OO2022第一单元作业总结
OO2022第一单元作业总结
第一次作业
UML类图
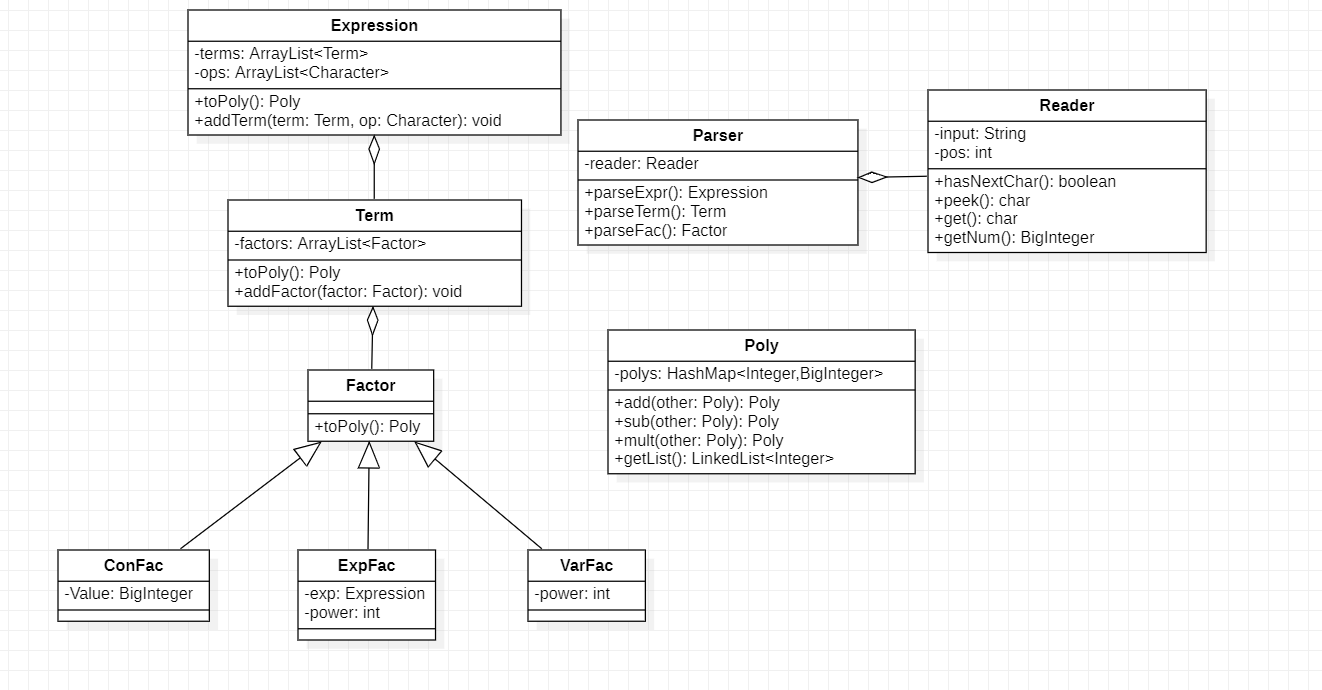
设计思路
架构设计
第一次作业主要要求完成的是对多项式展开括号,我的实现思路是针对每一种类型,建立表达式类,项类以及因子的抽象类,对于不同因子建立常数因子,幂函数以及表达式因子类去继承抽象因子类。其中表达式用ArrayList容器储存其中项,项也用ArrayList容器来储存因子,而表达式因子内部又管理了一个表达式,形成了层次结构。
解析方法
第一次作业我主要采用的是递归下降方法来解析表达式的,由于我第一次接触这种方法,并且没有想清楚对于类似表达式最前可有可没有的加减号如何处理,因此对字符串进行了预处理,比如将空格全去掉,将连续的加减化为一个再进行解析。
展开逻辑
第一次作业由于只有多项式存在,因此我又实现了一个多项式类,其中实现了加法、乘法等运算。将所有的表达式、项、因子等展开的结果均转化为多项式,这样做实现起来比较简单,不易错,但是一旦遇到不能化为多项式的因子,这种方法便难以扩展,也为我第二次作业重构埋下伏笔。
优化逻辑
合并同类项
我主要是在多项式类内部用HashMap存储幂,用指数作为键,系数作为值,这样相同指数的幂就可以合并起来。
输出优化
由于我最终将表达式转化为了多项式,因此只需要对多项式实现toString方法,其中可以优化的点比如说将正项提到前面,我是重新开了一个LinkedList,遍历一遍多项式,将系数为正的项插入到链表最前。还有一些优化点比如x**2转化为x*x等,我是利用特判输出的。
度量分析
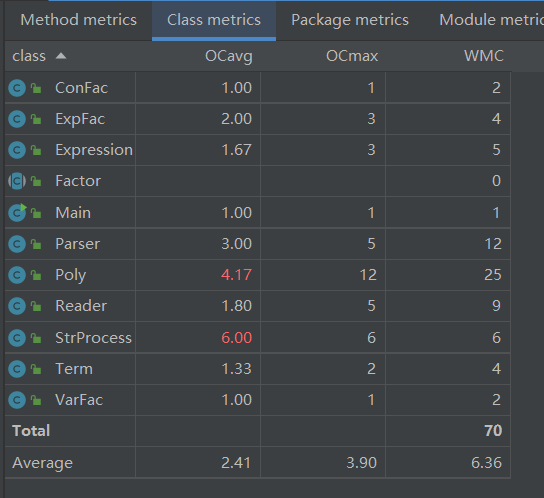
类复杂度
方法复杂度
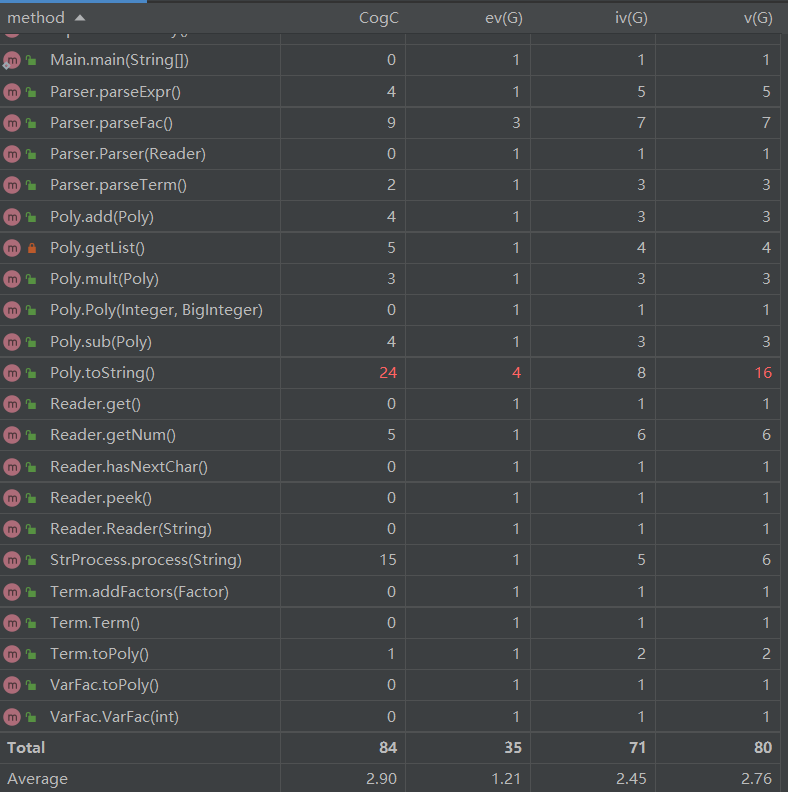
可以看出第一次作业中的主要复杂度还是在多项式类的输出方面,由于为了优化写了许多特判,因此复杂度较高。由于展开化为多项式后整体处理比较简单,因此其他的类与方法的复杂度不是很高。
测试与Bug
