第九章:方法区
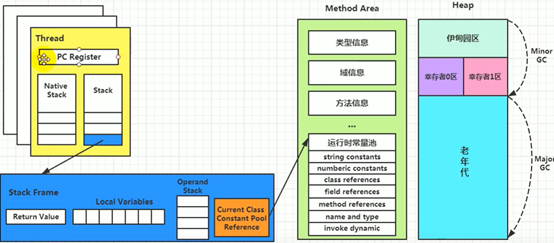
堆、栈、方法区的交互关系
运行时数据区结构图
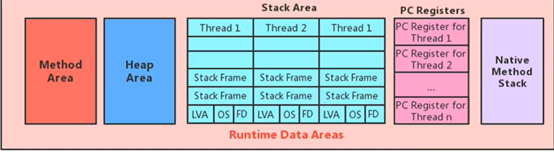
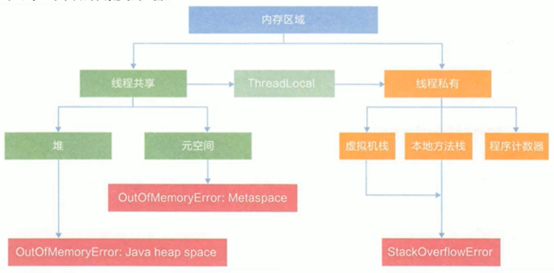
从线程共享与否的角度来看
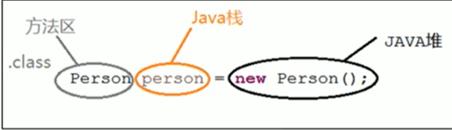
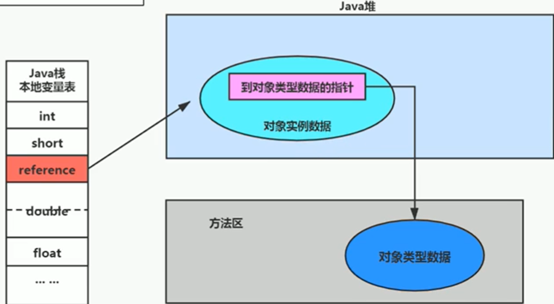
所谓对象类型数据,就如上图中的Person这个类。
方法区的基本理解
《Java虚拟机规范》中明确说明:“尽管所有的方法区在逻辑上是属于堆的一部分,但一些简单的实现可能不会选择去进行垃圾收集或者进行压缩”。
对于Hotspot JVM 而言,方法区还有一个别名叫做Non-Heap(非堆),就是为了要和堆区分开。
方法区看做是一块独立于Java堆的内存空间。
方法区(Method Area)与java堆一样,是各个线程共享的内存区域。
方法区在JVM启动的时候被创建,并且它的实际的物理内存空间中和Java堆区一样都可以是不连续的。
方法区的大小,和堆空间一样,可以选择固定大小或者可扩展。
方法区的大小决定了系统可以存储多少个类,如果系统定义了太多的类,导致方法区溢出,虚拟机同样会抛出内存溢出错误:java.lang.OutOfMemoryError:PermGen Space或者Java.lang.OutOfMemoryError:MetaSpace
比如加载大量的第三方的jar包:Tomcat部署的工程过多(30-50个):大量动态的生成反射类
关闭JVM就会释放这个区域的内存。
Hotspot中方法区的演进
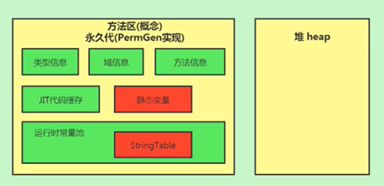
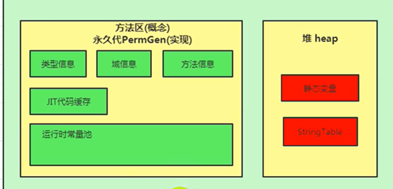
在jdk7以前,习惯上把方法区称为永久代,jdk8以后,使用元空间取代了永久代。
本质上讲, 方法区和永久代并不等价。
仅对Hotspot而言,他俩是等价的。因为《Java虚拟机规范》中对如何实现方法区不做要求。
元空间的本质和永久代类似,都是对JVM规范中方法区的实现。
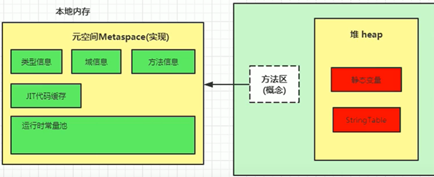
元空间和永久代最大的区别在于:元空间不在虚拟机中设置的内存中,而是使用本地内存。
此外,内部结构也调整了。
设置方法区大小的参数
Java方法区的大小不是固定的,jvm可以根据应用的需要来动态的设置。
JDK 7以前:
通过-XX:PermSize来设置永久代初始分配空间。默认值是20.75M
通过-XX:MaxPermSize来设定永久代最大可分配空间。32位机器默认是64M,64位机器默认是82M。
当jvm加载的信息容量超过了这个值,就会报OutOfMemoryError: PermGenspace
JDK 8以后:
上面两个参数被MetaspaceSize和MaxMetaspaceSize取代了。
这两个参数的默认值依赖于平台。在windows下,-XX:MetaspaceSize是21M,-XX:MaxMetaspaceSize的值是-1,即没有限制。
与永久代不同,如果不指定大小,默认情况下,虚拟机会耗尽所有的可用系统内存,如果元数据区发生溢出,虚拟机一样会抛出异常OutOfMemoryError:Metaspace
-XX:MetaspaceSize:设置元空间的初始大小。对于一个64位的服务器端JVM来说,其默认的-XX:MetaspaceSize值为21MB。该值称为初始的高水位线(起的名字叫“高水位线”),一旦触及这个水位线,Full GC将会被触发并卸载没用的类,然后重置该高水位线值。
新的高水位线的值取决于GC后释放了多少内存空间。如果释放的空间不足,那么在不超过MaxMetaspaceSize时,适当提高该值;如果释放的空间过多,则适当降低该值。
如果初始化的高水位线值设置过低,上述高水位线调整情况会发生很多次。通过垃圾回收器的日志可以观察到Full GC多次调用。为了避免频繁Full GC,建议将-XX:MetaspaceSize设置为一个相对较高的值。
OOM:PermGen和OOM:Metaspace举例
public class OOMTest extends ClassLoader {
public static void main(String[] args) {
int j = 0;
try {
OOMTest test = new OOMTest();
for (int i = 0; i < 10000; i++) {
//创建ClassWriter对象,用于生成类的二进制字节码
ClassWriter classWriter = new ClassWriter(0);
//指明版本号,修饰符,类名,包名,父类,接口
classWriter.visit(Opcodes.V1_6, Opcodes.ACC_PUBLIC, "Class" + i, null, "java/lang/Object", null);
//返回byte[]
byte[] code = classWriter.toByteArray();
//类的加载
test.defineClass("Class" + i, code, 0, code.length);//Class对象
j++;
}
} finally {
System.out.println(j);
}
}
}
- jdk6/7中:
- -XX:PermSize=10m -XX:MaxPermSize=10m
- jdk8中:
- -XX:MetaspaceSize=10m -XX:MaxMetaspaceSize=10m

