无需看到你的脸就能认出你——实现Beyond Frontal Faces: Improving Person Recognition Using Multiple Cues
今年年初Facebook AI Research发布了一篇名为Beyond Frontal Faces: Improving Person Recognition Using Multiple Cues的人物识别的文章。
正好公司mentor想搞一个类似的东西看看能不能做一个智能相册出来(有点像iphoto和新版的lightroom里面那个根据人的id来分子相册),于是就实现了一下。
如果只想要代码的话就不用往下看了,请直接点击:https://github.com/sciencefans/Beyond-Frontal-Faces
由于使用了定制的caffe的matlab接口,所以想要跑通需要根据你自己的接口来改一下,还是需要折腾的~
其中feature文件夹下给出了我跑出来的test集上有脸的所有图片的特征向量和labels,可以直接训练svm或者knn跑跑看。
在我的试验中1nn(最邻近)算法居然比svm搞了快10个点。。。
转载请说明转自http://www.cnblogs.com/sciencefans/
整篇文章噱头满满,总结一下有以下贡献:
1.作者从flickr上收集了一个叫People In Photo Albums (PIPA)的数据库,其中:1)标注了人的头的位置,注意是头的位置不是脸的位置;2)有一半的人都是没有脸的;3)包含60000张图,2000多个人;4)数据库分成了三个子库,train,valid和test,互不相交。
具体的一些例子如下:

2.文章提出了一个叫Pose Invariant PErson Recognition(PIPER) 的方法,其实就是搞了109个分类器(具体哪109个后面说),用了一个线性分数叠加来做最后的得分,这个model在上述PIPA的test集上得到了83.05%的准确率,如果只看有脸的图片,准确率能够到达93.4%。这个结果超过了deepface(只有89.3%)。
3.想不出有什么别的贡献了。
一句话总结这篇文章就是:提出了一个标注了头部的数据库,想了一种方法线性叠加了109个CNN-SVM模型来获得了一个很好的identify效果。
下面具体来说一说这109个分类器:
109分类器=用人体的107个poselet(详见参考文献2)分别训练出来的107个CNN(这一步是在Imagenet模型上finetune的,并不是直接训练的)+1个global model(用整个身体来训练一个CNN,一样是finetune)+1个基于DeepFace(详见参考文献3)提出的特征的SVM分类器。
这109个分类器都是神经网络的倒数第二层(fc7)作为特征来训练出的SVM。
怎么组合这109个分类器给出的得分呢?首先计算图片的每个poselet的激活程度(得分程度),如果没有激活(得分很低),则使用global model来代替。计算公式如下:
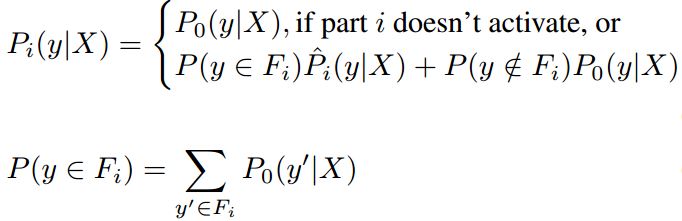
其中Pi就是第i个poselet的svm对X的预测
Fi指的是训练集中拥有第i个poselet的人物的集合,是所有identity的子集。
得到了Pi之后,就可以计算每个分类器的权重w了。
文章使用validation集合来计算得出w,方法还是svm:
对于任意一张图j,它的第i个poselet分类器的得分是
![]()
一共有K个poselet分类器的话,一张图就一共有K+1个得分(加上global model)
这样就相当于一个图可以用一个K+1维的向量表示,用这个特征向量和来训练出一个二分类SVM(label是j是否属于y这个人)
最后每个分类器的权重就是最后这个SVM模型的权重w。
接下来就是实验结果:
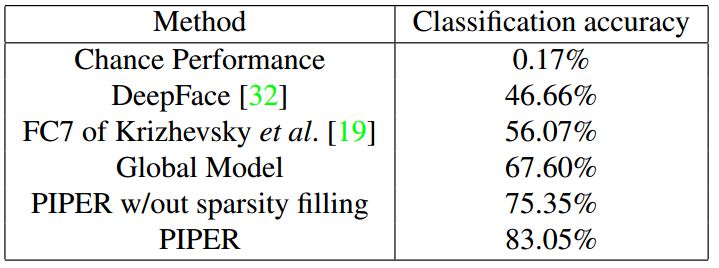
然后作者又用特征做了一下聚类,得到了如下结果:

论文到这里就结束了,我觉得搞这么多分类器来做得分叠加是一个很简单暴力的想法。
复现的时候我用Zeiler网络训练了脸部和global两个model,基于caffe框架在8颗Tesla K40m上跑了整整两天。
其中global model是纯粹根据头部位置计算出的一个矩形区域,效果只做到了百分之三十多(最新更新,效果以做到69.59%)。但是脸部区域达到了和论文近似的效果——全部test集做cross validation得到了82%(91.68%),只看有脸的图能达到91%(93.90%)。这一复现均超越了原文,我猜原因可能是我们的face feature比较好吧。
=======================
参考文献
[1]Ning Zhang, et al, Beyond Frontal Faces: Improving Person Recognition Using Multiple Cues
[2]L. Bourdev and J. Malik. Poselets: Body part detectors trained using 3D human pose annotations. In International Conference on Computer Vision (ICCV), 2009
[3]Y. Taigman, M. Yang, M. Ranzato, and L. Wolf. DeepFace: Closing the Gap to Human-Level Performance in Face Verification. In Conference on Computer Vision and Pattern Recognition (CVPR), 2014

 浙公网安备 33010602011771号
浙公网安备 33010602011771号