
YOLO 9000 中的WordTree细节问题
YOLO9000
VOC数据集可以检测20种对象,但实际上对象的种类非常多,只是缺少相应的用于对象检测的训练样本。YOLO2尝试利用ImageNet非常大量的分类样本,联合COCO的对象检测数据集一起训练,使得YOLO2即使没有学过很多对象的检测样本,也能检测出这些对象。
基本的思路是,如果是检测样本,训练时其Loss包括分类误差和定位误差,如果是分类样本,则Loss只包括分类误差。
1)构建WordTree
要检测更多对象,比如从原来的VOC的20种对象,扩展到ImageNet的9000种对象。简单来想的话,好像把原来输出20维的softmax改成9000维的softmax就可以了,但是,ImageNet的对象类别与COCO的对象类别不是互斥的。比如COCO对象类别有“狗”,而ImageNet细分成100多个品种的狗,狗与100多个狗的品种是包含关系,而不是互斥关系。一个Norfolk terrier同时也是dog,这样就不适合用单个softmax来做对象分类,而是要采用一种多标签分类模型。
YOLO2于是根据WordNet[5],将ImageNet和COCO中的名词对象一起构建了一个WordTree,以physical object为根节点,各名词依据相互间的关系构建树枝、树叶,节点间的连接表达了对象概念之间的蕴含关系(上位/下位关系)。
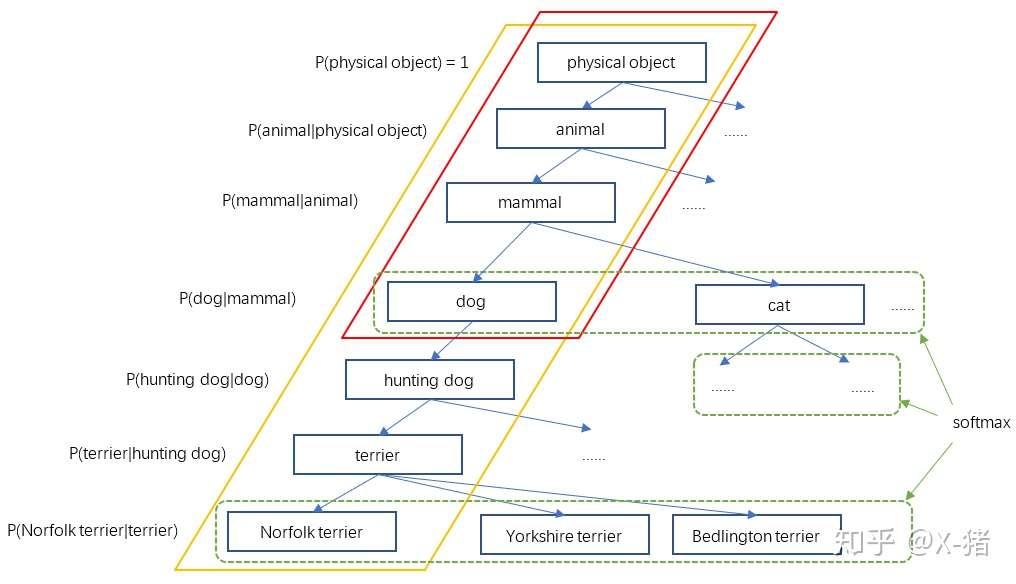 图10 WordTree
图10 WordTree
整个WordTree中的对象之间不是互斥的关系,但对于单个节点,属于它的所有子节点之间是互斥关系。比如terrier节点之下的Norfolk terrier、Yorkshire terrier、Bedlington terrier等,各品种的terrier之间是互斥的,所以计算上可以进行softmax操作。上面图10只画出了3个softmax作为示意,实际中每个节点下的所有子节点都会进行softmax。
2)WordTree的构建方法。
构建好的WordTree有9418个节点(对象类型),包括ImageNet的Top 9000个对象,COCO对象,以及ImageNet对象检测挑战数据集中的对象,以及为了添加这些对象,从WordNet路径中提取出的中间对象。
构建WordTree的步骤是:①检查每一个将用于训练和测试的ImageNet和COCO对象,在WordNet中找到对应的节点,如果该节点到WordTree根节点(physical object)的路径只有一条(大部分对象都只有一条路径),就将该路径添加到WrodTree。②经过上面操作后,剩下的是存在多条路径的对象。对每个对象,检查其额外路径长度(将其添加到已有的WordTree中所需的路径长度),选择最短的路径添加到WordTree。这样就构造好了整个WordTree。
3)WordTree如何表达对象的类别
之前对象互斥的情况下,用一个n维向量(n是预测对象的类别数)就可以表达一个对象(预测对象的那一维数值接近1,其它维数值接近0)。现在变成WordTree,如何表达一个对象呢?如果也是n维向量(这里WordTree有9418个节点(对象),即9418维向量),使预测的对象那一位为1,其它维都为0,这样的形式依然是互斥关系,这样是不合理的。合理的向量应该能够体现对象之间的蕴含关系。
比如一个样本图像,其标签是是"dog",那么显然dog节点的概率应该是1,然后,dog属于mammal,自然mammal的概率也是1,......一直沿路径向上到根节点physical object,所有经过的节点其概率都是1。参考上面图10,红色框内的节点概率都是1,其它节点概率为0。另一个样本假如标签是"Norfolk terrier",则从"Norfolk terrier"直到根节点的所有节点概率为1(图10中黄色框内的节点),其它节点概率为0。
