RAG
RAG总结
rag流程总结
RAG 的“检索”环节通常以基于 Embedding 的语义搜索为核心。通用流程如下:
- 离线索引构建:将知识库内文档切分后,使用 Embedding 模型将每个文档块(Chunk)转换为向量,存入专门的向量数据库中。
- 在线查询检索:当用户提出问题时,使用同一个 Embedding 模型将用户的问题也转换为一个向量。
- 相似度计算:在向量数据库中,计算“问题向量”与所有“文档块向量”的相似度。
- 召回上下文:选取相似度最高的 Top-K 个文档块,作为补充的上下文信息,与原始问题一同送给大语言模型(LLM)生成最终答案。
分块
分块策略:
- 固定大小分块
langchain的实现方案:按段落分割,然后根据窗口大小合并。其实是"段落感知的自适应分块",块大小会根据段落边界动态调整。 - 递归字符分块
根据预设的分隔符列表,先根据第一个分隔符划分文档,然后看每一段是否超出窗口长度,如果超出,再根据下一个分隔符继续划分。 - 语义分块
在语义主题发生显著变化的地方进行切分。具体包括:划分句子、计算每个句子及其上下文关系的嵌入、计算语义距离、合并成块。 - 基于文档结构的分块
分的块会带有元数据,表明这一块的每一级标题是什么,表明信息片段的来源和背景。常与其他分块器组合使用,例如MarkdownHeaderTextSplitter将文档按标题分割成若干个大的、带有元数据的逻辑块,对这些逻辑块再应用 RecursiveCharacterTextSplitter,将其进一步切分为符合 chunk_size 要求的小块,所有最终生成的小块都会继承来自第一步的标题元数据。
块并不是越大越好,因为:
- 要满足embedding模型和大模型的上下文窗口记忆长度以内。
- 如果提供给LLM的上下文块又大又杂,充满了与问题无关的噪音,模型就很难从中提取出最关键的信息来形成答案。有研究表明,当LLM处理非常长的、充满大量信息的上下文时,它倾向于更好地记住开头和结尾的信息,而忽略中间部分的内容。
Embedding
静态词嵌入:在“苹果公司发布了新手机”和“我吃了一个苹果”中,“苹果”的词向量是完全相同的,这限制了其在复杂语境下的语义表达能力。为词汇表中的每个单词生成一个固定的、与上下文无关的向量。例如,Word2Vec 通过 Skip-gram 和 CBOW 架构,利用局部上下文窗口学习词向量,并验证了向量运算的语义能力(如 国王 - 男人 + 女人 ≈ 王后)。
动态词嵌入:同一个词在不同语境中会生成不同的向量,这有效解决了静态嵌入的一词多义难题。现代嵌入模型的核心通常是 Transformer 的编码器(Encoder)部分,BERT 就是其中的典型代表。它通过堆叠多个 Transformer Encoder 层来构建一个深度的双向表示学习网络。
训练流程:
- 掩码语言模型 (Masked Language Model, MLM). 随机地将输入句子中 15% 的词元(Token)替换为一个特殊的 [MASK] 标记。让大模型去预测原本词元
- 下一句预测 (Next Sentence Prediction, NSP). 构造训练样本,每个样本包含两个句子 A 和 B,让模型判断 B 是否是 A 的下一句。
现代嵌入模型通常会引入更具针对性的训练策略:
- 度量学习 (Metric Learning)
