
自适应特征融合(Adaptively Spatial Feature Fusion: ASFF)
来自这篇论文:<Learning Spatial Fusion for Single-Shot Object Detection>
论文地址:https://arxiv.org/pdf/1911.09516v1.pdf
代码地址:https://github.com/ruinmessi/ASFF
捕捉到题目中重点: Learning spatial fusion 即论文主要是提出一种新的自适应融合策略,实现特征在空间上的融合,在单阶段目标检测中取得了较好的效果.这种策略作者将它命名为Adaptively Spatial Feature Fusion (ASFF)
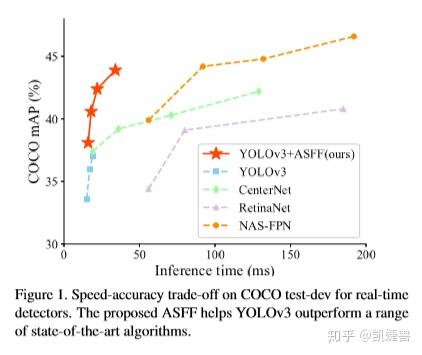
一、contribution:
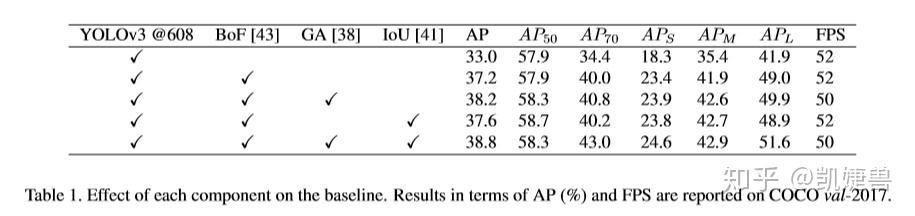
1.实现了一个更strong的baseline (将YOLOv3 从33.0%直接提升到38.8%)
作者博采众长, 利用最近在目标检测领域新涌现的各种训练trick和基于anchor的各种网络进行训练, 最终把baseline提高了5.8%, 恐怖如斯, 以下我们盘点一下作者所用到的论文及其主要思想.
a. Bag of tricks
来自于<Bag of Freebies for Training Object Detection Neural Networks>
https://arxiv.org/pdf/1902.04103.pdf
该文章提出了一种用于目标检测任务的视觉相干(visually coherent)图像混合(mixup)方法,还详细探讨了关于学习率调度、权重衰减和同步 BatchNorm等训练trick, 最终证明了其方法的有效性, 不修改网络架构、损失函数, 不增加任何推理成本,在现有模型的基础上实现了 5% 的绝对精度提升。
b.联合训练anchor free branch 和 anchor based branch
来自于<Feature Selective Anchor-Free Module for Single-Shot Object Detection>
https://arxiv.org/pdf/1903.00621.pdf
该文章作者指出在目标检测中anchor机制总是将ground truth box匹配到最接近的anchor boxes,也就是分配到了某一个特征层, 这是sub-optimal的. 所以避开anchor, 增加轻量的anchor free分支让网络去选择特征层, 使得每一个ground truth box匹配到最佳的特征层. 单独使用anchor-free分支效果与单独使用anchor-base基本持平, 只高了0.2%,组合anchor-based+anchor-free,能明显提升检测效果,AP由35.9%提升到37.2%
c.anchoring guiding机制
来自于<Region Proposal by Guided Anchoring>
https://arxiv.org/pdf/1901.03278.pdf
现阶段目标检测方法很多都使用了anchor机制, 通过预先定义好的长宽比和大小在空间位置上进行采样产生proposal。该文章作者提出了Guided Anchoring, 利用语义特征引导anchor, Guidied Anchoring 不仅预测感兴趣的object的center位置, 而且预测不同空间位置处的大小和长宽比
d.IoU loss
来自<UnitBox: An Advanced Object Detection Network>2016
https://arxiv.org/pdf/1608.01471.pdf
这是一篇比较老的文章, ASFF在原有的平滑L1 loss基础上使用了额外的IoU loss, IoU loss在UnitBox中首次被提出,并证明了其有效性
2.自适应空间特征融合
a.motivation:
用特征金字塔检测物体时, 存在一个启发性式特征选择机制, 大的intance对应高层的feature map, 小的instance对应低层的feature map. 当一个某一特征层的实例属于positive sample, 这意味着在其他特征层上相应的那部分区域将被是为背景. 这种不同level特征之间的冲突、这种不一致会干扰训练时的梯度计算,降低了特征金字塔的有效性。
(意思大概是, 在这个level的feature上instance你告诉模型它positive, 另一个level上相应的这部分却告诉模型negative, 模型风中凌乱了)
在此基础上, 作者提出了一个新颖且有效的方法, 即自适应性空间特征融合(ASFF), 以这种方法去解决在单阶段目标检测特征金字塔中存在的这种不一致问题. ASFF能够让网络去学习如何在空间上过滤其他层的无用信息, 只保留有用信息去combination.
