openpyxl学习日记1
1.处理Excel文件中的成绩数据
# 模拟生成若干同学才成绩并写入 excel学生姓名和课程都可以重复,也就是允许出现同一门课程多次成绩,最后统计 # 所有学生的每门课的最高成绩,并写入新文件 from random import choice,randint from openpyxl import Workbook,load_workbook #生成随机数据 def generateRandomInformation(filename): workbook = Workbook() worksheet = workbook.worksheets[0] worksheet.append(['姓名','课程','成绩']) first = '赵钱孙李' middle = '大的撒上' last = '发算法' subjects = ('语文','数学','英语') for i in range(200): name = choice(first) #按一定概率生成只有 2 个字的中文名字 if randint(1,100) > 50: name = name + choice(middle) name = name + choice(last) #异常生成姓名,课程,成绩 worksheet.append([name,choice(subjects),randint(0,100)]) workbook.save(filename) # 保存数据Excel2007格式文件 def getResult(oldfile,newfile): result = dict() #打开原始数据 workbook = load_workbook(oldfile) worksheet = workbook.worksheets[0] # 遍历原始数据 for row in worksheet.rows: if row[0].value == '姓名': continue #姓名,课程,成绩 name,subject,grade = map(lambda cell:cell.value,row) #获取当前姓名对应的课程和成绩,如果 result 字典中不包含,则返会空 t = result.get(name,{}) f = t.get(subject,0) if grade > f: t[subject] = grade result[name] = t workbook1 = Workbook() worksheet1 = workbook1.worksheets[0] worksheet1.append(['姓名','课程','成绩']) for name, t in result.items(): print(name,t) for subject,grade in t.items(): worksheet1.append([name,subject,grade]) workbook1.save(newfile) if __name__ == '__main__': oldfile = r'f:\test.xlsx' newfile = r'f:\result.xlsx' generateRandomInformation(oldfile) getResult(oldfile,newfile)
2.演员关系分析
# itertools() from itertools import combinations from functools import reduce import openpyxl from openpyxl import Workbook def getActors(filename): actors = dict() wb = openpyxl.load_workbook(filename) ws = wb.worksheets[0] #遍历Excel文件中的所有行 for index,row in enumerate(ws.rows): #跳过第一行的表头 if index == 0: continue #获取电影名和演员列表 filmName,actor = row[0].value, row[2].value.split(',') #遍历该电影的所有演员,统计参演电影 for a in actor: actors[a] = actors.get(a,set()) actors[a].add(filmName) return actors data = getActors('电影导演演员.xlsx') def relations(num): #参数 num 表示要查找关系最好的 num 个人 #包含全部电影名称的集合 allFilms = reduce(lambda x,y:x|y,data.values(),set()) #关系最好的 num 个演员的及其参演电影名称 combiData = combinations(data.items(),num) trueLove = max(combiData, key = lambda item:len(reduce(lambda x,y:x&y, [i[1] for i in item], allFilms))) return ('关系最好的{0}个演员是{1},' '他们共同主演的电影数量是{2}'.format(num, tuple((item[0] for item in trueLove)), len(reduce(lambda x,y:x&y, [item[1] for item in trueLove], allFilms)))) print(relations(2)) print(relations(3)) print(relations(4))

提供下载——电影导演演员.xlsx
目测还有更好的方法,后面空闲补上
3.合并多个相同表头但有纵向单元格合并的Excel文件
# 列表推导式和生成器推导式 # 1.准备具有相同的表头的Excel文件,每个文件中第一列具有不同的单元格合并方式 from os import listdir from os.path import exists import openpyxl result = 'result.xlsx' if exists(result): os.remove(result) wbResult = openpyxl.Workbook() wsResult = wbResult.worksheets[0] wsResult.append(['学院','姓名','成绩']) fns = (fn for fn in listdir() if fn.endswith('.xlsx')) #遍历当前文件中 所有 xlsx 文件, 吧除表头外的内容追加到结果问价中 for fn in fns: wb = openpyxl.load_workbook(fn) ws = wb.worksheets[0] for index, row in enumerate(ws.rows): #跳过表头 if index == 0: continue wsResult.append(list(map(lambda cell:cell.value, row))) #结果文件中所有行,前面加一个空串,方便索引 ''' 1、空格串表示只含空格的串。 2、空串表示所含字符数为0的串。 ------------ 1、空格串指由空格组成的非空串,其长度为串中空格字符的个数。 2、空串指长度为零的串。 ''' rows = [''] + list(wsResult.rows) index1 = 2 rowCount = len(rows) #处理结果文件,合并第一列中合适的单元格 while index1 < rowCount: value = rows[index1][0].value #如果当前单元格没有内容,或者与前面的内容相同,就合并 for index2 ,row2 in enumerate(rows[index1+1:],index1+1): if not (row2[0].value == None or row2[0].value == value): break else: #已经到文件尾,合并单元格 wsResult.merge_cells('A'+str(index1) + ':A'+str(index2)) break wsResult.merge_cells('A'+str(index1)+':A'+str(index2 -1)) index1 = index2 wbResult.save(result)
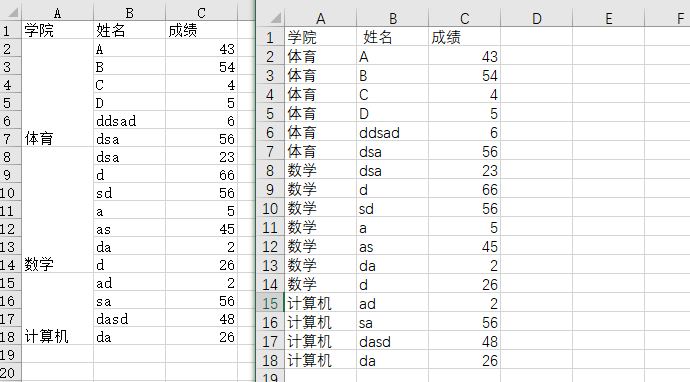
后续:这里使用的是遍历当前文件中的所有 .xlsx 文件,后续增添样式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号