.3 数据湖场景(Kafka → Hudi)
source:
- PluginName: Kafka
bootstrap.servers: "localhost:9092"
topic: "user_behavior"
format: json
sink:
- PluginName: Hudi
table.path: "hdfs:///datalake/hudi/user_behavior"
table.type: "MERGE_ON_READ"
record.key.field: "user_id"
partition.path.field: "dt"
👉 将 Kafka 中的实时用户行为数据写入 Hudi 表,便于湖仓一体的实时分析。
6. 总结
Apache SeaTunnel 的优势:
- 低代码:只需配置文件即可定义 ETL 管道。
- 生态广泛:支持上百种 Connector,覆盖主流 OLTP/OLAP/流系统。
- 批流统一:同一配置文件可无缝切换批处理/流处理引擎。
它非常适合:
- 企业做 数据库同步 / 日志采集 / 数据湖写入
- 构建 实时数仓 或 跨系统数据打通
- 替代部分自研的 ETL 脚本,提升可维护性
《SeaTunnel 在企业数仓建设中的应用指南》,场景定位是:
从 MySQL → Kafka → Flink → Hive/Doris 的 全链路数仓,覆盖 ODS → DWD → DWS → APP 层。
SeaTunnel 在企业数仓建设中的应用指南
1. 场景背景
在企业大数据体系中,数仓一般分为:
- ODS(操作数据层):保留业务系统的原始数据,保证可追溯性。
- DWD(明细层):对数据进行清洗、解耦,保证一致性。
- DWS(汇总层):按主题域进行汇总,支撑指标分析。
- APP(应用层):面向报表、推荐、风控等业务。
数据链路需求:
- 业务数据库 (MySQL) → Kafka (日志采集 / 变更同步)。
- Kafka → Hive / Doris (实时数仓建模)。
- 支撑 实时大屏 / OLAP 分析 / 离线报表。
SeaTunnel 在其中的定位是:
- 数据 抽取 (Extract):从 MySQL CDC、日志系统采集数据。
- 数据 转换 (Transform):统一 schema、过滤、脱敏、格式化。
- 数据 加载 (Load):写入 Kafka、Hive、Doris、Hudi/Iceberg 等。
2. 全链路架构图
┌──────────┐
│ MySQL │ ← 业务数据(交易、用户、订单)
└─────┬────┘
│ (CDC)
┌───────▼────────┐
│ SeaTunnel │
│ Source: MySQL │
│ Sink: Kafka │
└───────┬────────┘
│
┌───────▼────────┐
│ Kafka │ ← 数据总线(解耦上下游)
└───────┬────────┘
│
┌───────▼────────┐
│ SeaTunnel │
│ Source: Kafka │
│ Sink: Hive/Doris│
└───────┬────────┘
│
┌───────▼──────────┐
│ Hive / Doris │ ← 数仓分层 (ODS/DWD/DWS/APP)
└──────────────────┘
3. 实践示例
3.1 MySQL → Kafka (数据采集)
使用 SeaTunnel CDC 插件,实时采集 MySQL 变更。
env:
execution.parallelism: 2
job.mode: STREAMING
source:
- PluginName: MySQL-CDC
hostname: 127.0.0.1
port: 3306
username: root
password: root123
database-name: ecommerce
table-name: orders
sink:
- PluginName: Kafka
bootstrap.servers: "localhost:9092"
topic: "ods_orders"
format: json
功能:
- 实时捕获
orders表的 增删改事件,写入 Kafka 的ods_orderstopic。 - 对应 ODS 层:保存原始业务数据。
3.2 Kafka → Hive (ODS → DWD 层)
将 Kafka 中的数据清洗后落地 Hive。
env:
execution.parallelism: 3
job.mode: STREAMING
source:
- PluginName: Kafka
bootstrap.servers: "localhost:9092"
topic: "ods_orders"
format: json
transform:
- PluginName: Filter
fields: ["order_id", "user_id", "amount", "create_time"]
condition: "amount > 0"
- PluginName: Replace
source_field: user_id
pattern: "(\\d{3})\\d{4}(\\d{4})"
replacement: "$1****$2" # 脱敏处理
sink:
- PluginName: Hive
metastore_uri: "thrift://localhost:9083"
database: dwd
table: dwd_orders
save_mode: append
功能:
- 从 Kafka 读取订单数据。
- 过滤掉无效订单(amount > 0)。
- 用户 ID 脱敏。
- 写入 Hive 的
dwd.dwd_orders表。
3.3 Hive → Doris (DWS/APP 层)
构建聚合层,支撑 OLAP 查询 & 大屏。
env:
execution.parallelism: 2
job.mode: BATCH
source:
- PluginName: Hive
metastore_uri: "thrift://localhost:9083"
database: dwd
table: dwd_orders
transform:
- PluginName: SQL
sql: >
SELECT user_id, COUNT(order_id) AS order_cnt, SUM(amount) AS total_amount
FROM dwd_orders
GROUP BY user_id
sink:
- PluginName: Doris
fenodes: "localhost:8030"
table: dws_user_orders
database: dws
username: root
password: ""
save_mode: overwrite
功能:
- 对订单进行 用户维度聚合。
- 将结果写入 Doris,支持 秒级查询 / 报表 / 大屏。
4. 应用价值
- 批流一体:同一份配置可以跑实时和离线,降低开发成本。
- 灵活扩展:可接入多种 OLTP/OLAP/湖仓系统。
