(七)Redis复制的原理与优化
七、Redis复制的原理与优化
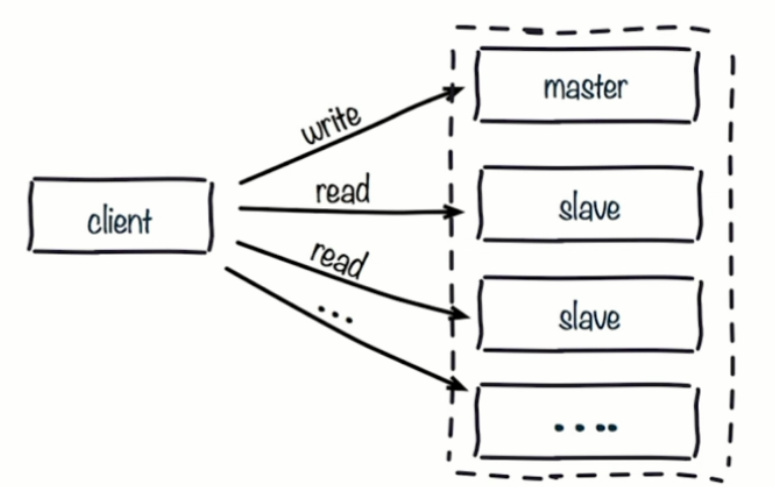
什么是主从复制
首先先看看单机可能会出现什么问题?
- 机器故障
- 容量瓶颈
- QPS瓶颈
主从复制概念图
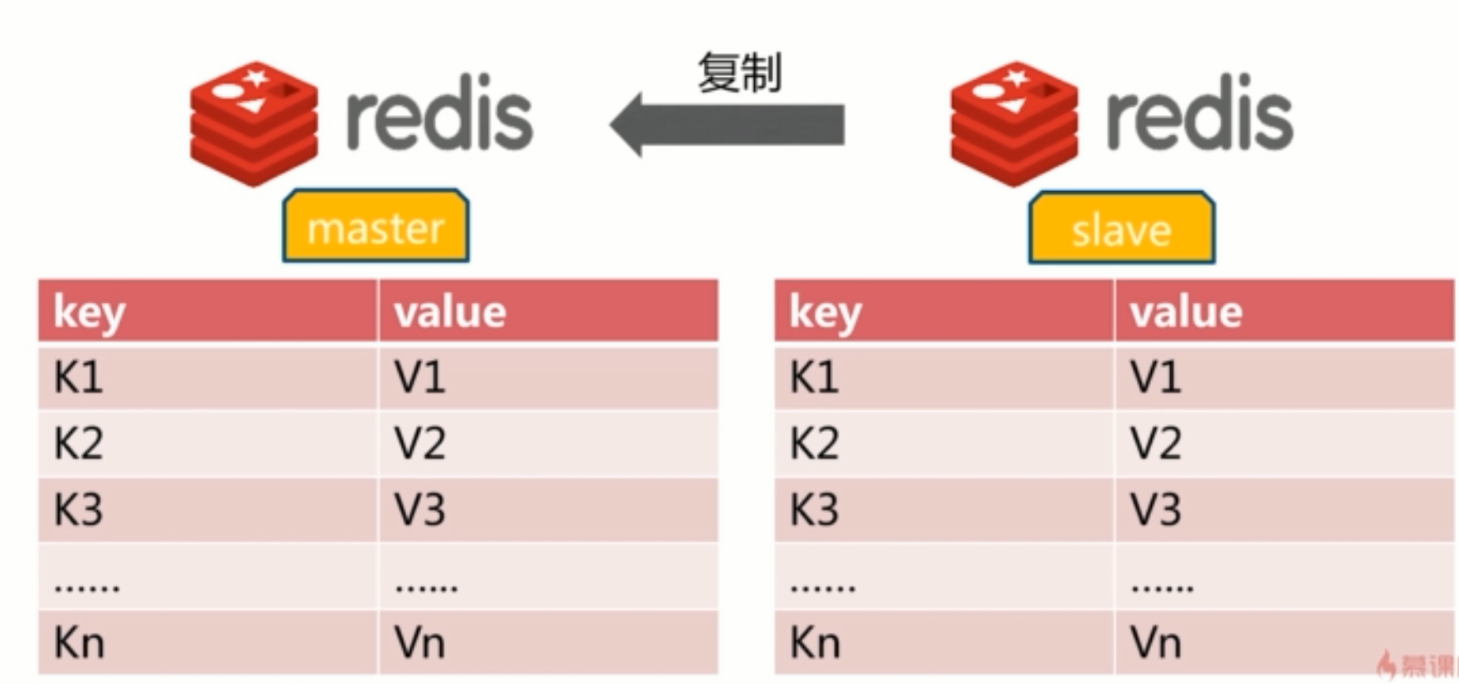
一主多从结构
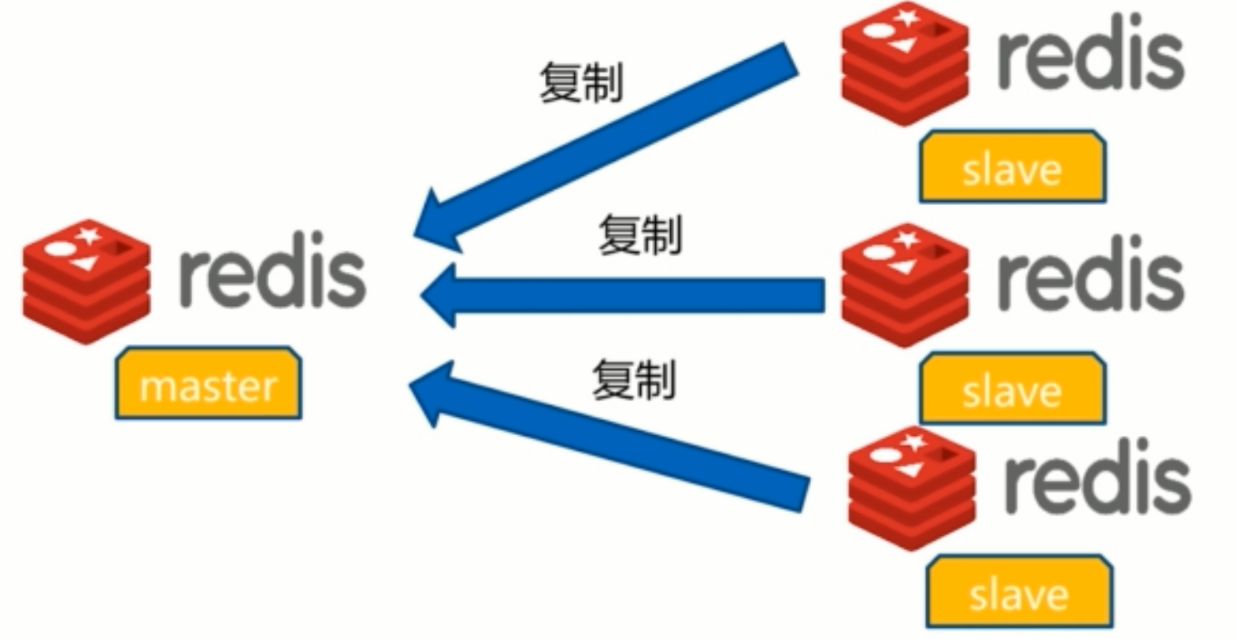
主从复制作用
- 数据副本
- 扩展读性能——读写分离
简单总结
- 一个master可以有多个slave
- 一个slave只能有一个master