收集大量相关的文本对(例如,(问题,答案)、(新闻标题,正文))。让“正例对”的向量表示在空间中被“拉近”,而“负例对”的向量表示被“推远”。 - 对比学习 (Contrastive Learning)
构建一个三元组(Anchor, Positive, Negative)。其中,Anchor 和 Positive 是相关的(例如,同一个问题的两种不同问法),Anchor 和 Negative 是不相关的。训练的目标是让 distance(Anchor, Positive) 尽可能小,同时让 distance(Anchor, Negative) 尽可能大。
多模态嵌入
传统的文本嵌入无法理解“那张有红色汽车的图片”这样的查询,因为文本向量和图像向量处于相互隔离的空间,存在一堵“模态墙”。
多模态嵌入 (Multimodal Embedding) 的目标正是为了打破这堵墙。其目的是将不同类型的数据(如图像和文本)映射到同一个共享的向量空间。在这个统一的空间里,一段描述“一只奔跑的狗”的文字,其向量会非常接近一张真实小狗奔跑的图片向量。实现这一目标的关键,在于解决 跨模态对齐 (Cross-modal Alignment) 的挑战。
OpenAI 的 CLIP (Contrastive Language-Image Pre-training) 是一个很有影响力的模型,它为多模态嵌入定义了一个有效的范式。
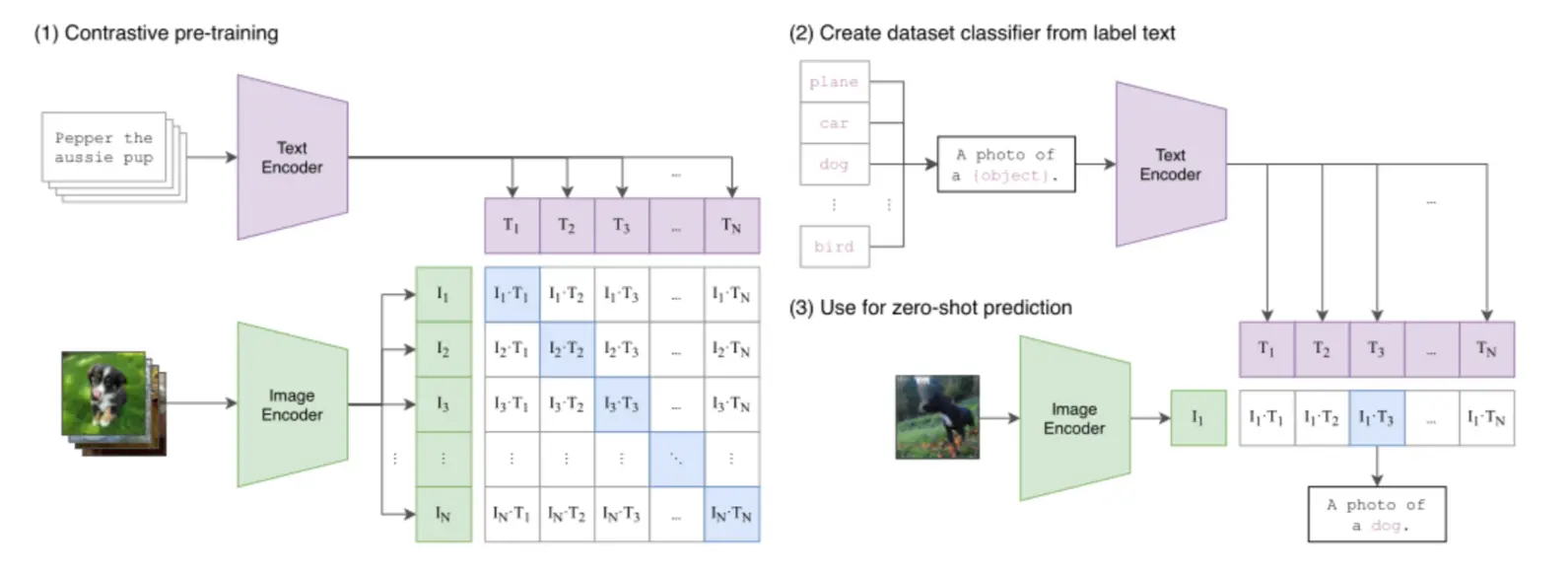
为了让这两个编码器学会“对齐”不同模态的语义,CLIP 在训练时采用了对比学习 (Contrastive Learning) 策略。在处理一批图文数据时,模型的目标是:最大化正确图文对的向量相似度,同时最小化所有错误配对的相似度。通过这种“拉近正例,推远负例”的方式,模型从海量数据中学会了将语义相关的图像和文本在向量空间中拉近。
这种大规模的对比学习赋予了 CLIP 有效的零样本(Zero-shot)识别能力。它能将一个传统的分类任务,转化为一个“图文检索”问题——例如,要判断一张图片是不是猫,只需计算图片向量与“a photo of a cat”文本向量的相似度即可。这使得 CLIP 无需针对特定任务进行微调,就能实现对视觉概念的泛化理解。
向量数据库
当向量数量从几百个增长到数百万甚至数十亿时,需要快速、准确地从海量向量中找到与用户查询最相似的那几个。
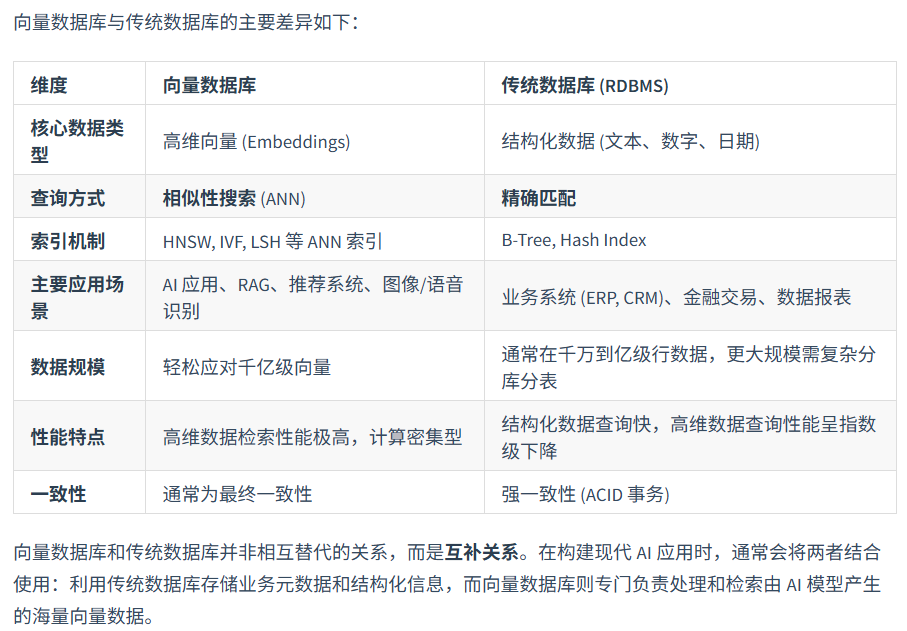
- Chroma 是一款轻量级的开源向量数据库,采用本地优先设计,无依赖。它提供零配置安装、本地运行和低资源消耗等特性,特别适合原型开发、教育培训和小规模应用。Chroma的部署简单,适合快速原型开发。
- Milvus 是一款开源的分布式向量数据库,采用分布式架构设计,支持GPU加速和多种索引算法。它能够处理亿级向量检索,提供高性能GPU加速和完善的生态系统。Milvus特别适合大规模部署、高性能要求的场景,以及需要自定义开发的开源项目。
- 与 ChromaDB 等数据库不同,FAISS 本质上是一个算法库,它将索引直接保存为本地文件(一个 .faiss 索引文件和一个 .pkl 映射文件),而非运行一个数据库服务。这种方式轻量且高效。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号