
spark的共享变量之广播变量和累加器
1 核心概念:为什么需要它们?
在spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的是这个函数所用变量的一个独立副本。这些变量会被复制到每台机器上,并且这些变量在远程机器上的所有更新都不会传递回驱动程序。通常跨任务的读写变量是低效的,但是,Spark还是为两种常见的使用模式提供了两种有限的共享变量:广播变(broadcast variable)和累加器(accumulator):
- 广播变量:用于将 Driver 端的一个大型只读数据分发到所有 Executor 端。(Driver -> Executor 的分发)
- 累加器:用于将 Executor 端的信息聚合回 Driver 端。(Executor -> Driver 的聚合)
它们都是为了在分布式环境下减少不必要的网络传输和序列化开销,并确保操作的正确性和高效性。
2 广播变量
如果我们要在分布式计算里面分发大对象,例如:字典,集合,黑白名单等,这个都会由Driver端进行分发,一般来讲,如果这个变量不是广播变量,那么每个task就会分发一份,这在task数目十分多的情况下Driver的带宽会成为系统的瓶颈,而且会大量消耗task服务器上的资源。广播变量将Driver端的可序列化对象,通过高效的广播协议分发到每个Executor进程的内存中。在每个Executor进程内,所有运行在该Executor上的task线程共享同一份广播变量的内存引用,避免了数据的重复传输和多次反序列化。
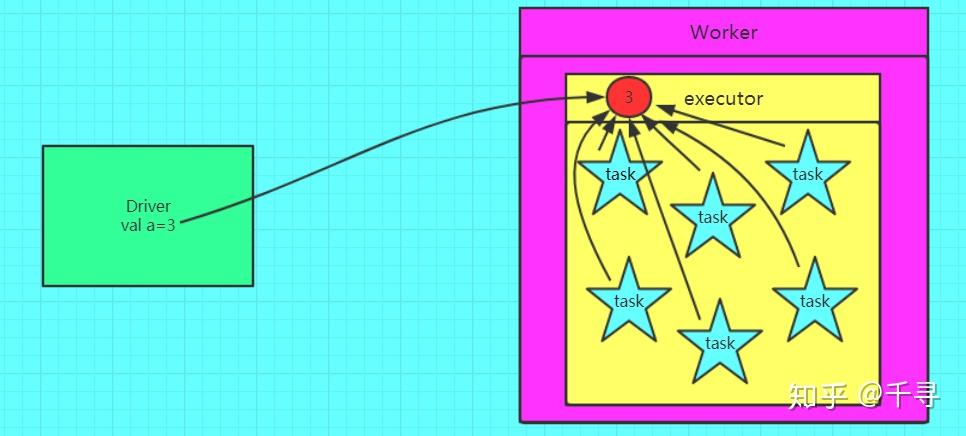
val a = 3
val broadcast = sc.broadcast(a) //把变量a广播出去
val c = broadcast.value //从广播变量里获取a
2.1 广播变量不可修改
在 Spark 中,广播变量传递的是对象的引用,而不是对象本身的副本。这意味着:
- 广播的是对象引用:每个 executor 获得的是指向同一个对象的引用
- 对象本身在 driver 上创建:对象首先在 driver 端创建,然后广播到所有 executor
如果广播的是对象,从技术上来说,executor可以修改广播变量的值,但是强烈不建议这么做,有并发修改风险,多个 executor 同时修改同一个对象会导致数据竞争,修改结果无法保证一致性
,可能因 JVM 内存模型导致修改在不同 executor 间不可见。
// 推荐:使用不可变对象
case class Config(threshold: Int) // val 不可变字段
val config = Config(100)
val broadcastConfig = sc.broadcast(config)
// 只能读取,不能修改
rdd.map { data =>
val currentThreshold = broadcastConfig.value.threshold // ✅ 安全
// ... 只读操作
}
如果需要更新广播变量:
var currentConfig = Config(100)
var broadcastConfig = sc.broadcast(currentConfig)
// 需要更新时
currentConfig = Config(200)
broadcastConfig.unpersist() // 取消旧的广播
broadcastConfig = sc.broadcast(currentConfig) // 广播新对象
2.2 利用广播变量简化大表和小表的join操作
两个RDD进行join操作(即 rdd1.join(rdd2)) 会导致shuffle,这是因为join操作会对key一致的key-vlaue对进行合并,而key相同的key-value对不太可能会在同一个partition, 因此很有可能是需要进行经过网络进行shuffle的,而shuffle会产生许多中间数据(小文件)并涉及到网络传输,这些通常比较耗时,Spark中要尽量避免shuffle。
优化方法:将小RDD的数据通过broadcast到每个executor中,各大RDD partition分别和小RDD做join操作。
具体是:在driver端将小RDD转换成数组array并broadcast到各executor端,然后再各executor task中对各partion的大RDD的key-value对和小rdd的key-value对进行join;由于每个executor端都有完整的小RDD,因此小RDD的各partition不需要shuffle到RDD的各partition,小RDD广播到大RDD的各partition后,各partition分别进行join,最后再执行reduce,所有分区的join结果汇总到driver端。

import org.apache.spark.sql.SparkSession
object BigRDDJoinSmallRDD {
def main(args: Array[String]): Unit = {
val sparkSession = SparkSession.builder().master("local[3]").appName("BigRDD Join SmallRDD").getOrCreate()