- 数据流是单向的,只能从master到slave
主从复制的配置
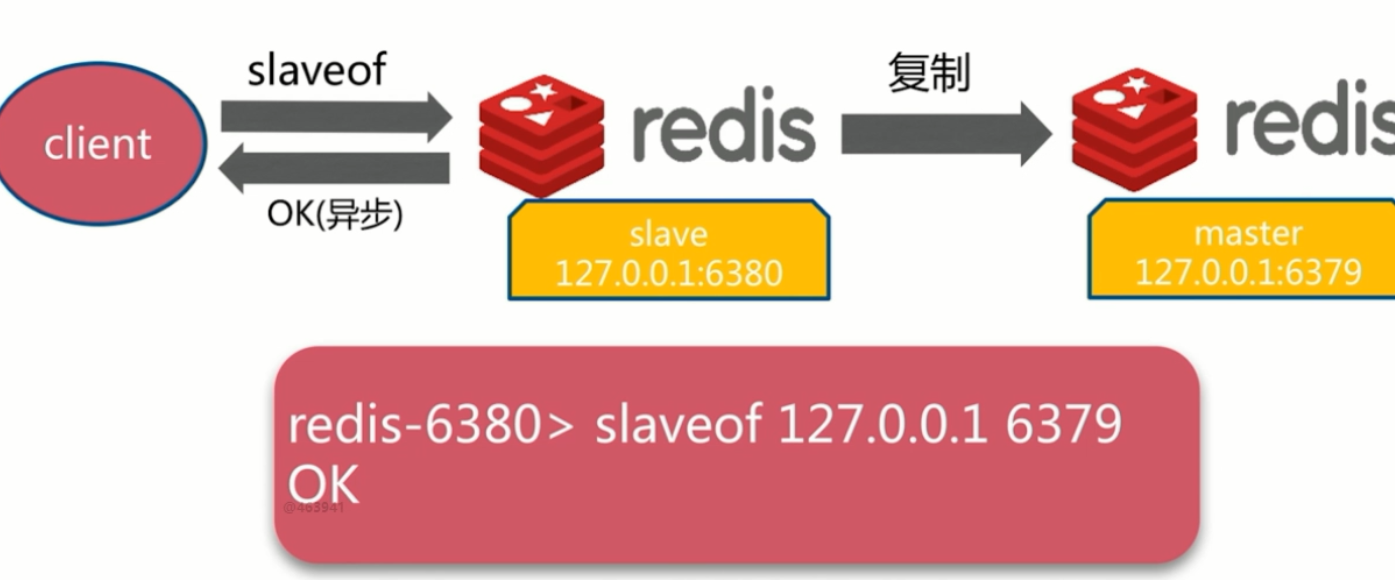
- slaveof命令实现方式
- 建立主从关系
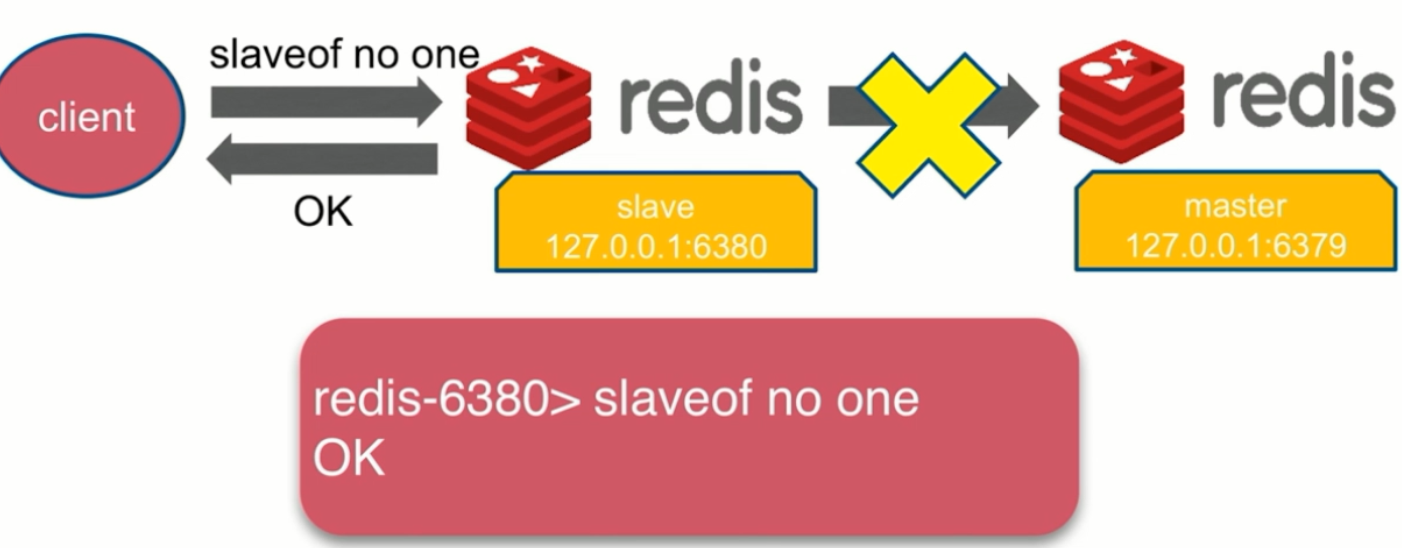
- 断开主从关系
- 建立主从关系
- 配置方式
- slaveof ip port
- slave-read-only yes 只让从节点做读的操作
两种方式比较
| 方式 | 命令 | 配置 |
|---|---|---|
| 优点 | 无需重启 | 统一配置 |
| 缺点 | 不便于管理 | 需要重启 |