如何解决OOM:
① 一般的手段是通过内存映像分析工具(如Eclipse Memory Analyzer)对dump出来的堆转储快照进行分析,重点是确认内存中的对象是否是必要的,也就是要分析清楚到底是出现了内存泄漏(Memory Leak)还是内存溢出(Memory Overflow)。
② 如果是内存泄漏,可进一步通过工具查看泄漏对象到GC Roots的引用链,于是就能找到泄漏对象是通过怎么的路径与GC Roots相关联并导致垃圾收集齐无法自动回收它们的。掌握了泄漏对象的类型信息,以及GC Roots引用链的信息,就可以比较准确地定位出泄漏代码的位置。
③ 如果不存在内存泄漏(即发生了内存溢出),即内存中的对象确实还都存活着,就应当检查虚拟机的堆参数(-Xmx与-Xms)与机器物理内存对比看是否还可以增大,从代码上检查是否存在某些对象生命周期过长、持有状态时间过长的情况,尝试减少程序运行期的内存消耗。
方法区的内部结构1
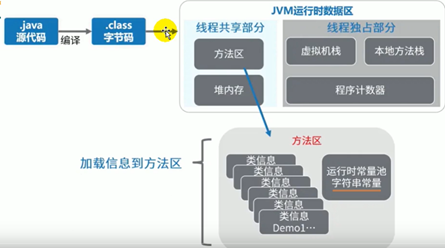
方法区存储什么:存储已被虚拟机加载的类型信息、常量、静态变量、即时编译器编译后的代码缓存等。