b.advantage:
1) 搜索最优融合的操作过程是可微分的,可以方便地在反向传播中学习
2)ASFF与backbone无关,适用于所有具有特征金字塔结构的单阶段检测器
3) 实现简单,增加的计算量很小
c.Apative Fusion
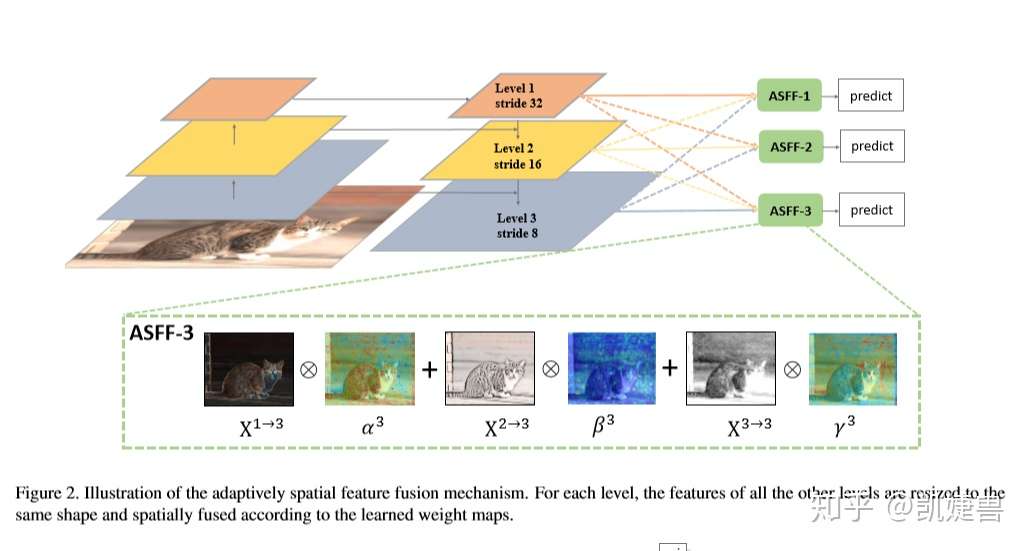
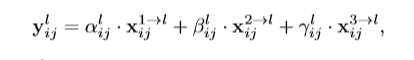 (1)
(1)
融合前需要对feature map进行resize, 例如, 如果现在要将level 1、level 2、level3融合成ASFF-1, 首先需要对level 2、level 3进行下采样, size一样了再融合. 作者就是通过上采样、下采样和池化的操作将level1,2,3变成同样size便于下步融合操作
代表从level n的特征resize到level l 后(i,j)处的特征向量
以上公式的意思就是, level1,2,3 resize后的feature map 在每个(i,j)与 各自的权重矩阵 的(i,j)处相乘再相加, 得到融合后的ASFF-L
且满足 约束条件, 这个约束条件通过
1*1卷积后得到的
再softmax来满足
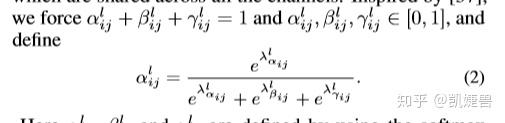
输出 就是图中的ASFF-1、ASFF-2、ASFF-3, 它们作为prediction的输入
d.consistency property
刚刚提到motivation中作者指出特征金字塔目标检测中存在不一致问题, 这部分作者给出了ASFF的一致性属性证明
在YOLOv3中, 以resize前的level 1 feature map上的(x,y)点为例, 梯度可以这样被计算: (没写 )
 (3)
(3)
因为在特征金字塔不同层的变换中我们只使用了上采样、下采样(pooling)等, 我们可以简单的将这个过程的梯度视为约等于1
即
这样我们就可以将最开始的式子化简为:
 (4)
(4)