我测试的方法主要是利用Python的Xeger模块根据正则表达式生成随机数据,测试数据的构造基本也是按照层次结构递归构造的,也设定了最多的括号嵌套数量。然后利用Python的subprocess进行输入输出,利用sympy进行正确性的验证,由于sympy好像不能解析带前缀0的数,因此还对数据预处理了一下。
我第一次作业在强测和互测中未被找到Bug,互测阶段用自己的评测机找到了两个同学的Bug,一个同学的正则表达式写错了,导致在遇到空格时无法解析多个空格相连的情况。另一个同学则是在遇到指数是0的时候会有问题,具体原因不明。
架构设计体验
第一次作业的整体架构我个人感觉还可以,这种层次化的架构在后续的作业中也有所沿用。优点是就当前的需求来说,实现的比较简洁不易错。主要的问题就是将所有的式子均转化为多项式的做法难以扩展,在遇到三角函数后就不行了,并且在表达式存储项时还多开了个ArrayList记录项的正负,较为复杂易错,后续进行了改进。
第二次作业
UML类图

其中一些比较核心的方法有expand()用于展开括号,返回一个表达式。simplify()用于合并同类型。substitute()方法传入函数名和自定义函数定义对应的HashMap,用于从表达式开始递归,找到自定义函数调用,找到后再调用subsVar()方法,建立实参与形参的对应,对函数表达式进行递归带入。transfrom()方法用于展开求和函数是,对i的每一个取值进行带入。
设计思路
架构设计
第二次作业增加了三角函数、自定义函数和求和函数。我对于原先的部分基本沿用了之前的架构,在表达式和项中用ArrayList存储其下一层次的数据。将原先的因子抽象类改成了接口。对于三角函数,新建立了Sin和Cos因子,管理指数和内部的因子。对于求和函数,我新建了一个SumFac类管理上下限以及内部的因子,还建立了一个IFac类,专门解析含有i的幂函数。对于自定义函数部分,我扩展了原先的幂函数PowFac,使其多管理了String类型的函数自变量。建立了自定义函数定义类CusFunctDef,其管理一个形参的HashMap,以及管理函数表达式。还建立了自定义函数调用因子类CusFunctFac,管理函数名以及实参的HashMap。所有式子还都实现了Copyable接口,从而可以递归copy实现深拷贝。