类型信息
对每个加载的类型(类class、接口interface、枚举enum、注解annotation),JVM必须在方法区中存储以下类型信息:
①该类的完整有效名称(全名=包名+类名)
②该类的直接父类的完整有效名(对于interface或是java.lang.Object,都没有父类)
③该类的修饰符(public、abstract、final的某个子集)
④该类直接接口的一个有序列表
域(field)信息(成员变量、属性)
JVM必须在方法区中保存类型的所有域的相关信息,以及域的声明顺序。
域的信息包括:
①域名称
②域类型
③域修饰符(public、private、protected、static、final、volatile、transient的某个子集)
方法(Method)信息
JVM必须保存所有方法的以下信息,同域信息一样包括声明顺序:
①方法名称
②方法的返回类型(void)
③方法参数的数量和类型(按顺序)
④方法的修饰符(public、private、protected、static、final、synchronized、native、abstract的一个子集)
⑤方法的字节码、操作数栈、局部变量及大小
⑥异常表(abstract和native方法除外)
每个异常处理的开始位置、结束位置、代码处理在程序计数器中的偏移地址、被捕获的异常类的常量池索引
方法区的内部结构2
特殊:Non-final的类变量
① 静态变量和类关联在一起,随着类的加载而加载,它们成为类数据在逻辑上的一部分。
② 类变量被类的所有实例共享,即使没有类实例也可以访问它。
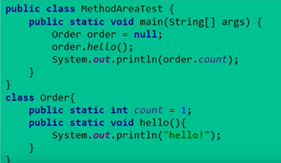
虽然main中order没有初始化,是个空引用,但是后面的order.hello()和order.count都是能够正常执行的。
补充说明:全局常量:static final
被声明为final的类变量的处理方法则不同,每个全局常量在编译的时候就会被分配了。
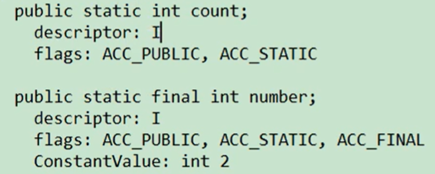
被final修饰的number常量和没有被final修饰的count变量,字节码的对比:
number被final修饰了,则有了一个ConstantValue,这样在类加载阶段,链接部分的Prepare阶段,number的值就确定了,值为2。
Count没有被final修饰,则在类加载阶段,Prepare阶段只是赋一个默认初始值(比如int类型为0),真正的初始化是在链接之后的initialization阶段。
Class文件中常量池的理解
字节码文件中有一个常量池,当字节码文件通过类加载子系统被加载到jvm中后,常量池成为了方法区中的运行时常量池。
常量池=====》运行时常量池
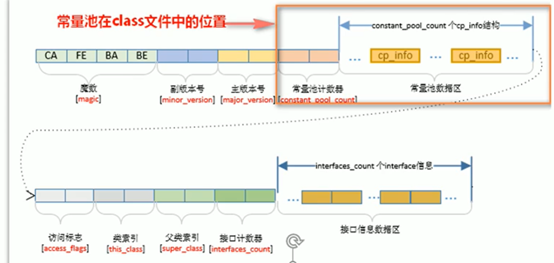
常量池表(Constant Pool Table):包括各种字面量和对类型、域和方法的符号引用。
为什么需要常量池?
一个java源文件中的类、接口,编译后产生一个字节码文件。而Java中的字节码需要数据支持,通常这种数据会很大以至于不能直接存储到字节码里,换另一种方式,可以存储到常量池中,字节码中包含了指向常量池的引用。
在动态链接的时候会用到运行时常量池。
编译出的字节码文件中常量池举例:

在code部分,字节码操作的是对常量池中的引用:

