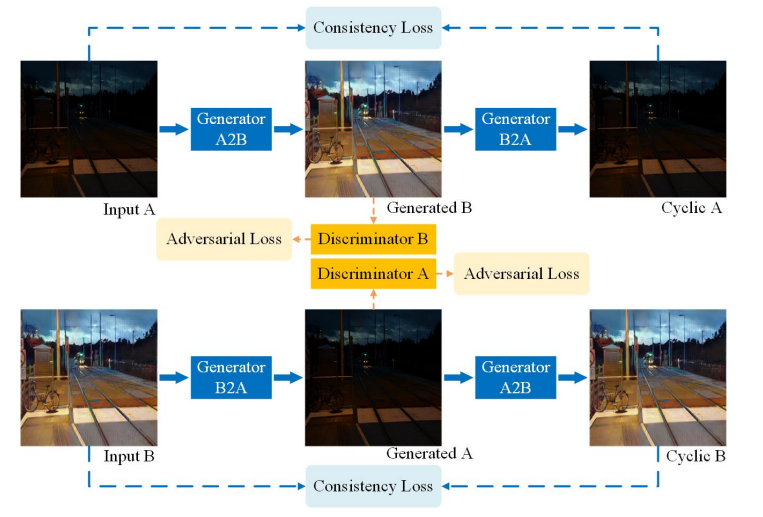
cycleGAN模型结构图
import torch # 深度学习主库
import itertools # 提供链式迭代等工具(这里用于把多个参数迭代器拼接)
from util.image_pool import ImagePool # 用于判别器的“历史假样本缓存”,提高训练稳定性
from .base_model import BaseModel # 本项目的模型基类:统一训练/保存/可视化等接口
from . import networks # 网络结构、权重初始化、学习率调度、GAN 损失等工具
class CycleGANModel(BaseModel):
# 继承baseModel类,实现CycleGANModel类
"""
A (source domain), B (target domain).
Generators: G_A: A -> B; G_B: B -> A.
Discriminators: D_A: G_A(A) vs. B; D_B: G_B(B) vs. A.
Forward cycle loss: lambda_A * ||G_B(G_A(A)) - A|| (Eqn. (2) in the paper)
Backward cycle loss: lambda_B * ||G_A(G_B(B)) - B|| (Eqn. (2) in the paper)
Identity loss (optional): lambda_identity * (||G_A(B) - B|| * lambda_B + ||G_B(A) - A|| * lambda_A) (Sec 5.2 "Photo generation from paintings" in the paper)
Dropout is not used in the original CycleGAN paper.
"""
parser.set_defaults(no_dropout=True) # 默认关闭 dropout(原论文配置)
if is_train: # 仅训练阶段才需要这些权重系数
# 这里配置的是损失函数中各部分损失项的系数值
parser.add_argument('--lambda_A', type=float, default=10.0, help='weight for cycle loss (A -> B -> A)') # 前向循环一致性损失系数
parser.add_argument('--lambda_B', type=float, default=10.0, help='weight for cycle loss (B -> A -> B)') # 反向循环一致性损失系数
parser.add_argument('--lambda_identity', type=float, default=0.5, # 身份保持损失系数(可选)
help='use identity mapping. Setting lambda_identity other than 0 has an effect of scaling the weight of the identity mapping loss. For example, if the weight of the identity loss should be 10 times smaller than the weight of the reconstruction loss, please set lambda_identity = 0.1')
return parser # 返回修改后的 parser
def __init__(self, opt):
# 类初始化
"""Initialize the CycleGAN class.
