【数据结构】排序 内部排序算法的比较和应用
1.简单复习一下前面学到的排序算法
三种插入排序:
直接插入: 依次将后面无序序列中头部的元素插入前面的有序序列中(找到插入位置,这个位置后面的元素一律后移)
折半插入: 相比直接插入只是用折半查找的方式查找插入位置,元素的移动操作不变
希尔排序: 把相隔一定步长d的元素放入一个子表中,分别对每个子表进行直接插入,进行多趟比较并不断缩小步长,直到步长为1时所有元素都在一个表中,直接进行插入排序。
两种交换排序:
冒泡排序: 进行多趟比较并局部交换,每次使一个元素处于正确位置上。
快速排序: 每趟选择一个元素作为枢轴,通过交替搜索+交换使小于枢轴的元素置于其左侧,大于枢轴的则置于其右侧。不断划分直到序列完全有序。
两种选择排序:
简单选择: 第i趟排序从L[i…n]中选择关键字最小的元素与L[i]交换,每次确定一个元素的最终位置。
堆排序: 将初始序列建成堆,每次输出堆顶元素并重新调整剩余元素成堆,不断输出堆顶以得到有序序列。
其他排序
归并排序: 以2路归并为例,初始时将整个序列看做n个长度为1的子表,趟将相邻的子表两两归并,最终得到一个有序的序列。
基数排序: 借助辅助队列进行多趟分配+收集,不基于比较和移动。
2.各算法的相关性能数据对比图
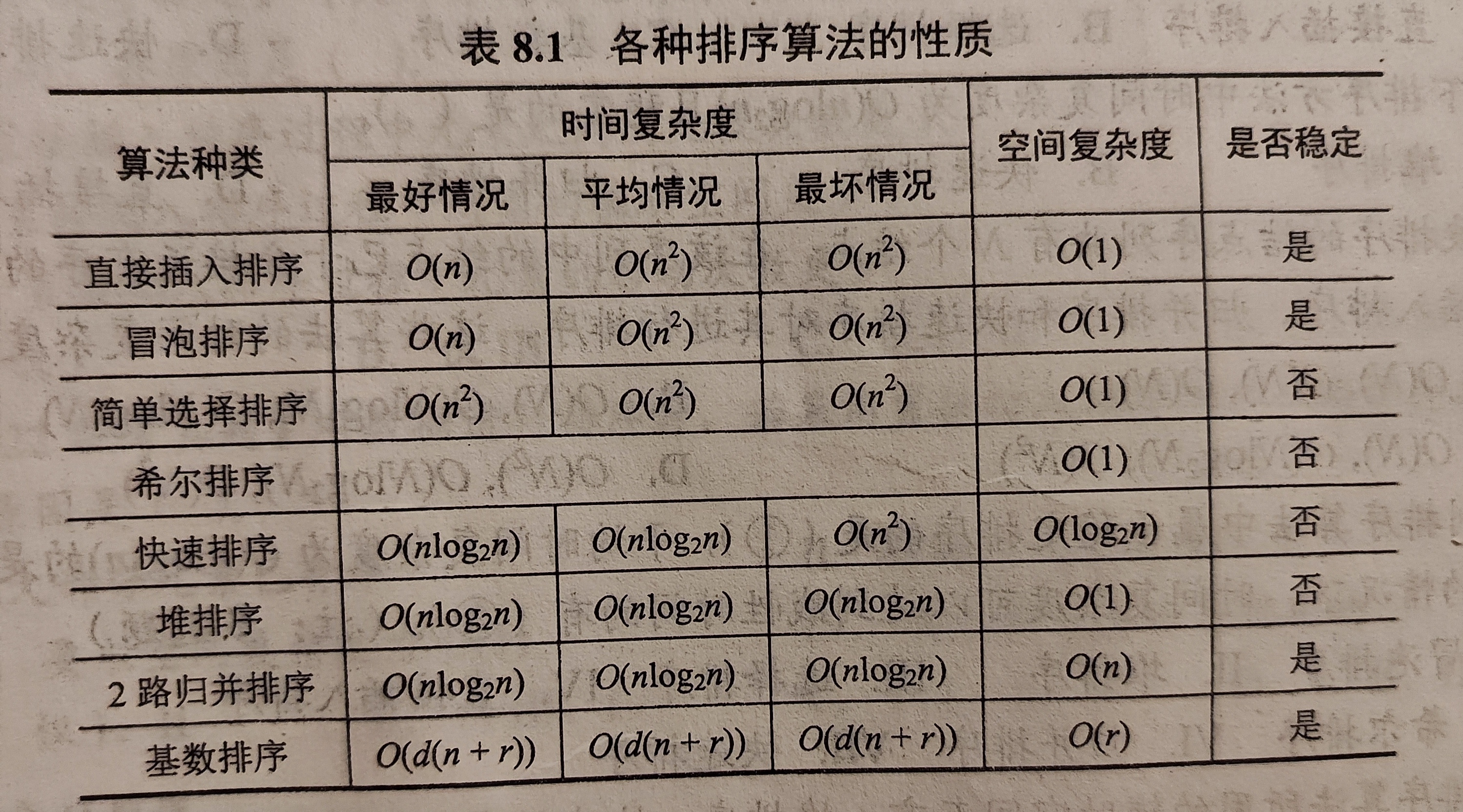
3.各算法的对比分析
1.时间复杂度
简单选择、直接插入、冒泡排序
平均情况下时间复杂度都为n^2,其特点是实现过程简单
直接插入和冒泡排序在最好情况下时间能达到n
简单选择的时间与序列初始状态无关
希尔排序是插入排序的改良,对于较大规模的数据效率较高,时间复杂度与步长的选择以及步长的改变策略有关。
堆排序的时间复杂度为nlog2n
堆排序对于数据量很大的情况比较适合,比如从1亿个数里选出前100个数
快速排序: 应用中的最优排序算法
最坏情况下时间为n^2,平均时间为nlog2n
归并排序
由于其特性,算法时间与序列初始状态无关,最坏最好和平均时间均为nlog2n
2.空间复杂度
简单选择、直接插入、折半插入、希尔排序、冒泡排序和堆排序都是就地排序,仅需常数个辅助空间。
快速排序基于分治法,需要递归栈,平均空间复杂度为log2n,最坏情况下可能为n
归并排序一般情况下需要借助辅助空间来完成归并,空间复杂度为n
3.稳定性
稳定:
插入排序、冒泡排序、归并排序、基数排序
不稳定:
简单选择、快速排序、希尔排序、堆排序
兼顾时间和稳定性的排序算法可以说只有归并排序
它是稳定排序,且平均时间为nlog2n
4.在应用中如何选择合适的排序算法

错题总结
基数排序在关键字的数位特别多的时候需要进行的趟数也会增多,这时候就不适用了
快速排序有两个容易记混的地方:
快速排序的空间复杂度很大(log2n),因为他是递归算法
快速排序适用于关键字大小分布均匀的情况,当结点已基本有序时,其效率反而会降低(nlog2n -> n^2)
空间复杂度不仅与用到的辅助空间有关,还与算法是否递归有关。
堆排序和希尔排序,这两种算法只适合顺序存储,因为这两种算法都是基于随机存取的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号