解析方法
第二次作业的解析还是利用了递归下降法,基本沿用了第一次作业的代码。不过进行了一些改进,解决了第一次作业中提到的问题,从而不再需要预处理。对于表达式前可能的正负号,我的策略是解析表达式开头遇到正负号就当做是表达式的进行解析,因为这样做一定能符合文法,不会有副作用,而如果当做是项的则可能导致本来符合文法的字符串被解析为非法了。对于空格也是按照文法,如果有就进行读入。另外对于解析出来的项前面是负号,就向项中加入一个-1的因子,这样就能保证表达式中所有项都是相加的,处理更加简单。
对于三角函数和求和函数基本也是利用递归下降的方法解析即可。对于自定义函数的解析,也基本采用递归下降,不过我在最外面开了一个HashMap用来存储函数名和函数定义类的对应用于后续调用的替换和展开。
展开逻辑
我的展开是对每一种类都实现了expand方法,并实现了表达式间的加和乘以及项之间的乘。每一层的expand均递归调用下一层的expand方法,所有的expand的方法的返回值均是一个表达式,项将每个因子展开后的表达式相乘返回一个表达式,表达式则将每个项展开后的表达式相加返回一个新的表达式。
在展开之前首先进行的是自定义函数调用的替换,我实现了substitute方法,将之前存储函数名和定义类的HashMap传入,逐层递归进行寻找,一旦遇到函数调用因子,就建立起形参与实参对应的HashMap,再调用subsVar方法,对其内部的函数表达式逐层递归替换,一旦遇到含有形参的幂函数,就将实参带入进去,返回一个表达式因子。最终实现将自定义函数替换。
对于求和函数的替换我是在expand方法内实现的,当遇到需要展开的求和函数,就对每一种i的取值,对求和表达式进行带入,也是逐层递归,当遇见IFac因子是,就带入i的取值生成表达式因子。最终对每一种i的取值都带入生成一个新的表达式相加,最终返回一个表达式。
优化逻辑
合并同类项