对于在YOLOv3、RetinaNet上两种较为常见的融合操作(sum、concat), 只有element-wise sum and concatenation操作, 所以有
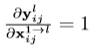
式子又可以被化简为:
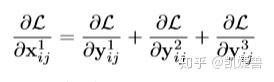 (5)
(5)
假设根据匹配机制, level 1位置(i,j)是一个object的中心, 是来自正样本的梯度。其他层对应的位置被视为背景, 所以
是来自负样本的梯度. 这种不一致性会干扰
梯度, 并降低feature map level 1的训练效率
解决这个问题的典型方法是设其他level map上相关位置为忽略区域, 即 , 这种方法虽然消除了level 1 map上的冲突, 但
之间的相关性会在一些局部最优的level上cause more inferior predictions as false positives( 如何理解?? 我的理解是会让level2 map、level3 map都变差, 没那么容易区分在哪个level上positive)
那么这个问题在ASFF上如何解决呢? 由式(1)和式(4)可得:
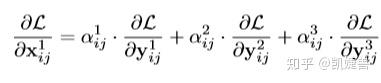 (6)
(6)
这里的 , 利用这三个系数,如果
,则可以很好地协调梯度的不一致。可以通过标准的反向传播算法学习融合参数,因此,经过这样调整的训练过程可以产生有效的系数, 与此同时
也被保留, 避免产生false positives
二、experiment results
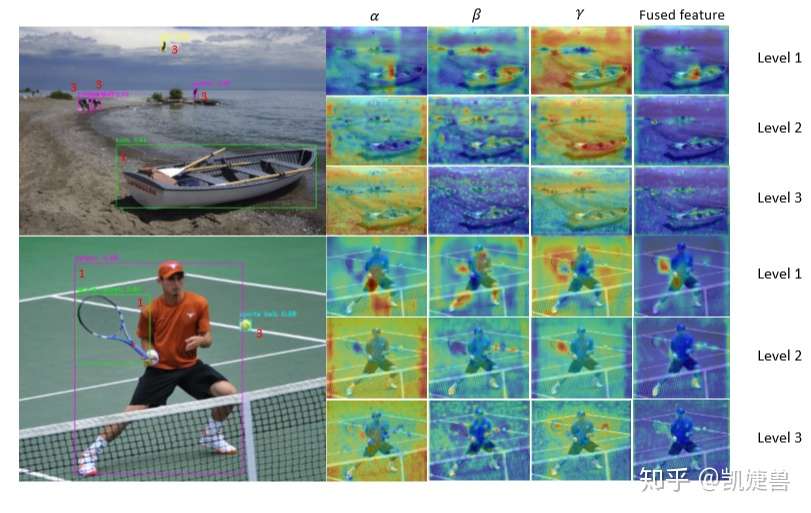
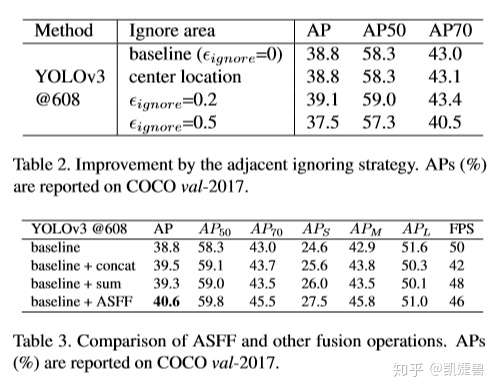
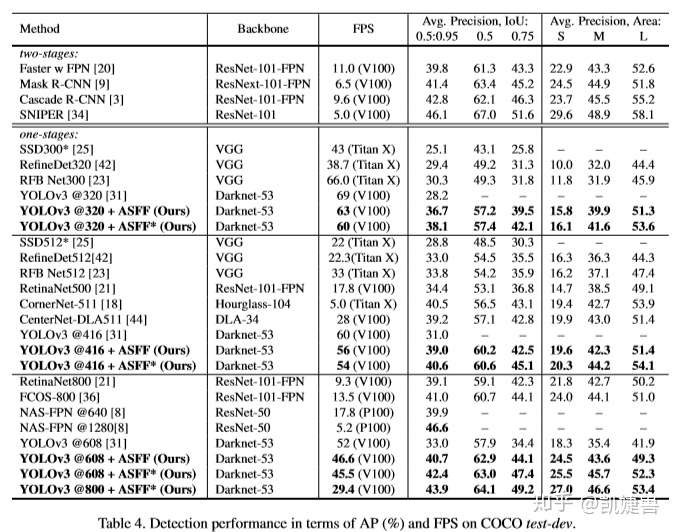
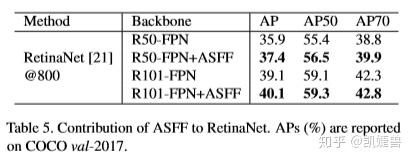
参考:
FSAF https://blog.csdn.net/diligent_321/article/details/88384588
