
caffe中的fine-tuning
caffe finetune两种修改网络结构prototxt方法
第一种方法:将原来的prototxt中所有的fc8改为fc8-re。(若希望修改层的学习速度比其他层更快一点,可以将lr_mult改为原来的10倍或者其他倍数)
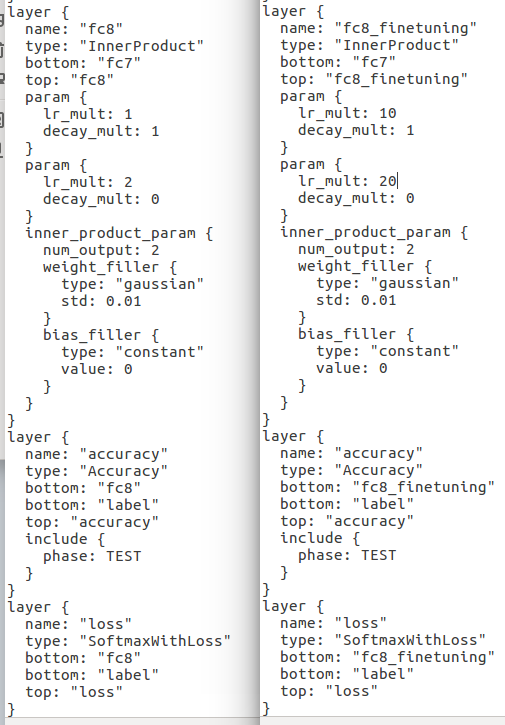
第二种方法:只修改name,如下例子所示:
layer {
name: "fc8-re" #原来为"fc8"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
inner_product_param {
num_output: 5 #原来为"1000"
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
caffe是一个深度学习框架,在建立好神经网络模型之后,使用大量的数据进行迭代调参数获取到一个拟合的深度学习模型caffemodel,使用这个模型可以实现我们需要的任务。
所谓fine tune就是用别人训练好(通常是ImageNet上1000类分类训练)的模型参数的基础上,加上我们自己的数据和具体的分类识别任务来进行特定的微调,以训练新的模型。fine tune相当于使用别人的模型的前几层,来提取浅层特征,然后在最后再落入我们自己的分类中。
fine tune的好处在于不用完全重新训练模型,从而提高效率,因为一般新训练模型准确率都会从很低的值开始慢慢上升,但是fine tune能够让我们在比较少的迭代次数之后得到一个比较好的效果。在数据量不是很大的情况下,fine tune会是一个比较好的选择。但是如果你希望定义自己的网络结构的话,就需要从头开始了。
另外,finetuning需要的计算资源相对较少,使用的trikes相对较少,难度较低,比较适合caffe新手。在finetuning过程中熟悉caffe的各种接口和操作。
finetuning的过程和训练的过程步骤大体相同,因此在finetuning的过程中可以对caffe训练过程有一个详细的了解,通过一步步的训练和finetuning,在寻找最优参数过程中加深对caffe框架的理解,为自己后续自己从头开始训练一个caffe深度网络模型打好基础。
话不多说,具体的fine-tuning流程如下:
一、准备好自己的训练数据和测试数据;
二、计算数据集的均值文件,因为数据集中特定领域的图像均值文件会跟imagenet上比较general的数据的均值不太一样;
前面两步和平时我们训练时制作自己的数据一样;
三、复制一份该model文件对应的prototxt文件进行修改,因为finetuning的过程是让原有训练好的模型适应自己的数据,因此一般情况下,网络的模型并没有大的变化。修改网络最后一层的网络名字(这样预训练模型赋值的时候就会因为名字的不同而重新训练,达到适应新任务的目的)和输出类别num_output,并且需要加快最后一层的参数学习速率(因为是最后一层要重新学习,所以将最后一层的weight和bias的lr_mult加快10倍),此外,和fc8相关的名字都要改掉;
四、调整solver文件的网络参数,通常学习数率和步长,迭代次数都要适当减少,这正式微调的本质所在;基本上就是将test_iter\base_lr\stepsize\max_iter进行相应地减小;
五、启动训练,并且需要加载pretrained模型的参数。在caffe根目录下运行: ./build/tools/caffe train -solver models/finetune_flickr_style/solver.prototxt -weights models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel -gpu 0
选取train函数,后面接具体的参数,分别为配置命令,配置文件路径,fine-tuning命令,fine-tuning依赖的基准模型文件目录,选用的训练方式:gpu或者cpu,使用cpu时可以默认不写。fine-tuning的过程与训练过程类似,只是在调用caffe接口时的命令不同,因此在fine-tuning之前,仍然需要按照训练流程准备数据:下载数据->生成trainset和testset->生成db->设置好路径->fine-tuning。这过程主要调用的是我们修改好的solver来自我们修改好的solver.prototxt文件,weights来自我们下载好的caffemodel。

如果这篇文章帮助到了你,你可以请作者喝一杯咖啡


 浙公网安备 33010602011771号
浙公网安备 33010602011771号