
ollama本地部署大模型
前置:需安装docker
1.拉取ollama镜像
docker pull ollama/ollama
如果拉取不成功可通过以下方式解决:
- 修改docker engine配置:https://www.cnblogs.com/scales123/p/19526378
- 其他方式下载镜像:https://docker.aityp.com
2.启动容器
docker run -d \
--name ollama \
-p 11434:11434 \
-v ollama:/root/.ollama \
ollama/ollama:latest-arm64
# -v挂载数据卷参数:能够在容器重启和更新之间持久化模型
容器会立即启动,并开始监听 http://localhost:11434
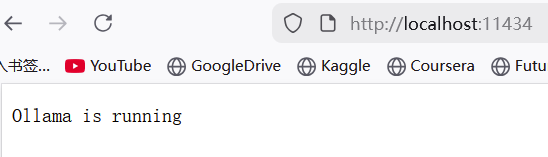
3.下载模型
# 进入容器
docker exec -it ollama bash
# 拉取模型
ollama pull bge-m3
ollama pull qwen2:1.5b
# 验证模型是否已下载
ollama list
4.验证模型
注意:嵌入模型和生成模型的接口不同
# 首先确保容器正在运行
docker ps | grep ollama
curl http://localhost:11434/api/tags
# 测试嵌入功能
curl http://localhost:11434/api/embeddings -d '{
"model": "bge-m3",
"prompt": "Test sentence for embedding"
}'
# 测试生成功能
curl http://localhost:11434/api/chat -d '{
"model": "qwen2:1.5b",
"messages": [{"role": "user", "content": "请介绍一下bge-m3嵌入模型"}],
"stream": false
}'
5.保存为镜像
docker commit ollama ollama-rag:v1
https://blog.eimoon.com/p/run-ollama-in-docker-local-llms-simplified/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号