全量复制和部分复制
什么是run_id:

Redis每次启动的时候,都会有一个随机的id来保证redis的唯一标识。
当从节点发现master的run_id发生了变化时,就需要把master的数据全量复制到slave中。
偏移量
记录写入了多少数据。当master和slave的偏移量相同时,说明两者的数据是同步的。
全量复制
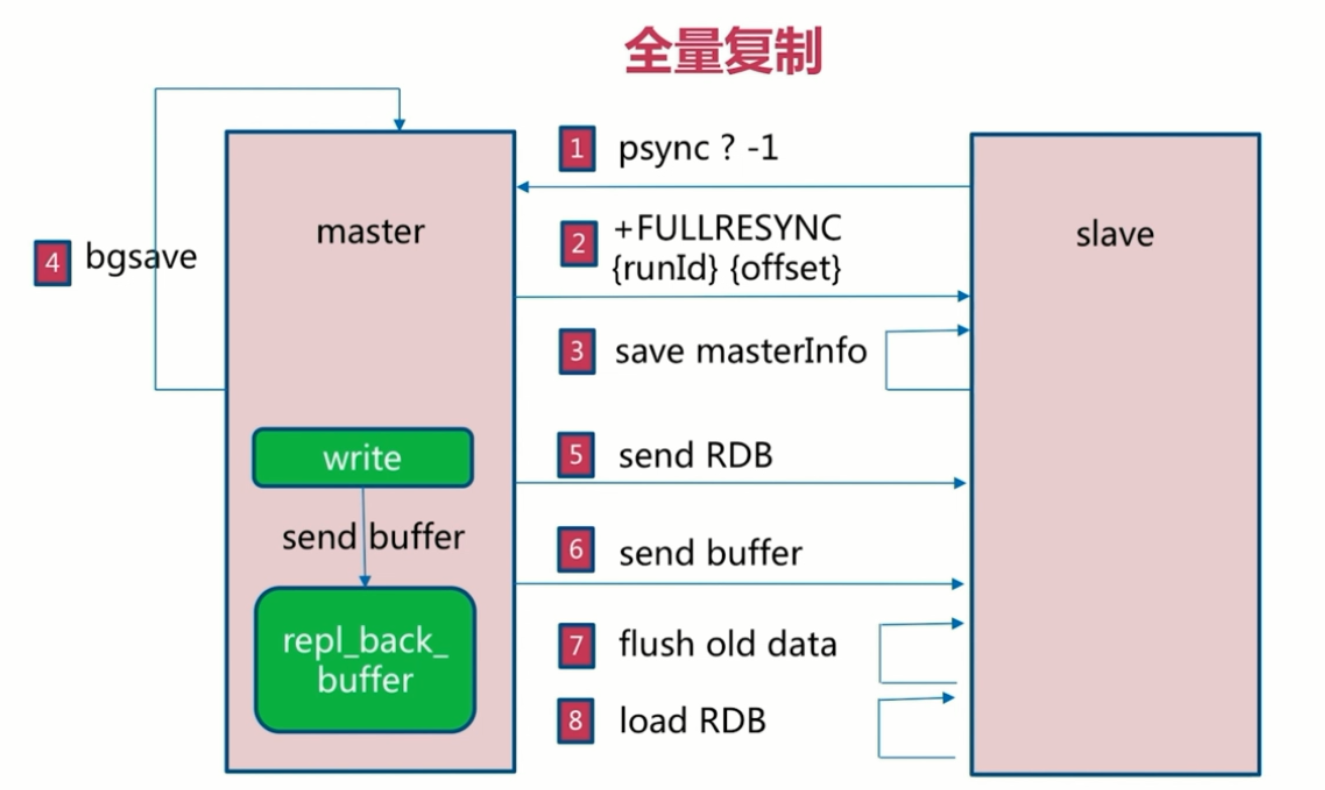
- 第一条命令,因为一开始slave不知道master的run_id,所以用?代替run
- _id,用-1代替偏移量。