val sc = sparkSession.sparkContext
val list1 = List(("jame",23), ("wade",3), ("kobe",24))
val list2 = List(("jame", 13), ("wade",6), ("kobe",16))
val bigRDD = sc.makeRDD(list1)
val smallRDD = sc.makeRDD(list2)
println(bigRDD.getNumPartitions)
println(smallRDD.getNumPartitions)
// driver端rdd不broadcast广播smallRDD到各executor,RDD不能被broadcast,需要转换成数组array
val smallRDDB= sc.broadcast(smallRDD.collect())
val joinedRDD = bigRDD.mapPartitions(partition => {
val smallRDDBV = smallRDDB.value // 各个executor端的task读取广播value
partition.map(element => {
//println(joinUtil(element, smallRDDBV))
joinUtil(element, smallRDDBV)
})
})
joinedRDD.foreach(x => println(x))
}
/**
* join操作:对两个rdd中的相同key的value1和value2进行聚合,即(key,value1).join(key,value2)得到(key,(value1, vlaue2))
* 如果bigRDDEle的key和smallRDD的某个key一致,那么返回(key,(value1, vlaue2))
* 该方法会在各executor的task上执行
* */
def joinUtil(bigRDDEle:(String,Int), smallRDD: Array[(String, Int)]): (String, (Int,Int)) = {
var joinEle:(String, (Int, Int)) = null
// 遍历数组smallRDD
smallRDD.foreach(smallRDDEle => {
if(smallRDDEle._1.equals(bigRDDEle._1)){
// 如果bigRDD中某个元素的key和数组smallRDD的key一致,返回join结果
joinEle = (bigRDDEle._1, (bigRDDEle._2, smallRDDEle._2))
}
})
joinEle
}
}
2.3 如何让spark选择广播join
2.3.1 利用配置项强行广播
使用广播阈值配置项让Spark优先选择Broadcast Joins的关键,就是要确保至少有一张表的存储尺寸小于广播阈值(spark.sql.autoBroadcastJoinThreshold)。那么如何估算一张表的大小呢?第一步,把要预估大小的数据表缓存到内存,比如直接在DataFrame或是Dataset上调用cache方法;第二步,读取Spark SQL执行计划的统计数据。这是因为,Spark SQL在运行时,就是靠这些统计数据来制定和调整执行策略的。
val df: DataFrame = _
df.cache.count
val plan = df.queryExecution.logical
val estimated: BigInt = spark
.sessionState
.executePlan(plan)
.optimizedPlan
.stats
.sizeInBytes
2.3.2 利用API强制广播
2.3.2.1 Join Hints
Join Hints中的Hints表示“提示”,它指的是在开发过程中使用特殊的语法,明确告知Spark SQL在运行时采用哪种Join策略。一旦你启用了Join Hints,不管你的数据表是不是满足广播阈值,Spark SQL都会尽可能地尊重你的意愿和选择,使用Broadcast Joins去完成数据关联。
举个例子,假设有两张表,一张表的内存大小在100GB量级,另一张小一些,2GB左右。在广播阈值被设置为2GB的情况下,并没有触发Broadcast Joins,但我们又不想花费时间和精力去精确计算小表的内存占用到底是多大。在这种情况下,就可以用Join Hints来帮我们做优化,仅仅几句提示就可以达到目的。
val table1: DataFrame = spark.read.parquet(path1)
val table2: DataFrame = spark.read.parquet(path2)
table1.createOrReplaceTempView("t1")
table2.createOrReplaceTempView("t2")
val query: String = “select /*+ broadcast(t2) */ * from t1 inner join t2 on t1.key = t2.key”
val queryResutls: DataFrame = spark.sql(query)
