大模型
1 前言
1.1 huggingface
Hugging Face 是一个人工智能公司,提供的transformer库十分好用,以及社区:https://huggingface.co,类似于github。
1.1.1 应用
以nlp为例,典型使用流程:
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# 加载 tokenizer 和模型
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased")
# 编码输入
inputs = tokenizer("I love Hugging Face!", return_tensors="pt")
# 模型前向推理
outputs = model(**inputs)
# 输出 logits(未归一化的类别分数)
print(outputs.logits)
1.1.2 主要组件
1.1.2.1 AutoTokenizer, AutoModel
自动适配你加载的模型类型,不用手动选类。
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
model = AutoModel.from_pretrained("bert-base-cased")
1.1.2.2 pipeline
封装常见任务,适合快速测试:
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
result = classifier("I love this library!")
print(result)
1.1.2.2 datasets
统一的数据集管理工具,支持自动下载 + 分词 + token 化.
from datasets import load_dataset
dataset = load_dataset("imdb") # 加载 IMDB 数据集
2 tokens和embedding
2.1 tokens
tokens是词元。按照某种形式进行切分得到的子词。
2.1.1 切分方式
例如:"ChatGPT is awesome!"
- 单词级别(空格划分)
["ChatGPT", "is", "awesome", "!"]
- 字符级别(直接split)
["C", "h", "a", "t", "G", "P", "T", " ", "i", "s", ...]
- 子词级别
["Chat", "G", "PT", " is", " awe", "some", "!"]
大多数现代大模型(包括 GPT)使用 子词分词法(比如 BPE、WordPiece、SentencePiece),因为它能很好平衡 词汇覆盖率 和 模型大小。
你可以用 OpenAI 提供的工具 tiktoken 查看分词情况(适用于 GPT 模型):
import tiktoken
enc = tiktoken.encoding_for_model("gpt-4")
tokens = enc.encode("ChatGPT is awesome!")
print(tokens) # 输出 token 的 ID
print(len(tokens)) # 输出 token 的数量
2.2 embedding

2.2.1 one-hot编码
One-hot 是一种最基础的表示离散符号的方法。
对于["apple", "banana", "cat", "dog"],
每个词都可以表示为一个全 0 向量,只有对应词的位置是 1:
apple [1, 0, 0, 0]
banana [0, 1, 0, 0]
cat [0, 0, 1, 0]
dog [0, 0, 0, 1]
独热编码简单直观,适合离散分类;但维度高且稀疏(大多数元素是0),不包含词与词之间的任何“语义信息”。
比如 “apple” 和 “banana” 实际上语义很接近,但它们的 one-hot 向量之间没有任何关系。
2.2.2 embedding是什么
我们可以把 embedding 理解成是 “低维的、可学习的、语义丰富的 one-hot 替代品”。
从数学角度讲,embedding 就是:
把 one-hot 向量(维度 = 词表大小)通过一个权重矩阵投影(投影矩阵)到一个低维空间(比如 128、256、768 维)。
简化理解:
one-hot(大小 V) × W(V × D)= embedding(大小 D)
V 是词表大小(vocab size), D 是嵌入维度(embedding dim), W 是一个 embedding 矩阵,是模型的参数,会随着训练更新。
2.2.3 上下文embedding
上下文 embedding 是指词或子词的向量表示,它的数值不仅取决于词本身,还取决于它在句子中的上下文语境。这是与传统词向量(如 word2vec、GloVe)最大的区别。
例如:"He sat on the bank of the river." vs "He deposited money in the bank."