- 第二条命令,master收到slave的信息后,明白将要进行全量复制,将自己的run_id和offset告诉slave
- 第三条命令,slave保存master的相关信息
- 第四条命令,master通过bgsave命令快速生成一个快照
- 第五条命令,master将生成的快照通过网络传输送给slave
- 然后master还记录下了生成快照时接收到的新的数据,保存在buffer里,通过第六条命令,将buffer的数据传输给slave
- 第7条命令,slave将之前保存的旧数据冲刷掉
- 第八条命令,slave加载master的数据
全量复制的开销
- bgsave时间
- RDB文件的网络传输时间
- 从节点清空数据时间
- 从节点加载RDB的时间
- 可能的AOF重写时间
部分复制
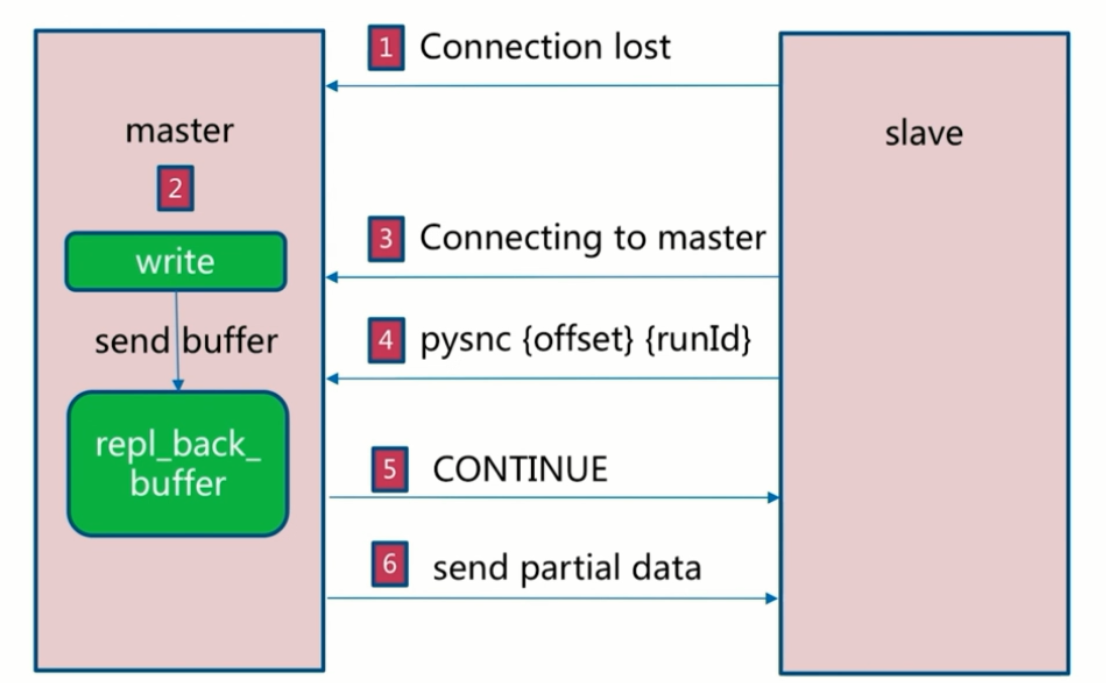
一般发生在master和slave建立连接之后,因为网络问题,断开了连接,然后slave重新与master相连,获得网络断开期间master新增数据的场景。
故障处理
主从结构——故障转移
slave宕机
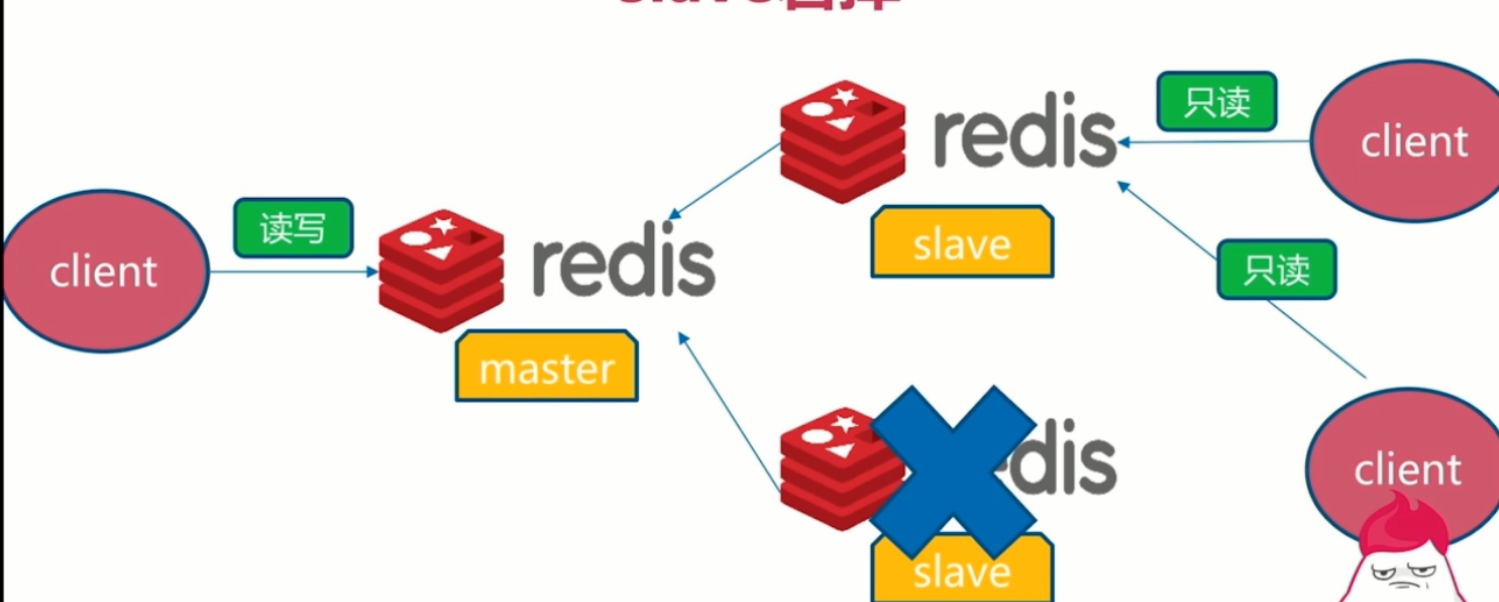
一个slave宕机,还有另外的slave可供读操作。
master宕机
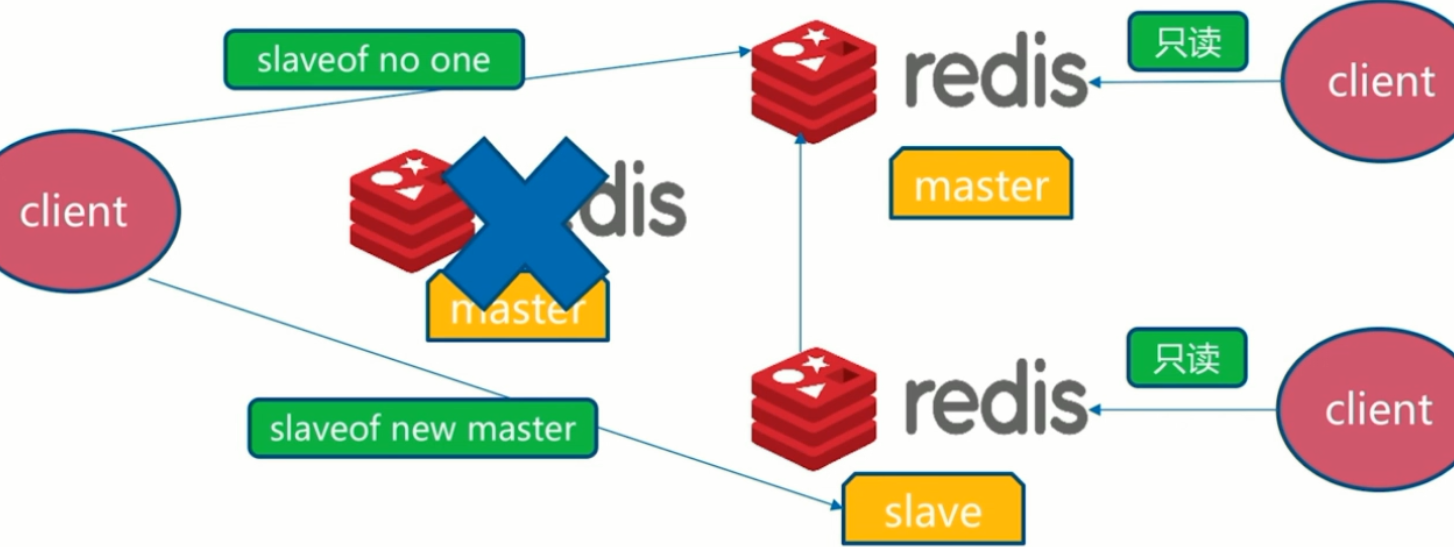