Parameters:
opt (Option class)-- stores all the experiment flags; needs to be a subclass of BaseOptions
"""
BaseModel.__init__(self, opt) # 调用父类构造:设置设备/保存目录/公共字段等
# 指定需要在日志中打印/保存的损失项名称(与后续 self.loss_* 属性对应)
self.loss_names = ['D_A', 'G_A', 'cycle_A', 'idt_A', 'D_B', 'G_B', 'cycle_B', 'idt_B']
# 指定需要可视化/保存的图像张量名称
# 这部分在前面的章节里有看到过
# 因为这种图像生成式模型中,有些输出张量需要转化为可视化的图像的形式,所以用Visual_names另外地指定它们
visual_names_A = ['real_A', 'fake_B', 'rec_A'] # 域 A:真图、翻译到 B 的假图、重建回 A 的图
visual_names_B = ['real_B', 'fake_A', 'rec_B'] # 域 B:真图、翻译到 A 的假图、重建回 B 的图
if self.isTrain and self.opt.lambda_identity > 0.0: # 若启用 identity loss,则一并可视化恒等输出
visual_names_A.append('idt_B') # idt_B = G_A(B)
visual_names_B.append('idt_A') # idt_A = G_B(A)
self.visual_names = visual_names_A + visual_names_B # 汇总两域的可视化名称列表
# 指定需要保存/加载的网络名后缀(BaseModel会据此 save/load)
if self.isTrain:
self.model_names = ['G_A', 'G_B', 'D_A', 'D_B'] # 训练阶段保存 G 与 D
else: # 测试阶段仅需生成器
self.model_names = ['G_A', 'G_B']
# -------------------------
# 定义网络:两个生成器 + 两个判别器
# 论文记号对照:G_A(G) : A->B,G_B(F): B->A;D_A(D_Y): 判别 B 域;D_B(D_X): 判别 A 域
# -------------------------
# 完整的cycleGAN定义需要有这些部分:
# 生成器 判别器 损失函数 生成器和判别器的学习率优化器
# 在这里定义两种不同的生成器
self.netG_A = networks.define_G(opt.input_nc, opt.output_nc, opt.ngf, opt.netG, opt.norm,
not opt.no_dropout, opt.init_type, opt.init_gain, self.gpu_ids) # 生成器 A->B
self.netG_B = networks.define_G(opt.output_nc, opt.input_nc, opt.ngf, opt.netG, opt.norm,
not opt.no_dropout, opt.init_type, opt.init_gain, self.gpu_ids) # 生成器 B->A
if self.isTrain: # 判别器仅在训练时需要
self.netD_A = networks.define_D(opt.output_nc, opt.ndf, opt.netD,
opt.n_layers_D, opt.norm, opt.init_type, opt.init_gain, self.gpu_ids) # 判别器:区分 B 与 G_A(A)
self.netD_B = networks.define_D(opt.input_nc, opt.ndf, opt.netD,
opt.n_layers_D, opt.norm, opt.init_type, opt.init_gain, self.gpu_ids) # 判别器:区分 A 与 G_B(B)
if self.isTrain:
if opt.lambda_identity > 0.0: # 若使用 identity loss,必须满足输入/输出通道一致
assert(opt.input_nc == opt.output_nc)
# 历史假样本池:用过往生成的假样本训练判别器,打破 G/D 的短期相互适应
self.fake_A_pool = ImagePool(opt.pool_size)
self.fake_B_pool = ImagePool(opt.pool_size)
# 定义损失函数
self.criterionGAN = networks.GANLoss(opt.gan_mode).to(self.device) # GAN 损失(lsgan/vanilla/wgangp)
self.criterionCycle = torch.nn.L1Loss() # 循环一致性使用 L1
self.criterionIdt = torch.nn.L1Loss() # 身份保持使用 L1
# 定义优化器;学习率调度器会在 BaseModel.setup() 中根据 opt 创建
# 生成器优化器:联合优化 G_A 与 G_B 的参数
self.optimizer_G = torch.optim.Adam(
itertools.chain(self.netG_A.parameters(), self.netG_B.parameters()),
lr=opt.lr, betas=(opt.beta1, 0.999)
)
# 判别器优化器:联合优化 D_A 与 D_B 的参数
self.optimizer_D = torch.optim.Adam(
itertools.chain(self.netD_A.parameters(), self.netD_B.parameters()),
lr=opt.lr, betas=(opt.beta1, 0.999)
)
# 交给基类统一管理(便于调度器创建、save/load 等)
self.optimizers.append(self.optimizer_G)
self.optimizers.append(self.optimizer_D)
def set_input(self, input):
"""Unpack input data from the dataloader and perform necessary pre-processing steps.
Parameters:
input (dict): include the data itself and its metadata information.
The option 'direction' can be used to swap domain A and domain B.