我优化的方法是采用再开一个HashMap的方法,我重写了每个类的equals和hashcode,对于项的合并,将因子的幂提取出来作为值来合并,对于表达式的合并,将项的系数提取出来进行合并。但是由于我是采用ArrayList来存储项和因子的,合并时需要先提取出来系数和指数,合并后再还回去,导致我写的非常麻烦还易错。
三角函数内提取负号
主要就是判断如果三角函数内是负的话就将负号消掉或者提到外面,不过易错点就是有关sin因子次方是偶数的情况。
Sin(0)及Cos(0)化简
对于这种特殊值的化简我是在调用expand()方法时特判的,如果三角函数内因子是0,就直接变换常数因子加到项和表达式中。
三角函数平方合并
本次作业我没有做三角函数平方的合并,由于我本身的架构设计的不好,导致我在做的优化时感到比较困难,并且为了保证正确性,后来就放弃了。
度量分析
类复杂度

方法复杂度
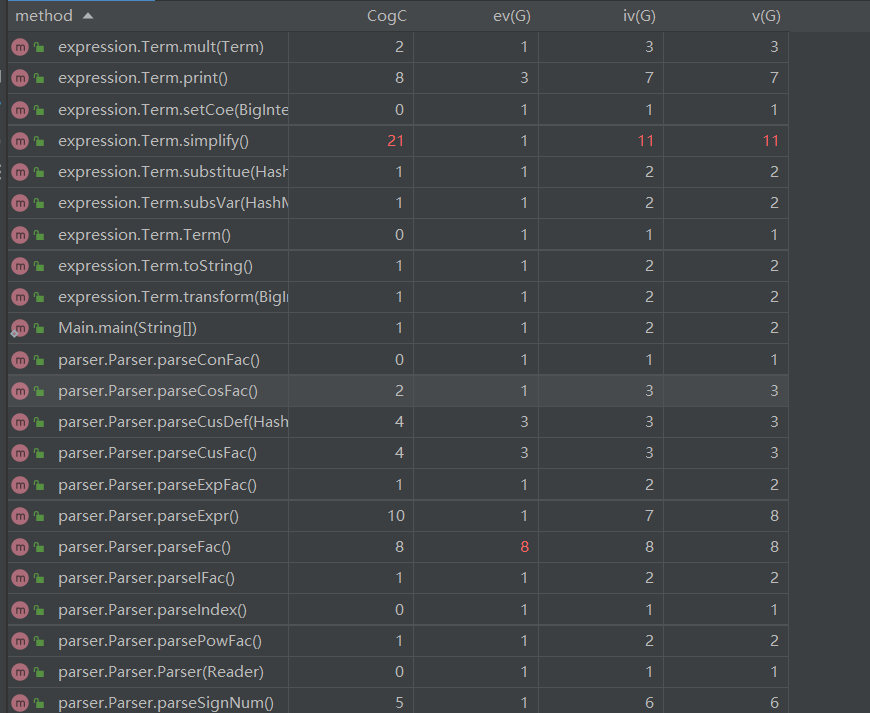
由于方法复杂度较长,我截取了其中红色最多的方法,还有少量方法有一项是红色。本次设计中类复杂度较高的是表达式、项、以及解析类。方法复杂度最高的是项内进行因子合并的方法。由于需要每次从因子中提取幂,用HashMap合并,因而比较复杂。在实际写的过程中,确实这部分比较复杂易错。
测试与Bug
本次作业我在互测和强测阶段未被发现bug。测试方法主要还是通过自己写的评测机来随机测试。对于自定义函数和求和函数,由于sympy没法解析,因此我只能手动测试。在互测阶段,我找到了四个同学的Bug,其中三个同学都是类似sin(-1)**2提取负号时出现错误,还有一个同学有的数据输出不合法,具体原因不明。
架构设计体验
本次作业我感觉我的架构设计的并不好,主要原因还是在于我利用了ArrayList来存储,导致我化简后的结果并不能很好的保存起来,每次化简还需要重新提取系数和幂,还有由于ArrayList的hashcode计算和equals判断和其中元素的顺序有关,导致我在项的合并时可能会出现因为其中因子顺序不同而不能合并的情况。而且我也没有做三角函数平方的合并,因此本次作业优化方面失分较多,这也使得我在第三次作业改进存储的容器。