ASFF:目标检测自适应特征融合方式
Adaptively Spatial Feature Fusion的自适应特征融合方式
在目前的目标检测算法中,为了充分利用高层特征的语义信息和底层特征的细粒度特征,采用最多也是较好的特征融合方式一般是FPN架构方式,但是无论是类似于YOLOv3还是RetinaNet他们多用concatenation或者element-wise这种直接衔接或者相加的方式,论文作者认为这样并不能充分利用不同尺度的特征。所以提出一种新的融合方式来替代concat或element-wise。

以ASFF-3为例,图中的绿色框描述了如何将特征进行融合,其中X1,X2,X3分别为来自level,level2,level3的特征,与为来自不同层的特征乘上权重参数α3,β3和γ3并相加,就能得到新的融合特征ASFF-3,如下面公式所示:
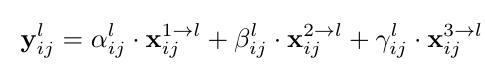
因为采用相加的方式,所以需要相加时的level1~3层输出的特征大小相同,且通道数也要相同,需要对不同层的feature做upsample或downsample并调整通道数。
对于权重参数α,β和γ,则是通过resize后的level1~level3的特征图经过1×1的卷积得到的。并且参数α,β和γ经过concat之后通过softmax使得他们的范围都在[0,1]内并且和为1:
总结,其实这种融合方式的思想在很多算法中都有体现,比如注意力模型,图像修复算法,利用权重参数来调整特征融合的贡献大小。
————————————————
版权声明:本文为CSDN博主「豆豆小朋友小笔记」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_40728805/article/details/103524193

如果这篇文章帮助到了你,你可以请作者喝一杯咖啡


 浙公网安备 33010602011771号
浙公网安备 33010602011771号