- 插件化架构:Source/Transform/Sink 组件组合即可快速构建 ETL。
- 企业级数仓落地:ODS→DWD→DWS→APP 全链路覆盖,替代大量自研脚本。
5. 总结
SeaTunnel 在企业数仓中扮演 数据集成与加工引擎 的角色:
- 采集层:从 MySQL、日志、消息队列获取原始数据。
- 加工层:过滤、清洗、脱敏、聚合。
- 存储层:写入 Hive、Doris、Hudi/Iceberg 等,支撑实时/离线分析。
它能帮助企业快速实现 实时数仓 / 数据湖仓一体,大幅降低 ETL 开发与维护成本。
SeaTunnel 配置文件速查表
《SeaTunnel 常用插件配置速查表》,覆盖 Source、Transform、Sink 三大类。
SeaTunnel 插件配置速查表
1. env(全局配置)
env:
execution.parallelism: 4 # 并行度
job.mode: STREAMING # BATCH 或 STREAMING
checkpoint.interval: 10000 # 流任务的 checkpoint 间隔(毫秒)
pipeline.name: "demo_job" # 任务名称
2. Source 插件(数据源)
2.1 MySQL(JDBC 批量读取)
source:
- PluginName: Jdbc
driver: com.mysql.cj.jdbc.Driver
url: "jdbc:mysql://127.0.0.1:3306/test"
user: root
password: root123
query: "SELECT id, name, age FROM user"
| 字段 | 说明 |
|---|---|
driver |
JDBC 驱动类 |
url |
数据库连接 URL |
user / password |
用户名/密码 |
query |
执行的 SQL 语句 |
2.2 MySQL-CDC(实时变更采集)
source:
- PluginName: MySQL-CDC
hostname: 127.0.0.1
port: 3306
username: root
password: root123
database-name: ecommerce
table-name: orders
| 字段 | 说明 |
|---|---|
hostname / port |
MySQL 地址和端口 |
database-name |
监听的数据库 |
table-name |
监听的表 |
username / password |
账号密码 |
2.3 Kafka
source:
- PluginName: Kafka
bootstrap.servers: "localhost:9092"
topic: "ods_orders"
format: json
group.id: seatunnel_group
| 字段 | 说明 |
|---|---|
bootstrap.servers |
Kafka broker 地址 |
topic |
订阅的 Topic |
group.id |
消费组 ID |
format |
数据格式(json/csv/avro) |
2.4 File
source:
- PluginName: File
path: "/data/input/*.csv"
format: csv
| 字段 | 说明 |
|---|---|
path |
文件路径(支持通配符) |
format |
数据格式:csv / json / parquet |
3. Transform 插件(数据转换)
3.1 Filter(条件过滤)
transform:
- PluginName: Filter
fields: ["amount"]
condition: "amount > 0"
👉 保留 amount > 0 的记录。
3.2 Replace(字符串替换/脱敏)
transform:
- PluginName: Replace
source_field: user_id
pattern: "(\\d{3})\\d{4}(\\d{4})"
replacement: "$1****$2"
👉 将用户 ID 中间四位脱敏。
3.3 SQL(SQL 转换)
transform:
- PluginName: SQL
sql: >
SELECT user_id, COUNT(*) AS order_cnt
FROM orders
GROUP BY user_id
👉 直接在 Transform 中写 SQL 逻辑。
3.4 Convert(类型转换)
transform:
- PluginName: Convert
fields:
amount: DOUBLE
order_time: TIMESTAMP
👉 将 amount 转换为 DOUBLE,order_time 转换为时间类型。
4. Sink 插件(数据目标)
4.1 Console(调试用)
sink:
- PluginName: Console
parallelism: 1
👉 输出到控制台,常用于调试。
4.2 Kafka
sink:
- PluginName: Kafka
bootstrap.servers: "localhost:9092"
topic: "dwd_orders"
format: json
4.3 Hive
sink:
- PluginName: Hive
metastore_uri: "thrift://localhost:9083"
database: dwd
table: dwd_orders
save_mode: append
| 字段 | 说明 |
|---|---|
metastore_uri |
Hive Metastore 地址 |
database |
Hive 数据库 |
table |
Hive 表 |
save_mode |
append / overwrite |
4.4 Doris
sink:
- PluginName: Doris
fenodes: "127.0.0.1:8030"
database: dws
table: dws_user_orders
username: root
password: ""
save_mode: overwrite
4.5 ClickHouse
sink:
- PluginName: Clickhouse
host: "127.0.0.1:8123"
database: dwh
table: orders
username: default
password: ""
5. 总结
📌 配置套路记忆法:
- env:任务怎么跑(批流模式、并行度、容错)。
- source:数据从哪里来(MySQL、Kafka、文件…)。
- transform:数据要不要清洗、加工。
- sink:数据到哪里去(Hive、Doris、Kafka、ClickHouse…)。
这样,一个完整的 ETL 就拼接出来了。

如果这篇文章帮助到了你,你可以请作者喝一杯咖啡


 浙公网安备 33010602011771号
浙公网安备 33010602011771号