
作业2 深度学习和pytorch基础
视频学习心得:
我有一个朋友,他曾经告诉我神经网络多么多么高大上,多么多么功能全面,但是从学习和课外查阅一些视频资料的过程中我感受到,ai还是有非常大的局限性,比如如果有一些噪声,就很有可能产生可笑的错误,比如:

我也对ai的基础有了一部分了解,在我的理解中,这个过程是一个利用小的方程式,经过类似我们高数课上求导然后蒙积分的大致范围的过程,加上亿点点的数学公式,来得到一个关于数据被拟合后最接近的结果,希望我的理解没啥大问题。
代码练习与分析:
基础数据的建立:


类似于数组的东西,同样支持多维


ones代表他是一个全部为1的矩阵,后面跟着各个维度的维度数
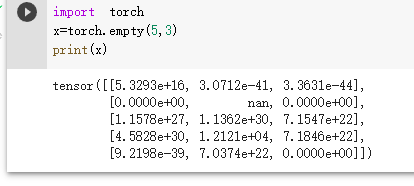
在实验中遇到的所有带有多个维度的定义方法都类似

随机数组

零矩阵,同时利用dtype定义类型
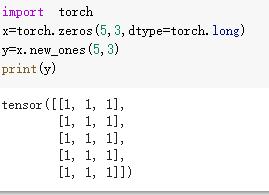

利用new_ones得到新矩阵,ones代表矩阵类型,而后面的数据代表了维度,new决定了其沿用数据类型等信息

你看这里有个rendn,就能看出来他是一个随机化的矩阵,而like仅仅表明了其维度的相似

sep定义的是间隔符,size则是其维度的标记,在这个语境下,size后数值可以从-2取到1

之类的取行或者列的操作和其他某些语言的语法类似,这里就只说一下遇到的问题吧,就是@符号,在实验中,m@v会报错,需要我们把m与v均改为float类型,才可以继续计算,所以在最后一次更改v数值的时候,定义了其类型
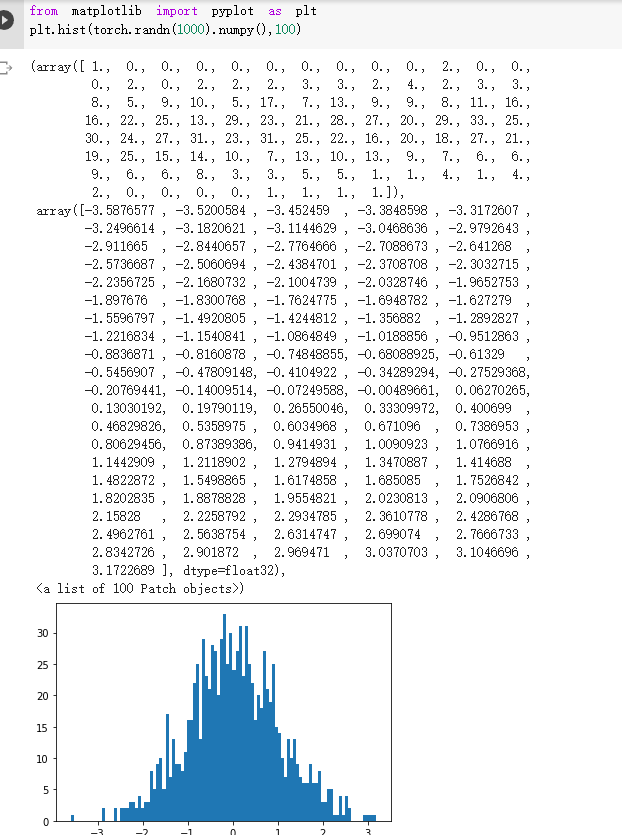

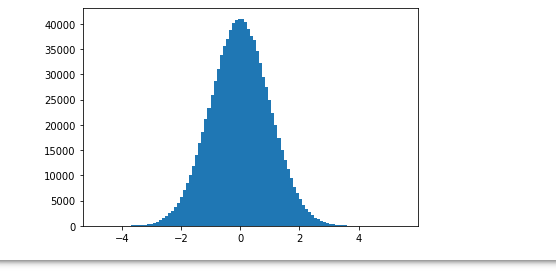
概率课上同款实验
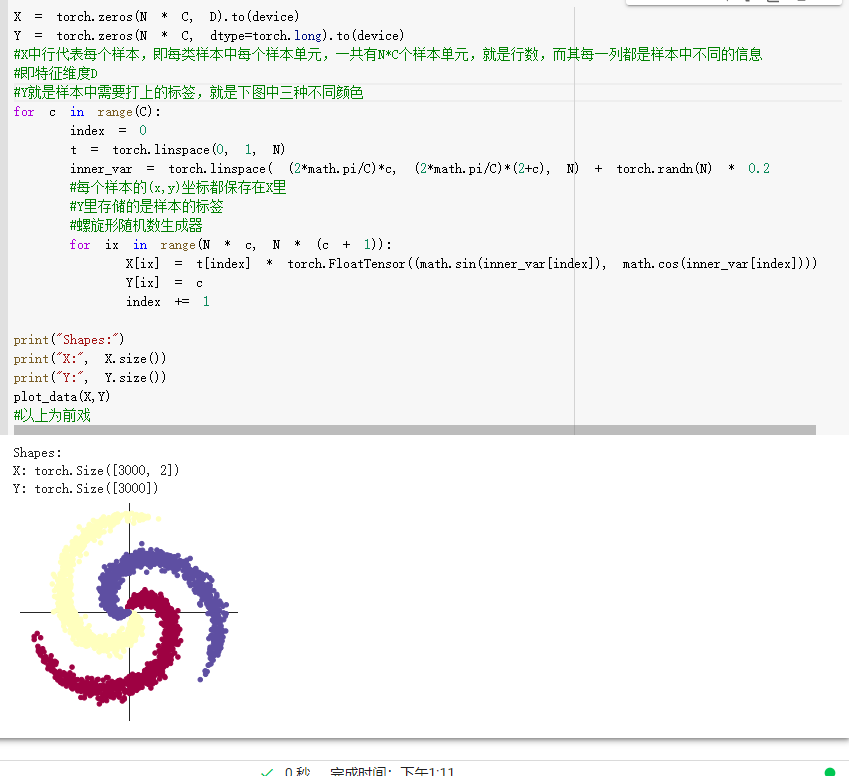
螺旋数据分类:
库的下载,引用和基础变量的定义

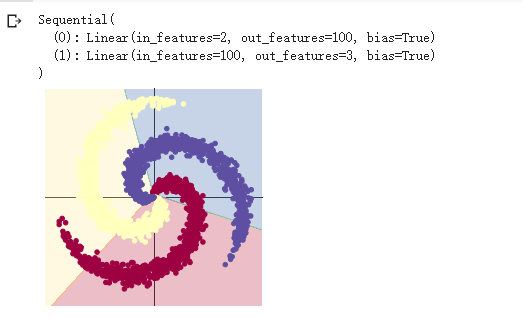

准确率明显比上面未加激活函数高


 浙公网安备 33010602011771号
浙公网安备 33010602011771号