"""
AtoB = self.opt.direction == 'AtoB' # 若 direction=AtoB,则 dataloader 的 A/B 语义保持;否则交换
# 将 A 域与 B 域的张量搬到当前设备;并记录路径用于可视化/日志
self.real_A = input['A' if AtoB else 'B'].to(self.device)
self.real_B = input['B' if AtoB else 'A'].to(self.device)
self.image_paths = input['A_paths' if AtoB else 'B_paths']
def forward(self):
"""Run forward pass; called by both functions <optimize_parameters> and <test>."""
self.fake_B = self.netG_A(self.real_A) # 生成 A->B 的假图:G_A(A)
self.rec_A = self.netG_B(self.fake_B) # 重建回 A:G_B(G_A(A))
self.fake_A = self.netG_B(self.real_B) # 生成 B->A 的假图:G_B(B)
self.rec_B = self.netG_A(self.fake_A) # 重建回 B:G_A(G_B(B))
def backward_D_basic(self, netD, real, fake):
"""Calculate GAN loss for the discriminator
Parameters:
netD (network) -- the discriminator D
real (tensor array) -- real images
fake (tensor array) -- images generated by a generator
Return the discriminator loss.
We also call loss_D.backward() to calculate the gradients.
"""
# 判别器在真实样本上的损失
pred_real = netD(real)
loss_D_real = self.criterionGAN(pred_real, True)
# 判别器在假样本上的损失;fake.detach() 断开生成器的梯度
pred_fake = netD(fake.detach())
loss_D_fake = self.criterionGAN(pred_fake, False)
# 综合两部分并平均;随后回传梯度
loss_D = (loss_D_real + loss_D_fake) * 0.5
loss_D.backward()
return loss_D # 返回该判别器的总损失
def backward_D_A(self):
"""Calculate GAN loss for discriminator D_A"""
# 从池中取“历史混合”的假样本更稳健地训练 D_A
fake_B = self.fake_B_pool.query(self.fake_B)
self.loss_D_A = self.backward_D_basic(self.netD_A, self.real_B, fake_B)
def backward_D_B(self):
"""Calculate GAN loss for discriminator D_B"""
# 同理,训练 D_B
fake_A = self.fake_A_pool.query(self.fake_A)
self.loss_D_B = self.backward_D_basic(self.netD_B, self.real_A, fake_A)
def backward_G(self):
"""Calculate the loss for generators G_A and G_B"""
lambda_idt = self.opt.lambda_identity # 身份保持系数
lambda_A = self.opt.lambda_A # A 循环一致性系数
lambda_B = self.opt.lambda_B # B 循环一致性系数
# Identity loss(可选):要求跨域输入在对应生成器上近似恒等
if lambda_idt > 0:
# G_A 对 B 的恒等:||G_A(B) - B|| * lambda_B * lambda_idt
self.idt_A = self.netG_A(self.real_B)
self.loss_idt_A = self.criterionIdt(self.idt_A, self.real_B) * lambda_B * lambda_idt
# G_B 对 A 的恒等:||G_B(A) - A|| * lambda_A * lambda_idt
self.idt_B = self.netG_B(self.real_A)
self.loss_idt_B = self.criterionIdt(self.idt_B, self.real_A) * lambda_A * lambda_idt
else:
self.loss_idt_A = 0 # 关闭则置零,避免影响总损失
self.loss_idt_B = 0
# GAN 对抗损失:希望 D_A 认为 G_A(A) 为真、D_B 认为 G_B(B) 为真
self.loss_G_A = self.criterionGAN(self.netD_A(self.fake_B), True)
self.loss_G_B = self.criterionGAN(self.netD_B(self.fake_A), True)
# 循环一致性损失:重建应接近原图
self.loss_cycle_A = self.criterionCycle(self.rec_A, self.real_A) * lambda_A
self.loss_cycle_B = self.criterionCycle(self.rec_B, self.real_B) * lambda_B
# 合并所有生成器相关的损失并回传
self.loss_G = (self.loss_G_A + self.loss_G_B +
self.loss_cycle_A + self.loss_cycle_B +
self.loss_idt_A + self.loss_idt_B)
self.loss_G.backward()
def optimize_parameters(self):
"""Calculate losses, gradients, and update network weights; called in every training iteration"""
# 1) 前向:生成假图与重建图
self.forward()
# 2) 优化生成器(冻结两个判别器的梯度)
self.set_requires_grad([self.netD_A, self.netD_B], False)
self.optimizer_G.zero_grad()
self.backward_G()
self.optimizer_G.step()
# 3) 优化判别器(解冻判别器)
self.set_requires_grad([self.netD_A, self.netD_B], True)
self.optimizer_D.zero_grad()
self.backward_D_A()
self.backward_D_B()
self.optimizer_D.step()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号