不过我感觉我设计的优点是对于字符串解析和自定义函数、求和函数的处理较好,后续第三次作业基本没怎么改动,扩展性较强。
第三次作业
UML类图
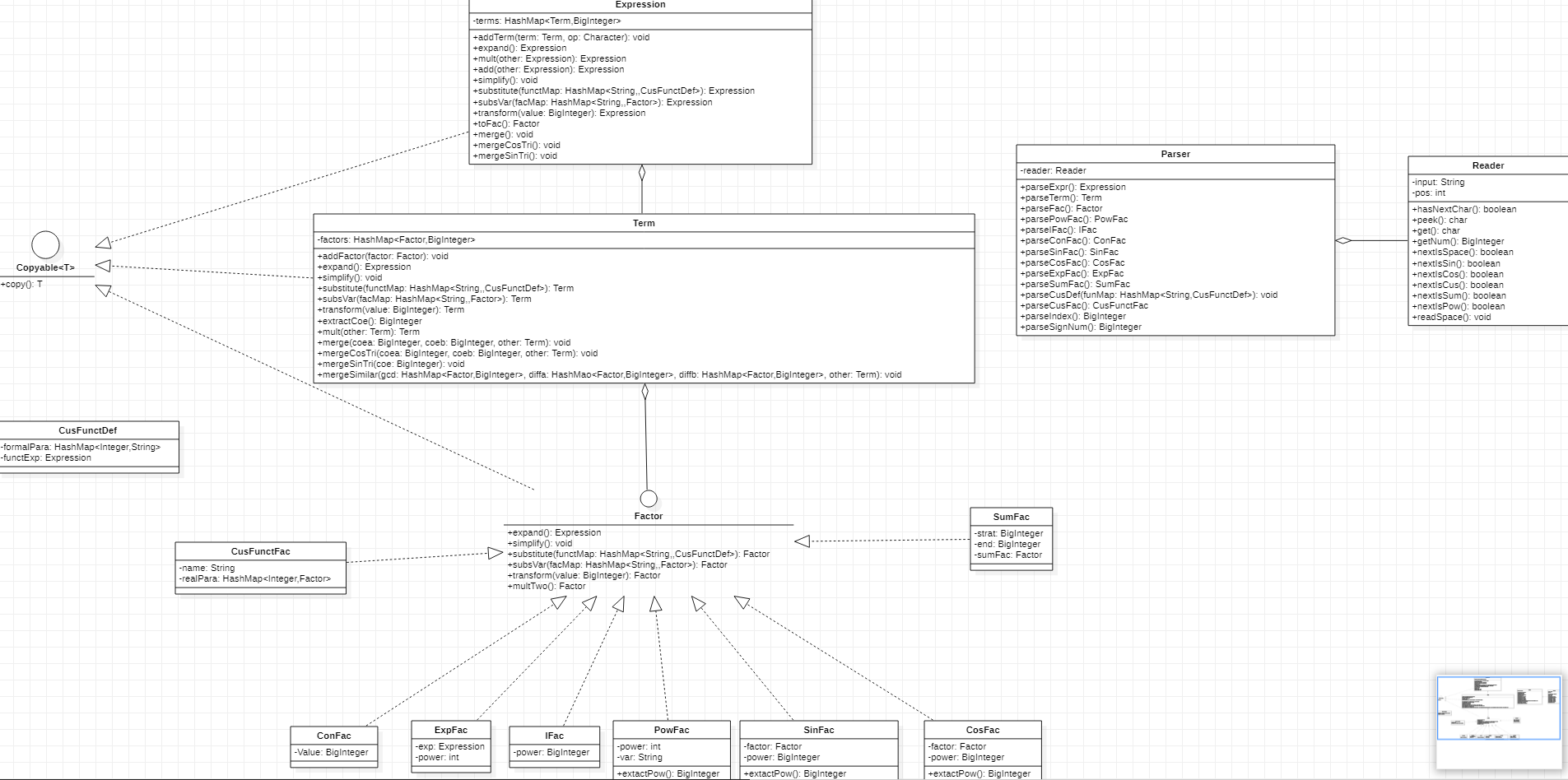
本次作业新增的一些核心方法是merge()用于三角函数平方合并,mergeCos()和mergeSin()用于二倍角的合并,Term中的mergeSimilar()用于对两个项提取公因式,gcd存储公因式,diffa和diffb存储剩下不同的因子,Factor的multTwo()方法用于二倍角合并时对内部的因子乘二。
设计思路
架构设计
我对第二次较差的架构设计,在表达式中采用HashMap来存储项,其中项作为键,系数作为值,这样在合并同类项化简后结果可以直接保存起来,不必将合并后的系数在放回项中,从而后续三角化简时也更加容易。项内也同样采用HashMap来存储因子,因子作为键,指数作为值。其余的架构基本没变。
展开逻辑
本次作业主要增加的是三角函数的嵌套和自定义函数的嵌套,我基本的展开逻辑不变,只需要递归的先将内部的因子展开或代换后再进行自身的展开和替换即可。
优化逻辑
合并同类项
合并同类项的方法与之前大致相同,由于表达式和项内部改成了HashMap,就不会出现第二次作业有时合并失败的情况。
三角函数平方合并
针对类似A*sin(B)**2+A*cos(B)**2的情况我是采用暴力的做法,二重循环对表达式遍历,找到两个项,提取出两个项的最大公因式,然后看两个项剩下的不同的因子是否是三角函数,幂为2以及内部的因子相同,如果符合条件就合并。对于类似A-A*sin(B)**2也可以用相同的做法。
二倍角合并
cos函数二倍角的合并与平方的合并差不多,如果系数是相反数的话就合并。sin函数的合并则是也是采用暴力的做法,对项二重循环遍历,碰到有sin(A)**P和cos(A)**P因子以及系数是2**P的倍数时就合并。
三角函数内拆括号
这个优化我在第二次作业展开时就基本做了,由于我展开后返回的都是表达式。因此三角函数内的因子展开后的表达式需要重新包装成因子,如果展开的表达式就是包含的单个的因子,就将因子提出来,否则就需要包装成表达式因子。
