Python基本数据类型-string(字符串)
String(字符串)
1.字符串的组成
字符串,通俗的说就是字符组成的一串内容,例如'Python大法好'、'Y45160100'、'PG one'
划重点:''表示空字符串(空字符串就是字符串里没有内容)
字符串是不可变对象,至于什么是不可变对象
日后再说
字符串之所以区别于其他数据类型,是因为它是被包含在引号里面的
你可以用单引号,也可以用双引号
划重点:但是不能一边单引号,一边双引号!
我们看一下:
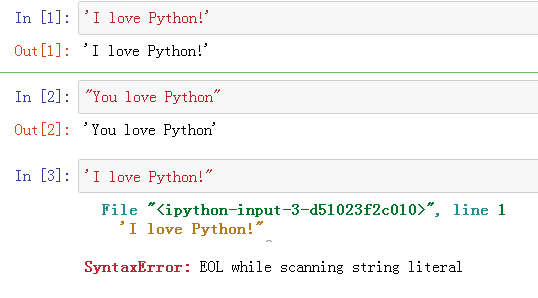
第三个:两边不一致所以出错了
当然,有时候我们必须单引号和双引号都得使用:

例如我相把她说的话和所有内容都用单引号嵌套,发现报错了
大家可以看到实际被单引号引用的是红色的内容,中间有一段是黑色的没被包括进去
这是因为,派森会从左到右自动扫描到一对单引号就把它俩匹配一起
为了解决这个问题,我们同时使用单引号和双引号

这样就可以啦~
其实连续三个单引号或者双引号也可以,不过一般我们不用
什么?你问为什么,你不觉得打这么多很累么,hhhhh
说到三个引号,我们要说一下注释了
2.注释
注释,是对书籍或文章的语汇、内容、背景、引文作介绍、评议的文字。
说得通俗一点就是多写点内容帮助理解
Python中的注释分为单行注释和多行注释:
单行注释
在每行代码前写一个井号,则这行代码不会被运行

运行之后发现报错,看一下报错信息,意思是a这个变量没被定义(因为你a=1定义的这行前面有个井号,是被注释了,程序不会执行)
其实大家发现没,之前上课讲到的Markdown和这里的注释好像功能相似
没错!就是这样!
如果我连续很多行都要注释呢?
小明:我知道,每行前面加一个#不就行了么,hhhh,我真是个天才
小明啊,如果我有10000行,你还这样做么?
小明无语凝噎。。。
好了,我们讲一下多行注释怎么弄
还记得刚才我们嫌弃的三个引号么
它就可以多行注释

a的内容确实被注释掉了,所以打印a的内容会报错
当然,除了三个单引号,三个双引号也是ok的

一直看报错的不太舒服,虽然我们是将用法
来看个正常运行的(没有注释):

Python中的字符串用单引号 ' 或双引号 " 括起来,同时使用反斜杠 \ 转义特殊字符。
字符串的截取的语法格式如下:
变量[头下标:尾下标]
索引值以 0 为开始值,-1 为从末尾的开始位置。