也可以在DataFrame的DSL语法中使用Join Hints:
table1.join(table2.hint(“broadcast”), Seq(“key”), “inner”)
不过,Join Hints也有个小缺陷。如果关键字拼写错误,Spark SQL在运行时并不会显示地抛出异常,而是默默地忽略掉拼写错误的hints,假装它压根不存在。因此,在使用Join Hints的时候,需要我们在编译时自行确认Debug和纠错。
2.3.2.2 广播函数
如果你不想等到运行时才发现问题,想让编译器帮你检查类似的拼写错误,那么你可以使用强制广播的第二种方式:broadcast函数。这个函数是类库org.apache.spark.sql.functions中的broadcast函数。调用方式非常简单,比Join Hints还要方便,只需要用broadcast函数封装需要广播的数据表即可,如下所示。
import org.apache.spark.sql.functions.broadcast
table1.join(broadcast(table2), Seq(“key”), “inner”)
你可能会问:“既然开发者可以通过Join Hints和broadcast函数强制Spark SQL选择Broadcast Joins,那我是不是就可以不用理会广播阈值的配置项了?”其实还真不是。我认为,以广播阈值配置为主,以强制广播为辅,往往是不错的选择。
广播阈值的设置,更多的是把选择权交给Spark SQL,尤其是在AQE的机制下,动态Join策略调整需要这样的设置在运行时做出选择。强制广播更多的是开发者以专家经验去指导Spark SQL该如何选择运行时策略。二者相辅相成,并不冲突,开发者灵活地运用就能平衡Spark SQL优化策略与专家经验在应用中的比例。
2.4 在什么情况下,不适合把Shuffle Joins转换为Broadcast Joins?
不适合把 Shuffle Joins 转换为 Broadcast Joins 的情况主要有以下几种:
大表不适合广播,当数据量超过广播阈值,广播 largeTable 会失败并退回到 shuffle
内存限制问题,当Executor 内存不足以容纳广播数据,如果广播表大小为 1.5GB,可能会导致频繁的 GC,引发 OOM 错误,数据溢出到磁盘,性能反而更差
数据分布不均匀时,广播表中有大量重复键,广播会导致所有 executor 都加载大量重复数据,内存浪费严重,可能还不如 shuffle
Join 类型限制,Spark 不支持 Broadcast Full Outer Join
网络带宽瓶颈,在跨可用区或跨地域集群中网络带宽可能成为瓶颈,可能比 shuffle 更慢(shuffle 是 executor 间交换)
数据特征不适合,维度表频繁更新,每次查询都要重新广播整个维度表;广播表包含复杂数据结构,序列化和反序列化开销巨大
总结:
| 场景 | 广播 Join 适合度 | 原因 |
|---|---|---|
| 小表(<10MB) | ✅ 非常适合 | 内存开销小 |
| 中等表(10MB-100MB) | ⚠️ 需要评估 | 取决于集群资源 |
| 大表(>100MB) | ❌ 不适合 | 内存压力大 |
| 数据倾斜严重 | ❌ 不适合 | 内存浪费 |
| Full Outer Join | ❌ 不支持 | 技术限制 |
| 高并发环境 | ❌ 不适合 | 资源竞争 |
| 网络带宽有限 | ❌ 不适合 | 传输瓶颈 |
// 监控广播 join 是否合适
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", "100MB")
val df = broadcast(mediumTable).join(largeTable, "id")
// 查看执行计划
df.explain()
// 监控广播数据大小
val broadcastSize = mediumTable.queryExecution.optimizedPlan.stats.sizeInBytes
println(s"Broadcast table size: ${broadcastSize / 1024 / 1024} MB")
// 如果看到以下情况,应考虑使用 shuffle:
// 1. GC 时间占比高
// 2. 执行时间比 shuffle 还长
// 3. 频繁的 spill 到磁盘
3 累加器
3.1 闭包
理解累加器,首先理解scala的闭包。什么是闭包?在创建函数时,如果需要捕获自由变量,那么包含指向被捕获变量的引用的函数就被称为闭包函数。在集群中 Spark 会将对 RDD 的操作处理分解为 Tasks ,每个 Task 由 Executor 执行。而在执行之前,Spark会计算 task 的闭包(也就是 foreach() )。闭包会被序列化并发送给每个 Executor,但是发送给 Executor 的是副本,所以在 Driver 上输出的依然是 sum 本身。如果想对 sum 变量进行更新,则就要用到接下来我们要讲的累加器。
3.2 累加器变量