挑选某一个slave升级为master,对它进行读写操作,并让其他的机器成为它的slave。
主从复制常见问题
-
读写分离
读流量分摊到从节点。
![]()
可能遇到的问题:
- 复制数据延迟 - 读到过期数据(比如master中删除了key,而slave中还保留) - 从节点故障 -
主从配置不一致
- 例如maxmemory不一致:丢失数据(主、从节点最大内存不一致)
- 例如数据结构优化参数(如hash-max-ziplist-entries):内存不一致
-
规避全量复制
- 第一次全量复制:不可避免,但可以使用小主节点;在低峰值时进行全量复制
- 节点运行ID不匹配:主节点重启(运行ID变化)。可以使用故障转移,例如哨兵或者集群
- 复制缓冲区不足
-
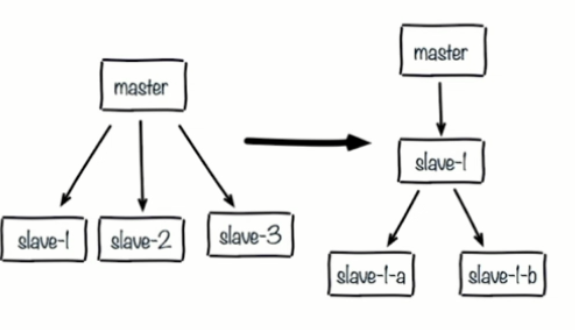
规避复制风暴
- 单主节点复制风暴
- 问题:主节点重启,多从节点复制
- 解决:更换复制拓扑
![]()
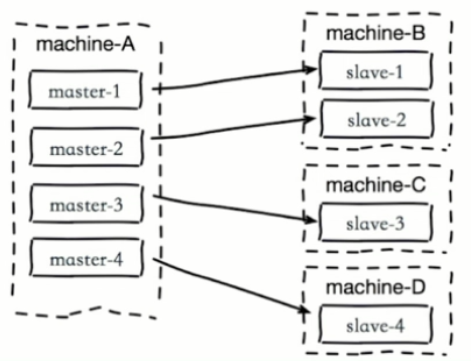
- 单机器复制风暴
- 比如机器宕机后,大量全量复制
- 解决:把主节点分散到多机器上
![]()
- 单主节点复制风暴

 浙公网安备 33010602011771号
浙公网安备 33010602011771号