加号 + 是字符串的连接符, 星号 * 表示复制当前字符串,紧跟的数字为复制的次数。实例如下:
实例
执行以上程序会输出如下结果:
Runoob
Runoo
R
noo
noob
RunoobRunoob
RunoobTEST
Python 使用反斜杠(\)转义特殊字符,如果你不想让反斜杠发生转义,可以在字符串前面添加一个 r,表示原始字符串:
>>> print('Ru\noob')
Ru
oob
>>> print(r'Ru\noob')
Ru\noob
>>>
另外,反斜杠(\)可以作为续行符,表示下一行是上一行的延续。也可以使用 """...""" 或者 '''...''' 跨越多行。
注意,Python 没有单独的字符类型,一个字符就是长度为1的字符串。
实例
与 C 字符串不同的是,Python 字符串不能被改变。向一个索引位置赋值,比如word[0] = 'm'会导致错误。
注意:
- 1、反斜杠可以用来转义,使用r可以让反斜杠不发生转义。
- 2、字符串可以用+运算符连接在一起,用*运算符重复。
- 3、Python中的字符串有两种索引方式,从左往右以0开始,从右往左以-1开始。
- 4、Python中的字符串不能改变
3、格式化字符串,字符串中使用变量,简称为 f-string。Python 3.6 开始引入了 f-string。
有时想使用a变量的值给b使用,可在b的字符串前面加f
a='123' b=f'hello {a}' print(b)
使用input计算字符串
a = input('输入第一个数字:') b = input('输入第二个数字:') sum = a + b print(f'{a} + {b} = {sum}')
输入的数据为字符串,所以代码执行的是字符串连接操作,而不是加法运算
Python 解释器会将 {a} 替换为变量 name 的值运行结果如下:
hello 123
4、重要:访问字符串的元素
#优先掌握的操作:
#4.1、按索引取值(正向取+反向取) :只能取
#4.2、切片(顾头不顾尾,步长)
#4.3、长度len
#4.4、成员运算in和not in
#4.5、移除空白strip
#4.6、切分split
#4.7、循环
#要掌握的操作
#1、strip,lstrip,rstrip
#2、lower,upper
#3、startswith,endswith
#4、format的三种玩法
#5、split,rsplit
#6、join
#7、replace
#8、isdigit
4.1 按索引取值,元素的第一个下标从0开始,反向取下标-1
a='123'
print(a[0]) #返回:1
如果指定了一个负数作为下标,Python 将会从字符串的右边开始计算并返回相应的字符:
a='123' print(a[-1]) #返回:3
如果指定的下标超出了字符串的范围,将会返回一个错误:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: string index out of range
4.2 切片:string[start:end:step]
start 和 end 都是可选的。如果省略了 start,表示从下标 0 开始;如果省略了 end,表示返回后续的所有字符;step表示步长,即每多少步取一个元素
a='hello world'
print(a[2:7]) #llo w
a[2:7] 返回了一个从下标 0(包含)到不包含7的元素
a='hello world'
print(a[2:10:2]) #lowr
4.3 len(string)长度
a='hello world'
print(len(a)) #11
4.4、成员运算in和not in
'h' in 'hello'
True
in通常与if语句组合使用,下面是组合示例:
if 'h' in 'hello': print('h') h
not in是in的逆运算,其使用语法与in类似,只是结果相反,其使用格式如下:
'h' not in 'hello' False
4.5、移除空白strip,lstrip,rstrip
a='*hello*world**' print(a.strip('*')) #去除左右两边 print(a.lstrip('*')) #去除左边 print(a.rstrip('*')) #去除右边 结果如下: hello*world hello*world** *hello*world
4.6 split、rsplit
a='18:00:00::00:30' print(a.split(':')) #默认分隔符为空格 b='C:/a/b/c/d.txt' #只想拿到顶级目录 print(b.split('/',1)) c='a|b|c' print(c.rsplit('|',1)) #从右开始切分 结果如下: ['18', '00', '00', '', '00', '30'] ['C:', 'a', 'b/c/d.txt'] ['a|b', 'c']
4.7 lower,upper --》字符串转大小写
a='heLLo World' print(a.lower()) print(a.upper()) 结果如下: hello world HELLO WORLD
4.8 startswith,endswith-->判断以xx开头,以xx结尾,返回结果True\False
a='heLLo World' print(a.startswith('he')) print(a.endswith('r')) 结果如下: True False
4.9 format的三种玩法,{}不填写数字,默认从0开始输出顺序,填写数字,则从小到大输出 顺序
a='{} {} {}'.format('tom',18,'male') b='{1} {0} {1}'.format('tom',18,'male') c='{name} {age} {sex}'.format(sex='male',name='tom',age=18) print(a,type(a)) print(b,type(b)) print(c,type(c)) 结果如下: tom 18 male <class 'str'> 18 tom 18 <class 'str'> tom 18 male <class 'str'>
4.10 join
a='' print(a.join(['tom','say','hello','world'])) #可迭代对象必须都是字符串 print(a) 结果如下: tomsayhelloworld
4.11 replace 替换
a='xx:hello world' print(a.replace('xx','tom',1)) 结果如下: tom:hello world
4.12 isdigit:可以判断bytes和unicode类型,是最常用的用于于判断字符是否为"数字"的方法
a='xx:hello world' print(a.isdigit()) 结果如下: False
5、其他操作,了解即可
1、find,rfind,index,rindex,count 2、center,ljust,rjust,zfill 3、expandtabs 4、captalize,swapcase,title
5、is数字系列 6、is其他
#find,rfind,index,rindex,count a='egon say hello' print(a.find('o',1,3)) #顾头不顾尾,找不到则返回-1不会报错,找到了则显示索引 # print(name.index('e',2,4)) #同上,但是找不到会报错 print(a.count('e',1,3)) #顾头不顾尾,如果不指定范围则查找所有 #center,ljust,rjust,zfill b='egon' print(b.center(30,'-')) print(b.ljust(30,'*')) print(b.rjust(30,'*')) print(b.zfill(50)) #用0填充 #expandtabs name='egon\thello' print(name) print(name.expandtabs(1)) #captalize,swapcase,title print(name.capitalize()) #首字母大写 print(name.swapcase()) #大小写翻转 msg='egon say hi' print(msg.title()) #每个单词的首字母大写 #is数字系列 #在python3中 num1=b'4' #bytes num2=u'4' #unicode,python3中无需加u就是unicode num3='四' #中文数字 num4='Ⅳ' #罗马数字 #isdigt:bytes,unicode print(num1.isdigit()) #True print(num2.isdigit()) #True print(num3.isdigit()) #False print(num4.isdigit()) #False #isdecimal:uncicode #bytes类型无isdecimal方法 print(num2.isdecimal()) #True print(num3.isdecimal()) #False print(num4.isdecimal()) #False #isnumberic:unicode,中文数字,罗马数字 #bytes类型无isnumberic方法 print(num2.isnumeric()) #True print(num3.isnumeric()) #True print(num4.isnumeric()) #True #三者不能判断浮点数 num5='4.3' print(num5.isdigit()) print(num5.isdecimal()) print(num5.isnumeric()) ''' 总结: 最常用的是isdigit,可以判断bytes和unicode类型,这也是最常见的数字应用场景 如果要判断中文数字或罗马数字,则需要用到isnumeric ''' #is其他 print('===>') name='egon123' print(name.isalnum()) #字符串由字母或数字组成 print(name.isalpha()) #字符串只由字母组成 print(name.isidentifier()) print(name.islower()) print(name.isupper()) print(name.isspace()) print(name.istitle())