小结:
常量池,可以看做是一张表,虚拟机指令根据这张常量池表,找到要执行的类名、方法名、参数类型、字面量等类型。
运行时常量池的理解
每一个类、接口有一个运行时常量池。
运行时常量池是方法区的一部分。
常量池表是class文件的一部分,用于存放编译期生成的各种字面量与符号引用。这部分内容将在类加载后存放到方法区的运行时常量池中。
运行时常量池,在加载类和接口到JVM后,就会创建对应的运行时常量池
JVM为每个已加载的类型(类或接口)都维护一个常量池。池中的数据项像数组项一样,是通过索引访问的。
运行时常量池中包含多种不同的常量,包括编译期就已经明确的数值字面量,也包括到运行期解析后才能够获得的方法或者字段引用。此时不再是常量池中的符号地址了,这里转换为真实地址。
运行时常量池,相对于class文件常量池的另一个重要特征是:具备动态性。(在运行时,可以往其中添加数据)
运行时常量池类似于传统编程语言中的符号表(symbol table),但是它所包含的数据却比符号表要更加丰富一些。
当创建类或接口的运行时常量池时,如果构造运行时常量池所需的内存空间超过了方法区能提供的最大值,则JVM会抛出OutOfMemoryError异常。
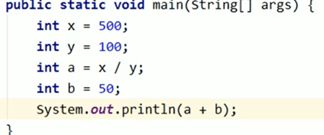
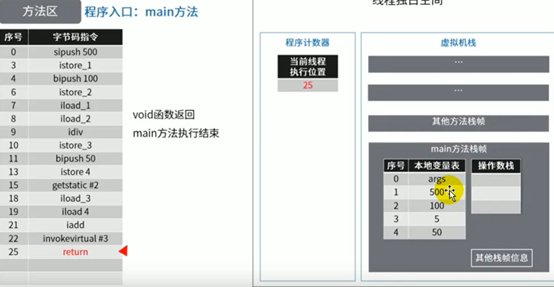
图示举例方法区的使用
代码:
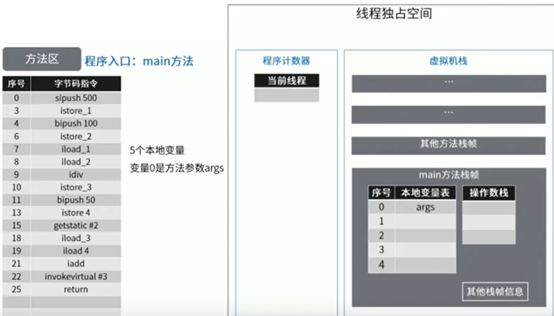
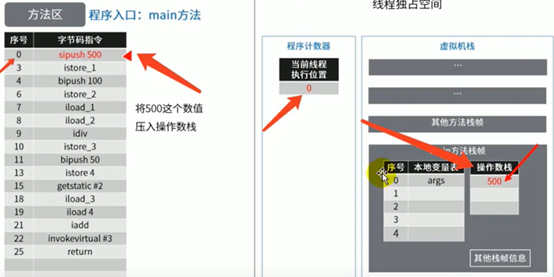
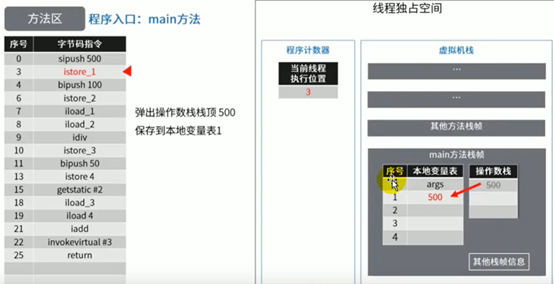
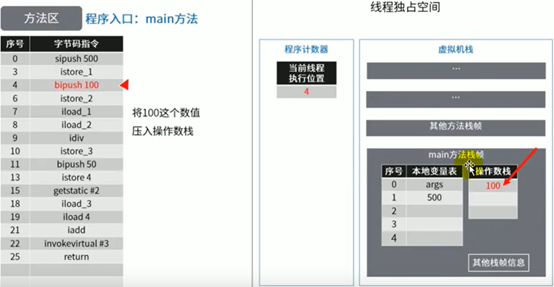
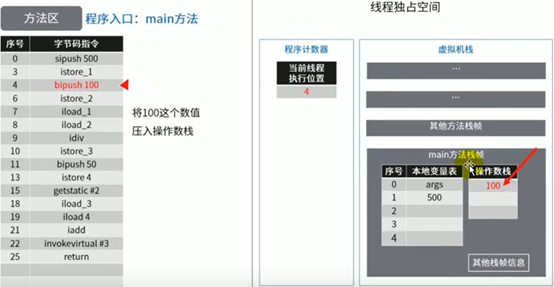
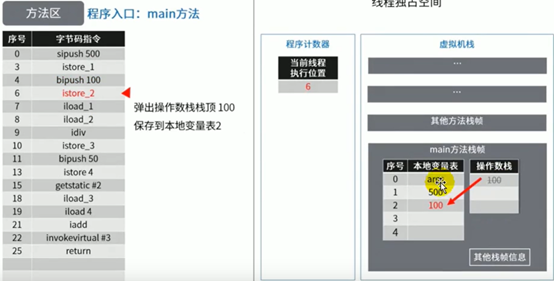