在spark应用程序中,我们经常会有这样的需求,如异常监控,调试,记录符合某特性的数据的数目,这种需求都需要用到计数器,如果一个变量不被声明为一个累加器,那么它将在被改变时不会再driver端进行全局汇总,即在分布式运行时每个task运行的只是原始变量的一个副本,并不能改变原始变量的值,但是当这个变量被声明为累加器后,该变量就会有分布式计数的功能。
3.3 如何使用累加器
Spark内置了三种类型的Accumulator,分别是LongAccumulator用来累加整数型,DoubleAccumulator用来累加浮点型,CollectionAccumulator用来累加集合元素。
3.4 自定义累加器
自定义累加器类型的功能在 1.x 版本中就已经提供了,但是使用起来比较麻烦,在 Spark 2.0.0 版本后,累加器的易用性有了较大的改进,而且官方还提供了一个新的抽象类:AccumulatorV2 来提供更加友好的自定义类型累加器的实现方式。官方同时给出了一个实现的示例:CollectionAccumulator,这个类允许以集合的形式收集 Spark 应用执行过程中的一些信息。例如,我们可以用这个类收集 Spark 处理数据过程中的非法数据或者引起异常的异常数据,这对我们处理异常时很有帮助。当然,由于累加器的值最终要汇聚到 Driver 端,为了避免 Driver 端的出现 OOM,需要收集的数据规模不宜过大。
实现自定义类型累加器需要继承 AccumulatorV2 并覆盖下面几个方法:
- reset 将累加器重置为零
- add 将另一个值添加到累加器中
- merge 将另一个相同类型的累加器合并到该累加器中
下面这个累加器可以用于在程序运行过程中收集一些异常或者非法数据,最终以List[String]的形式返回:
package com.sjf.open.spark;
import com.google.common.collect.Lists;
import org.apache.spark.util.AccumulatorV2;
import java.util.ArrayList;
import java.util.List;
/**
* 自定义累加器 CollectionAccumulator
* @author sjf0115
* @Date Created in 下午2:11 18-6-4
*/
public class CollectionAccumulator<T> extends AccumulatorV2<T, List<T>> {
private List<T> list = Lists.newArrayList();
@Override
public boolean isZero() {
return list.isEmpty();
}
@Override
public AccumulatorV2<T, List<T>> copy() {
CollectionAccumulator<T> accumulator = new CollectionAccumulator<>();
synchronized (accumulator) {
accumulator.list.addAll(list);
}
return accumulator;
}
@Override
public void reset() {
list.clear();
}
@Override
public void add(T v) {
list.add(v);
}
@Override
public void merge(AccumulatorV2<T, List<T>> other) {
if(other instanceof CollectionAccumulator){
list.addAll(((CollectionAccumulator) other).list);
}
else {
throw new UnsupportedOperationException("Cannot merge " + this.getClass().getName() + " with " + other.getClass().getName());
}
}
@Override
public List<T> value() {
return new ArrayList<>(list);
}
}
下面我们在数据处理过程中收集非法坐标为例,来看一下我们自定义的累加器如何使用:
package com.sjf.open.spark;
import com.google.common.collect.Lists;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.VoidFunction;
import java.io.Serializable;
import java.util.List;
/**
* 自定义累加器示例
* @author sjf0115
* @Date Created in 下午2:11 18-6-4
*/
public class CustomAccumulatorExample implements Serializable{
public static void main(String[] args) {
String appName = "CustomAccumulatorExample";
SparkConf conf = new SparkConf().setAppName(appName);