代码:
from transformers import AutoTokenizer, AutoModel
import torch
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
model = AutoModel.from_pretrained("bert-base-uncased")
sentence = "He sat on the bank of the river"
inputs = tokenizer(sentence, return_tensors="pt")
outputs = model(**inputs)
embeddings = outputs.last_hidden_state # shape: [batch_size, seq_len, hidden_dim]
“词表 + embedding table”看作 Transformer 模型的输入入口,它把词的符号转成初始向量,而后续的上下文 embedding 才是“理解”阶段。
2.2.4 文本embedding
将一句话/一段文本转化为embedding。
示例代码:
from transformers import AutoTokenizer, AutoModel
import torch
model_name = "sentence-transformers/all-MiniLM-L6-v2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
sentence = "I love deep learning"
inputs = tokenizer(sentence, return_tensors="pt", padding=True, truncation=True)
with torch.no_grad():
outputs = model(**inputs)
# 提取句子 embedding(平均池化)
embedding = outputs.last_hidden_state.mean(dim=1)
就得到了一个维度为 [1, hidden_dim] 的句子向量,可以用于文本分类、检索、聚类等任务。
应用场景:
| 场景 | 使用说明 |
|---|---|
| 语义搜索 | 将 query 和文档编码为向量,计算余弦相似度 |
| 聚类 | 文本转向量后做 KMeans、DBSCAN 等 |
| 可视化 | 降维到 2D 展示文本语义分布(如 TSNE) |
| 文本分类 | 把 embedding 喂入分类器(SVM、MLP) |
| 问答 / RAG | 检索相似文本片段辅助生成答案 |
2.3 tokenizer
2.3.1 概念
Tokenizer(分词器)是将自然语言文本(如句子、段落)转换成模型可处理的token序列的工具,也可以逆向转换。
这些token是数字编号,最终会作为模型的输入。
例如:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
text = "Transformers are amazing!"
# 编码为 token id
encoded = tokenizer.encode(text)
print("Token IDs:", encoded)
# 解码回字符串
decoded = tokenizer.decode(encoded)
print("Decoded:", decoded)
不同tokenizer有自己不同的词表,词表是token <-> id的映射字典,每个 tokenizer 都有词表的正向和反向映射。
查看tokenizer的词表:
tokenizer = AutoTokenizer.from_pretrained("gpt2")
vocab = tokenizer.get_vocab() # 返回 dict
print(list(vocab.items())[:10]) # 打印前十个 token 与 id
2.3.2 应用
现代大模型使用的 tokenizer 通常是 子词级别(subword level),这里列出最主流的几种:
| 名称 | 常用于模型 | 算法思想 | 特点 |
|---|---|---|---|
| BPE(Byte Pair Encoding) | GPT 系列(GPT-2/3/4)、RoBERTa、CLIP、Qwen | 基于频率的合并规则 | 高压缩率,性能好 |
| WordPiece | BERT 系列 | 类似 BPE,控制词表大小 | 可控性好,语义稳健 |
| Unigram Language Model | ALBERT、T5、XLNet | 概率模型,选最优子词集合 | 压缩率和泛化较好 |
| SentencePiece(库) | T5、mBART、BLOOM | 支持 BPE/Unigram,支持生僻字符、空格编码 | 脱离空格,原生支持多语言 |
| Byte-Level BPE | GPT-2、GPT-Neo、OPT | 每个字节都是 token,支持任意文本 | 无需预处理,更健壮 |
| TokenizerFast(基于 Rust) | Huggingface 中统一接口 | 性能极快,提供一致 API | 封装了各种算法 |
3 对话格式和RRMNorm以及KVCache
3.1 ChatML
ChatML 是一种“对话格式的标注协议”,用于告诉大语言模型:一段输入是“谁说的什么话”,以结构化的方式进行对话信息建模。
Chat:表示这是用于“多轮对话”的上下文格式。
ML:代表 “Markup Language(标记语言)”,像 XML/HTML 一样使用标签来表示结构。
3.2 Alpaca
Alpaca 对话格式是一种 轻量级的指令微调格式,最早由斯坦福大学在Alpaca项目中提出,用于训练类ChatGPT的语言模型。该格式是基于 “指令-输入-输出”三元组的结构,非常适合用于单轮问答或伪多轮指令模拟训练。
{
"instruction": "根据输入的关键词写一篇短文",
"input": "人工智能,未来",
"output": "人工智能是未来技术发展的关键......"