练习: # 写代码,有如下变量,请按照要求实现每个功能 (共6分,每小题各0.5分) name = " aleX" # 1) 移除 name 变量对应的值两边的空格,并输出处理结果 # 2) 判断 name 变量对应的值是否以 "al" 开头,并输出结果 # 3) 判断 name 变量对应的值是否以 "X" 结尾,并输出结果 # 4) 将 name 变量对应的值中的 “l” 替换为 “p”,并输出结果 # 5) 将 name 变量对应的值根据 “l” 分割,并输出结果。 # 6) 将 name 变量对应的值变大写,并输出结果 # 7) 将 name 变量对应的值变小写,并输出结果 # 8) 请输出 name 变量对应的值的第 2 个字符? # 9) 请输出 name 变量对应的值的前 3 个字符? # 10) 请输出 name 变量对应的值的后 2 个字符? # 11) 请输出 name 变量对应的值中 “e” 所在索引位置? # 12) 获取子序列,去掉最后一个字符。如: oldboy 则获取 oldbo。 # 写代码,有如下变量,请按照要求实现每个功能 (共6分,每小题各0.5分) name = " aleX" # 1) 移除 name 变量对应的值两边的空格,并输出处理结果 name = ' aleX' a=name.strip() print(a) # 2) 判断 name 变量对应的值是否以 "al" 开头,并输出结果 name=' aleX' if name.startswith(name): print(name) else: print('no') # 3) 判断 name 变量对应的值是否以 "X" 结尾,并输出结果 name=' aleX' if name.endswith(name): print(name) else: print('no') # 4) 将 name 变量对应的值中的 “l” 替换为 “p”,并输出结果 name=' aleX' print(name.replace('l','p')) # 5) 将 name 变量对应的值根据 “l” 分割,并输出结果。 name=' aleX' print(name.split('l')) # 6) 将 name 变量对应的值变大写,并输出结果 name=' aleX' print(name.upper()) # 7) 将 name 变量对应的值变小写,并输出结果 name=' aleX' print(name.lower()) # 8) 请输出 name 变量对应的值的第 2 个字符? name=' aleX' print(name[1]) # 9) 请输出 name 变量对应的值的前 3 个字符? name=' aleX' print(name[:3]) # 10) 请输出 name 变量对应的值的后 2 个字符? name=' aleX' print(name[-2:]) # 11) 请输出 name 变量对应的值中 “e” 所在索引位置? name=' aleX' print(name.index('e')) # 12) 获取子序列,去掉最后一个字符。如: oldboy 则获取 oldbo。 name=' aleX' a=name[:-1] print(a)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号