所以,一个WordTree对应且仅对应一个对象,不过该对象节点到根节点的所有节点概率都是1,体现出对象之间的蕴含关系,而其它节点概率是0。
4)预测时如何确定一个WordTree所对应的对象
上面讲到训练时,有标签的样本对应的WordTree中,该对象节点到根节点的所有节点概率都是1,其它节点概率是0。那么用于预测时,如何根据WordTree各节点的概率值来确定其对应的对象呢?
根据训练标签的设置,其实模型学习的是各节点的条件概率。比如我们看WordTree(图10)中的一小段。假设一个样本标签是dog,那么dog=1,父节点mammal=1,同级节点cat=0,即P(dog|mammal)=1,P(cat|mammal)=0。
既然各节点预测的是条件概率,那么一个节点的绝对概率就是它到根节点路径上所有条件概率的乘积。比如
P(Norfolk terrier) = P(Norfolk terrier|terrier) * P(terrier|hunting dog) * P(hunting dog|dog) *......* P(animal|physical object) * P(physical object)
对于分类的计算,P(physical object) = 1。
不过,为了计算简便,实际中并不计算出所有节点的绝对概率。而是采用一种比较贪婪的算法。从根节点开始向下遍历,对每一个节点,在它的所有子节点中,选择概率最大的那个(一个节点下面的所有子节点是互斥的),一直向下遍历直到某个节点的子节点概率低于设定的阈值(意味着很难确定它的下一层对象到底是哪个),或达到叶子节点,那么该节点就是该WordTree对应的对象。
5)分类和检测联合训练
由于ImageNet样本比COCO多得多,所以对COCO样本会多做一些采样(oversampling),适当平衡一下样本数量,使两者样本数量比为4:1。
YOLO9000依然采用YOLO2的网络结构,不过5个先验框减少到3个先验框,以减少计算量。YOLO2的输出是13*13*5*(4+1+20),现在YOLO9000的输出是13*13*3*(4+1+9418)。假设输入是416*416*3。
由于对象分类改成WordTree的形式,相应的误差计算也需要一些调整。对一个检测样本,其分类误差只包含该标签节点以及到根节点的所有节点的误差。比如一个样本的标签是dog,那么dog往上标签都是1,但dog往下就不好设置了。因为这个dog其实必然也是某种具体的dog,假设它是一个Norfolk terrier,那么最符合实际的设置是从Norfolk terrier到根节点的标签都是1。但是因为样本没有告诉我们这是一个Norfolk terrier,只是说一个dog,那么从dog以下的标签就没法确定了。
对于分类样本,则只计算分类误差。YOLO9000总共会输出13*13*3=507个预测框(预测对象),计算它们对样本标签的预测概率,选择概率最大的那个框负责预测该样本的对象,即计算其WrodTree的误差。
另外论文中还有一句话,"We also assume that the predicted box overlaps what would be the ground truth label by at least .3 IOU and we backpropagate objectness loss based on this assumption."。感觉意思是其它那些边框,选择其中预测置信度>0.3的边框,作为分类的负样本(objectness)。即这些边框不应该有那么高的置信度来预测该样本对象。具体的就要看下代码了。
原文链接:https://zhuanlan.zhihu.com/p/47575929

如果这篇文章帮助到了你,你可以请作者喝一杯咖啡


 浙公网安备 33010602011771号
浙公网安备 33010602011771号