}
3.1.1 基本格式
<|im_start|>system
你是一个智能助手。<|im_end|>
<|im_start|>user
请解释一下牛顿第一定律。<|im_end|>
<|im_start|>assistant
牛顿第一定律,也称惯性定律,是指......<|im_end|>
或者
[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me a joke."},
{"role": "assistant", "content": "Why did the chicken cross the road? To get to the other side!"}
]
常见角色包括:
- system: 设定初始角色和风格(如“你是法律顾问”)
- user: 用户输入内容
- assistant: 模型输出内容
- tool: 工具调用(如函数调用、插件)
3.2 RMSNorm(Root Mean Square Layer Normalization)
2.2.1 定义:
RMSNorm 是一种 简化的 LayerNorm(层归一化),最早由 Zhang & Sennrich (2019) 提出。与 LayerNorm 不同,它只归一化输入的均方根值(Root Mean Square),不减去均值。
3.2.2 公式:
设输入为 \(x \in \mathbb{R}^d\),RMSNorm 计算方式为:
其中:
- \(\gamma\):可训练的缩放参数(和 LayerNorm 一样)
- \(\epsilon\):防止除零的小常数
3.2.3 与 LayerNorm 区别:
| 项目 | LayerNorm | RMSNorm |
|---|---|---|
| 是否减均值 | ✅ 是 | ❌ 否 |
| 计算复杂度 | 稍高 | 更低 |
| 表现差距 | 相近 | 相近甚至更好(在 LLM 中) |
| 使用情况 | GPT-2, BERT 等 | LLaMA, BLOOM, RWKV 等 |
为什么 LLaMA 用 RMSNorm?
- 更快、内存更低
- 更适合深层网络
- 更稳定(尤其在 fp16/bfloat16 精度下)
3.3 KVCache(Key-Value Cache)
3.3.1 定义:
KVCache 是 Transformer 推理(尤其是解码阶段)中缓存 注意力机制中的 Key 和 Value 的技术,从而避免每一步都重复计算前面所有 token 的 Key 和 Value。
3.3.2 背景:注意力计算
在自回归模型中,decoder 的每一步都要做如下注意力计算:
其中:
- Q: 当前 token 的 Query
- K: 所有历史 token 的 Key
- V: 所有历史 token 的 Value
如果每生成一个 token 就重新计算 K 和 V,会非常浪费时间!
KVCache 做了什么?
在第一次生成 token 时:
-
模型保存每个 token 的 Key 和 Value:
kv_cache["key"] = [K₁, K₂, ..., K_t] kv_cache["value"] = [V₁, V₂, ..., V_t] -
后续每一步:
- 只计算当前 token 的 Query(Q)
- 与缓存的 K、V 做注意力
- 避免重复计算
3.3.3 优点:
| 优势 | 说明 |
|---|---|
| 快速推理 | 缓存 K/V 避免重复计算,提高解码速度 |
| 节省显存 | 对于 fp16 或量化模型,缓存非常高效 |
| 解码更稳定 | 连续对话、长文本生成时稳定性更好 |
3.3.4 KVCache 举例(推理过程):
for step in range(max_length):
q = model.compute_query(new_token)
k, v = model.compute_kv(new_token)
kv_cache.append(k, v)
output = attention(q, kv_cache.k, kv_cache.v)
new_token = decode(output)
KVCache 是必须理解的加速机制;而如果你想自定义模型架构,RMSNorm 是比 LayerNorm 更适合深层 Transformer 的选择。
4 SFT
4.1 大模型训练流程
SFT 是 Supervised Fine-Tuning(监督微调)的缩写,是大语言模型训练中的一个关键阶段。
4.1.1 预训练Pretraining
数据来自海量无标注文本:书籍、网页、论文、代码、对话、社交平台等。
数据量百 GB ~ 数 TB。
让模型掌握语言基础能力,例如语法、常识、词义联想、上下文理解。
训练任务:
自回归语言建模(Causal LM):如 GPT 系列,给定前文预测下一个 token(用左侧上下文)
掩码语言建模(Masked LM):如 BERT,随机遮盖词,让模型填空
4.1.2 监督微调SFT (Supervised Fine-Tuning)
让模型具备“指令跟随能力”,即根据任务需求做问答、翻译、摘要、代码生成等。
人工构造或过滤出的 高质量指令-响应对。
数据格式:
{
"instruction": "请总结下面的文章",
"input": "这是一篇关于……",
"output": "这篇文章主要讲了……"
}
参数高效微调(PEFT)技术,可用来SFT:
- LoRA
- Prefix Tuning
- P-Tuning
- adapter tuning
- prompt tuning
4.1.3 对齐训练
这一步是让模型变得“更像助手”,不仅要 正确,还要 有礼貌、安全、不胡说八道。
这个步骤分为几个方法:
4.1.3.1 人类反馈强化学习(RLHF)
训练三步走:
-
收集回答对比(模型 A vs 模型 B,哪个更好?)