这里少了一张根据istore_3指令把除法结果5存到本地变量表中slot3位置的图。

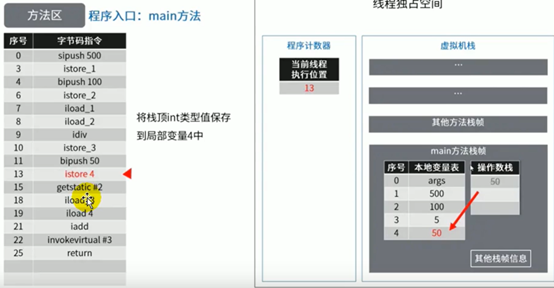

2定义的编号每次编译不太一样,

其实就是调用System.out.println()




方法区在jdk6、7、8中的演进
① 首先明确,只有Hotspot才有永久代(方法区),对于Jrocket、J9都没有永久代的概念。
② Hotspot中方法区的变化:

JDK6
JDK7
JDK8
为什么用元空间替代方法区
在这一小节,宋老师讲了一个提升的方法:不断的去问为什么
根据官方JEP122显示:是JRockit和Hotspot融合的结果。
因为Jrockit没有,所以融合之后,也就去掉了。
官方讲的有点牵强。
宋老师的观点:为什么一开始JRockit没有使用方法区
① 为永久代设置空间大小是很难确定的
在某些场景下,如果动态加载的类过多,容易产生Perm区的OOM。比如某个实际Web工程中,因为功能点较多,在运行过程中,要不断的动态加载很多类,经常出现致命错误。Java.lang.OutOfMemoryError:PermGen
而元空间和永久代之间最大的区别在于:元空间并不在虚拟机中,而是使用本地内存,因此,默认情况下,元空间的大小仅受本地内存限制。
② 对永久代进行调优(GC)是很困难的
StringTable为什么要变换位置
StringTable被翻译成字符串常量池、字符串字面量、interned Strings。
因为永久代的回收效率很低,在full gc的时候才会被触发,而full gc是老年代的空间不足、永久代不足时才会触发。这就导致StringTable回收效率不高。
在开发中会有大量的字符串被创建,回收效率低,导致永久代内存不足,放到堆里之后,能够及时的被回收。
方法区的垃圾回收
《Java虚拟机规范》对方法区的约束是非常宽松的,提到过可以不要求虚拟机在方法区中实现垃圾收集。
一般来说,方法区的回收效果比较难令人满意,尤其是类型的卸载,条件相当苛刻。但是这个区域的回收有时候是很有必要的。
方法区的垃圾收集主要回收两部分内容:
① 常量池中废弃的常量
② 不再使用的类型
判断一个常量是否废弃比较简单,而要判断一个类型是否属于“不再被使用的类”的条件就比较苛刻了。需要同时满足以下三个条件:
①该类所有的实例都已经被回收,也就是java堆中不存在该类及其任何派生子类的实例。
②加载该类的类加载器已经被回收,这个条件除非是经过精心设计的可替换类加载器的场景,如OSGI、JSP的重加载等,否则是很难达成的。
③该类对应的java.lang.Class对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
当满足上述三个条件的时候,java虚拟机被允许对无用类进行回收。但是仅是允许,不一定真的就行回收,并不是像对象一样,没有引用了就真的被回收了。
关于是否要对类型进行回收,Hotspot虚拟机提供了-Xnoclassgc参数进行控制,还可以使用-verbose:class以及-XX:+TraceClass-Loading、-XX:+TraceClassUnLoading查看类加载和卸载信息。
在大量使用反射、动态代理、CGLIB等字节码框架,动态生成jsp以及OSGI这类频繁自定义类加载器的场景中,通常都需要java虚拟机具备类型卸载的能力,以保证不会对方法区造成过大的压力。
运行时数据区的总结

常见面试题



 浙公网安备 33010602011771号
浙公网安备 33010602011771号