
YOLO v1 论文精读
YOLO的特点:使用来自整张图像的特征来预测每个bounding box
首先,将整张图分成S*S的网格,如果一个物体的中心落在某个网格中,就用该网格检测这个物体。
每个网格预测B个bounding box,以及对应的置信度。
置信度的含义:
- 模型确定这个box包含有物体的程度
- 模型认为box属于预测出来的物体的准确程度
置信度的定义:
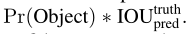
也就是,cell里边没有物体时,等于零,否则,等于IOU
每个bounding box包括五个预测值:xywh+confidence
(x, y)代表box的中心相对于网格边界的坐标
宽w和高h根据整个图像进行预测
置信度confidence代表预测框和GT之间的IOU
每个网格还预测了C个条件概率:
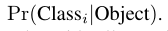
无论每个网格预测的bounding box数目B是多少,我们都只为一个网格预测一组类别概率
在test阶段,将条件概率和每个box的confidence相乘:
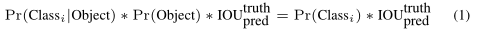
得到每个box的每个类别的置信度confidence
这个得分反映了:
- 对应类别在该box中出现的概率
- 预测的box拟合物体位置的程度

对于VOC数据集:
S=7
B=2
C=20
最终预测7*7*30 tensor(30 = 20类的条件概率+(x+y+w+h+confidence)*B)
网络设计
24卷积+2全连接