-
训练奖励模型(学习人类偏好)
-
强化学习优化(PPO 等方法优化原模型)
代表:ChatGPT、Claude、InstructGPT
4.1.3.2 DPO(Direct Preference Optimization)
一种更简单、直接替代 RLHF 的新方法,不需要复杂的 RL 过程。
4.1.4 后训练(Post-training)和工具增强
这一步可选,有些有,有些没有。
多模态扩展:引入图像、音频、视频(如 GPT-4V、Gemini)
工具增强:引入计算器、搜索引擎、数据库调用等(如 Toolformer, ChatGPT Plugins)
领域适配(Domain Adaptation):金融、医疗、法律等定制模型(如 BloombergGPT)
5 Transformer
5.1 自注意力
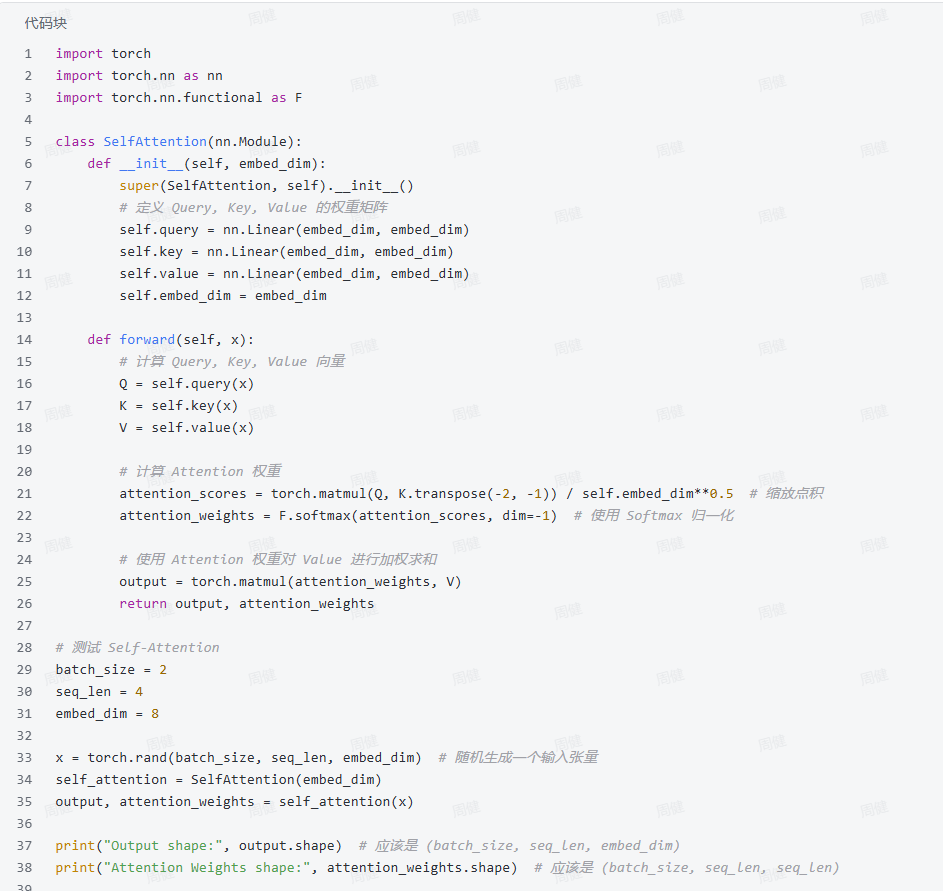
为什么除以\(\sqrt{d_k}\)

5.2 FFN
一句话定义:在Transformer模型中,FFN(Feed-Forward Network,前馈神经网络)是每个编码器和解码器层的重要组成部分,位于自注意力机制之后。它的主要作用是对自注意力层输出的特征进行非线性变换和增强,进一步提升模型的表达能力。

FFN,或者说是 MLP(多层感知机,也就是全连接层加激活函数的堆叠),是注意力之后的非线性处理器,它帮助模型在局部空间重新塑形信息。
为什么 Transformer 的 FFN 具有扩展维度(通常 4 倍隐藏层维度)?