度量分析
类复杂度

方法复杂度

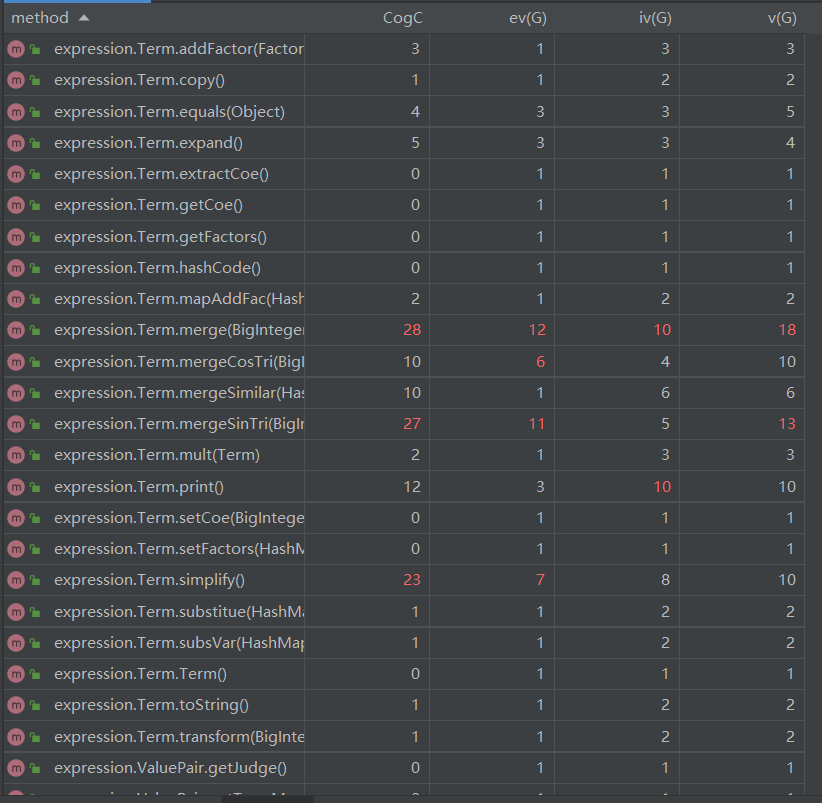
由于方法比较多,还是截取了其中红色较多的部分。本次作业复杂度较高的类还是表达式、项和解析类。复杂度较高的方法基本均是与优化有关的方法。其中很多优化都是暴力做法,确实比较复杂,代码行数也比较多,还有很多方法间调用,目前也没有想到比较好的方法去简化优化的过程。
测试与Bug
本次作业在强测和互测阶段未被发现bug。第三次作业的测试我还是沿用了之前的随机测试方法,增加了三角函数内的嵌套。求和函数和自定义函数还是只能采用手动测试的方法。后来为了测试优化的正确性,除了手动构造一些数据外,在随机生成的数据中增加了三角函数内因子相同的可能性,以及将指数尽量搞成偶数来测试,不过最后可能不是非常有效。
在互测阶段我找到了两个同学的bug,也是通过自己写的评测机来测的。其中一个同学还是sin(-1)**2的问题,另一个同学是遇到类似sin(0)**0时会输出0。
架构设计体验
本次作业的架构相比于前一次的架构有所提高,在合并同类项时更加容易,并且结果也可以保留下来,减少了一些冗余的操作,也降低了错误的可能性,优化得分也比前一次有较大提升。不过我写三角优化的方法的复杂度较高,有的方法的行数甚至超过了60行,而且时间复杂度也比较高,也许可以更加改进。对于新增的三角函数和自定义函数的嵌套,我感觉我设计的比较好,仅添加了几行就满足了功能。
第一单元收获与心得
在第一单元的作业中我还是收获了很多的。初步的接触到了面向对象的设计与思想,相比于面向过程的编程,面向对象处理这种复杂程序更有效,将复杂度分摊到各个类和方法中。同时也学习了利用python编写简单的自动评测程序,也感受到了测试的重要性,本单元能没被找到bug,很大程度上依赖了评测机。如果仅仅是通过人工来构造数据,很难构造出那么多的数据,以及覆盖所有情况。通过本单元的作业,也对于Java引用可能造成的bug有了更多的了解,以及对容器的使用也更加熟练了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号