交替的1*1卷积层:减少特征空间
在ImageNet-1000类上预训练(使用一半的分辨率224*224input),在detection阶段使用448*448
网络的最终输出为7*7*30张量
Fast YOLO:
使用9卷积层而不是24,每层卷积核也更少,其他一样
训练
预训练:
使用前20个卷积层,接平均值池化,最后接全连接
训了大约一个星期,在ImageNet 2012 val set上top-5 acc是88%
训练和推断使用darknet框架
依据文献[29],向预训练网络增加卷积层和连接层可以增强performance
[29] S. Ren, K. He, R. B. Girshick, X. Zhang, and J. Sun. Object detection networks on convolutional feature maps. CoRR, abs/1504.06066, 2015. 3, 7
接下来转换模型,用于目标检测:
跟据[29],增加四个卷积层和两个全连接层(随机权重)
detection需要细粒度的视觉信息,因此把输入分辨率从224*224提高到448*448
关于bounding boxd 宽高wh:根据图像宽高,normalize to [0, 1]
关于坐标xy:参数化成相对于某一个网格的偏置,也归一到[0, 1]
结合代码理解:
关于predict_boxes的输出,我们知道predict_boxes的输出是网络前向传播后预测的候选框。固定思维让我们认为,predict_boxes的值就是类似gt_box坐标那样的(x,y,d,h)坐标。错!保持这个固有的思维,这段代码就无法看懂了,我也是不断推测的,才知道实际上道predict_boxes各个坐标的含义。
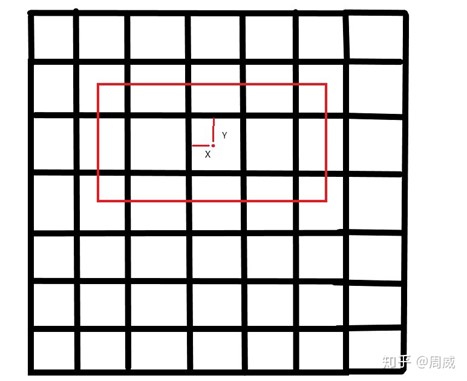
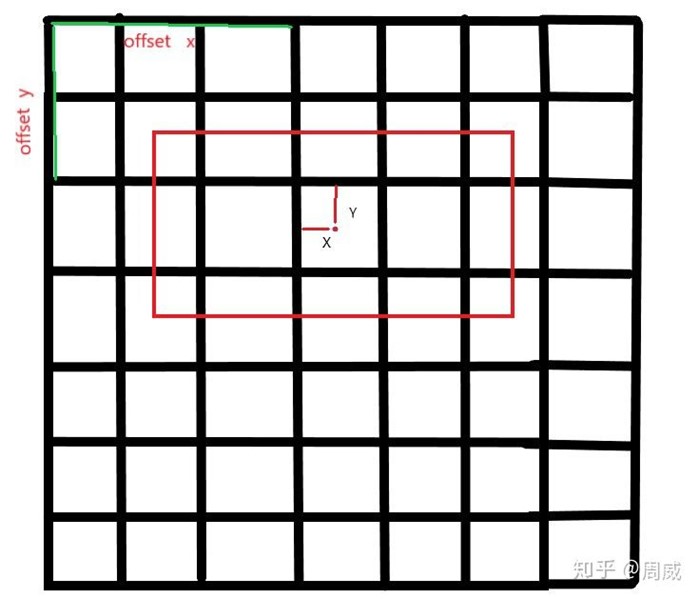
predict_boxes中心坐标真实含义
其实predict_boxes中的前两位,就是中心点坐标(x,y)代表的含义如上图,是predict_boxes中心坐标离所属格子(response)左上角的坐标。而predict_boxes中的后两位,其实并不是predict_boxes的宽度高度,而是predict_boxes的宽度高度相对于图片的大小(归一化后)的开方。
那么我们所说的输入predict中包含的坐标信息,就不是
(中心横坐标,
中心纵坐标,
宽,
高)
而是
(中心横坐标离所属方格左上角坐标的横向距离(假设每个方格宽度为1),
中心纵坐标离所属方格左上角坐标的纵向距离(假设每个方格高度为1),
宽度(归一化)的开方,
高度(归一化)的开方)
这里理解了,后面理解起来就很easy了。
注:predict_boxes部分引用自 <https://zhuanlan.zhihu.com/p/89143061>
这里注意:
对比V3,在YOLOv3实现代码里,这里是先生成一个416*416的灰色色块(R、G、B的值均为128),然后将resize之后的原图粘贴到灰色块中间
激活函数:
最后一层使用线性激活函数,其他层使用leaky RELU
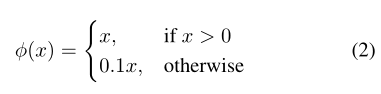
loss:
一开始使用平方和,但是:
- 平等对待位置损失和分类损失
- 大多数网格不包含检测的物体,这些网格的confidence接近于0,导致这类样本比含有物体的样本多,导致模型偏斜
解决方案1:
增加bounding box坐标产生的loss,减少不包含物体的预测结果loss
为两个loss添加权重:
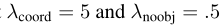
问题2:
平方和将大box和小box的error看做平等的
解决方案2:
预测bounding box的h,w的平方根,而不是直接预测bbox
loss function:
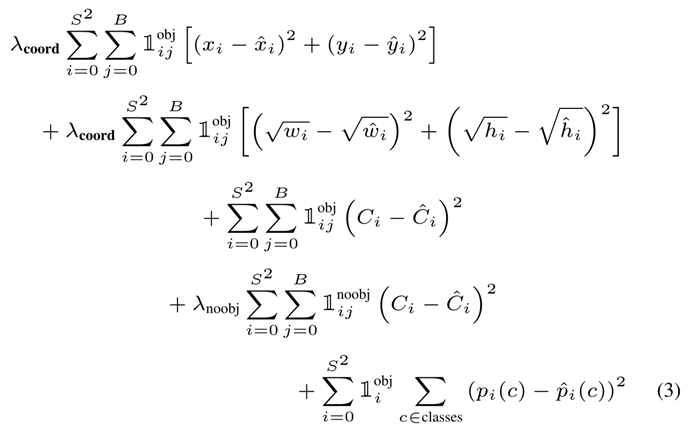
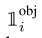 表示物体是否在网格cell_i中出现
表示物体是否在网格cell_i中出现
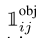 表示第i个网格(cell)中的第j个bbox与预测结果相关联
表示第i个网格(cell)中的第j个bbox与预测结果相关联
训练参数:
train:VOC2007 and VOC2012
135epoch
当在2012上test时,还训练集还包括了VOC2007test
batchsize=64
momentum=0.9
decay=0.0005
lr:

使用了droupout=0.5,在第一个全连接之后
数据增强:
随机缩放、位移、曝光、饱和度
推断
非极大值抑制
局限性
-
每个网格预测两个bbox,且只能有一个分类结果
对于成群出现的小目标,效果不好
- 对于新的/异常的长宽比或配置,效果不好
- 使用了多个下采样,只是用粗粒度特征
- loss平等对待小bbox和大bbox,主要的error来源是错误的位置

如果这篇文章帮助到了你,你可以请作者喝一杯咖啡


 浙公网安备 33010602011771号
浙公网安备 33010602011771号