注意力层(Attention)处理的是token 间的交互,而 FFN 则对每个 token 独立地做非线性变换。换句话说:Attention 是“交流”,FFN 是“思考”。为了让每个 token “思考得更深”,FFN 提供了一个更高维的中间特征空间。扩展维度就是为了在这个空间中能进行更丰富的非线性组合。
5.3 层归一化

-
为什么Transformer选择LayerNorm而非BatchNorm?
Transformer 输入的是序列(文本 token、图像 patch、语音帧……),长度不固定。BatchNorm 要在同一 batch 内统计所有样本的均值方差,但不同样本序列长度不同 → 无法统一统计。 -
层归一化在 Transformer 中的作用是什么?
在 Transformer 中,LayerNorm 是数值稳定器:控制每层输入的尺度;保持梯度健康;减少分布漂移;稳定收敛并提高泛化。Self-Attention 和 FFN 各自都可能让特征爆炸或塌陷,LayerNorm 则让整个网络始终“温度适中”。
所以 Transformer 的 LayerNorm 虽然名字叫“归一化”,但实际上做的是标准化操作(零均值 + 单位方差)。
关于归一化以及标准化的说法

层归一化实现
nn.LayerNorm只针对于最后一个维度起作用。减去均值,除以标准差。
x = torch.randn(batch_size, seq_len, d_model)
layer_norm = nn.LayerNorm(d_model)
normalized_x = layer_norm(x)
RMSNorm不减均值,并且除以的是每一项平方和(比方差少了减均值的操作)然后开根。