JavaSparkContext sparkContext = new JavaSparkContext(conf);
List<String> list = Lists.newArrayList();
list.add("27.34832,111.32135");
list.add("34.88478,185.17841");
list.add("39.92378,119.50802");
list.add("94,119.50802");
CollectionAccumulator<String> collectionAccumulator = new CollectionAccumulator<>();
sparkContext.sc().register(collectionAccumulator, "Illegal Coordinates");
// 原始坐标
JavaRDD<String> sourceRDD = sparkContext.parallelize(list);
// 过滤非法坐标
JavaRDD<String> resultRDD = sourceRDD.filter(new Function<String, Boolean>() {
@Override
public Boolean call(String str) throws Exception {
String[] coordinate = str.split(",");
double lat = Double.parseDouble(coordinate[0]);
double lon = Double.parseDouble(coordinate[1]);
if(Math.abs(lat) > 90 || Math.abs(lon) > 180){
collectionAccumulator.add(str);
return true;
}
return false;
}
});
// 输出
resultRDD.foreach(new VoidFunction<String>() {
@Override
public void call(String coordinate) throws Exception {
System.out.println("[Data]" + coordinate);
}
});
// 查看异常坐标
for (String coordinate : collectionAccumulator.value()) {
System.out.println("[Illegal]: " + coordinate);
}
}
}
3.5 累加器陷阱
Spark 中的一系列 transformation 操作会构成一个任务链,需要通过 action 操作来触发。累加器也是一样的,也只能通过 action 触发更新,所以在 action 操作之前调用 value 方法查看其数值是没有任何变化的。对于在 action 中更新的累加器,Spark 会保证每个任务对累加器只更新一次,即使重新启动的任务也不会重新更新该值。而如果在 transformation 中更新的累加器,如果任务或作业 stage 被重新执行,那么其对累加器的更新可能会执行多次。解决办法是采用cache打断任务依赖。
val acc = sc.longAccumulator("count")
// 创建 RDD
val rdd = sc.parallelize(1 to 10)
// transformation - 不会立即执行
val mappedRDD = rdd.map { x =>
acc.add(1)
x * 2
}
// 每次 action 都会导致 transformation 重新执行!
mappedRDD.count() // acc = 10
mappedRDD.collect() // acc = 20(又执行了一次!)
println(acc.value) // 输出 20,不是 10!
引用
https://spark.apache.org/docs/latest/rdd-programming-guide.html#shared-variables
https://zhuanlan.zhihu.com/p/113434056
http://www.javatai.cn/bigdata/Spark
https://blog.csdn.net/weixin_36630761/article/details/105860080
https://ebook.qicoder.com/bigdata-notes/notes/Scala
https://www.cnblogs.com/blazeZzz/p/9806684.html
https://www.jianshu.com/p/0c77036ad01b
https://www.cnblogs.com/itboys/p/11056758.html
https://cloud.tencent.com/developer/article/1482147
https://lianglianglee.com/专栏/Spark性能调优实战/13 广播变量(二):如何让Spark SQL选择Broadcast Joins?.md

 浙公网安备 33010602011771号
浙公网安备 33010602011771号