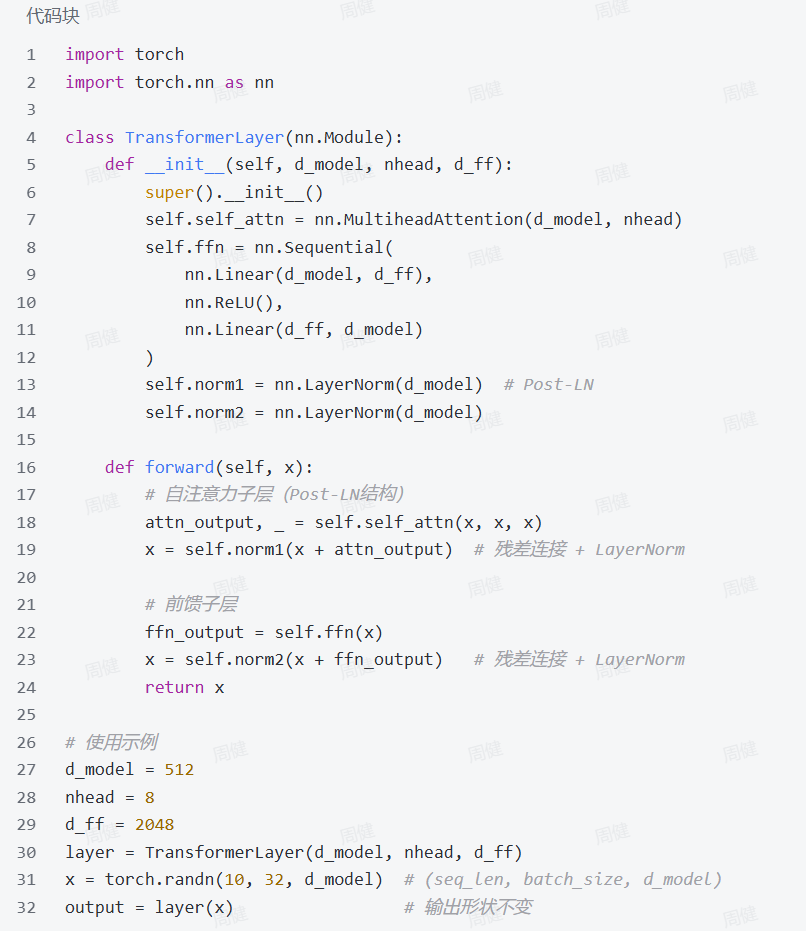
5.4 残差链接
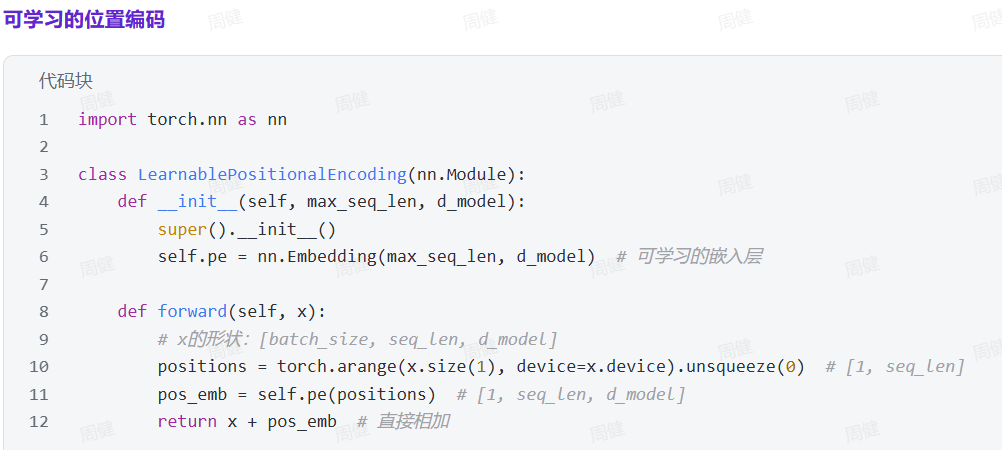
5.5 位置编码
两种方法
- 绝对位置编码
正弦/余弦函数结合位置pos和维度i获取独特的值。 - 可学习的位置编码(如BERT)
方法:随机初始化一个位置嵌入矩阵,形状为[max_seq_len, d_model],通过训练学习。
长度外推
长度外推(Length Extrapolation)指模型在训练时只见过固定长度的序列,在推理时能否正确处理更长的序列。
产生原因:可学习位置编码只对训练长度有效;长序列输入可能导致模型捕捉不到远程依赖。
解决:函数式位置编码(如正弦、RoPE);相对位置编码(Relative Position Bias);分层或递归结构,压缩上下文层级建模。
6 大模型预训练
一句话定义:预训练(Pre-training) 是指在大规模无标注数据上训练模型,使其学习通用的语言表示(如词、句子的语义和语法规律),再通过微调(Fine-tuning) 适配到具体任务(如文本分类、问答)。核心思想:先“通识教育”,再“专业训练”。
6.1 自监督学习

6.2 继续预训练

7 大模型微调
一句话定义:微调是指在一个大模型已经通过大规模数据集(如通用文本、图像数据集等)进行预训练之后,在一个相对较小且专用的任务数据集上进行进一步的训练。这一过程的目的是让模型在新的任务中得到优化,通常涉及调整模型的部分参数,或者根据新数据集的特征进行适当的修改。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号