1:文字回答:按照自己的观点,总结语义分割面临的问题以及DeepLab系列的思想
1)语义分割中连续的池化或下采样会导致图像的分辨率大幅度下降,从而损失原始信息,且在上采样过程中难以恢复。现在越来越多的网络都在试图减少分辨率的损失,比如使用空洞卷积,或者用步长为2的卷积代替池化。
DeepLab引入了多尺度特征。
多尺度特征:通过设置不同参数的卷积层或池化层,提取到不同尺度的特征图。将这些特征图送入网络做融合,对于整个网络性能的提升很大。但是由于图像金字塔的多尺度输入,造成计算时保存了大量的梯度,从而导致对硬件的要求很高。多数论文是将网络进行多尺度训练,在测试阶段进行多尺度融合。如果网络遇到了瓶颈,可以考虑引入多尺度信息,有助于提高网络性能。
论文的优势:
1)参数同比减少,所以占比内存减小,速度快。
2)ResNet的引入,越深层的网络准确性越高。
3)连续卷积核池化不可避免地会带来分辨率降低,然而空洞卷积却在尽可能保证分辨率地情况下扩大视野。
4)提出了ASPP。
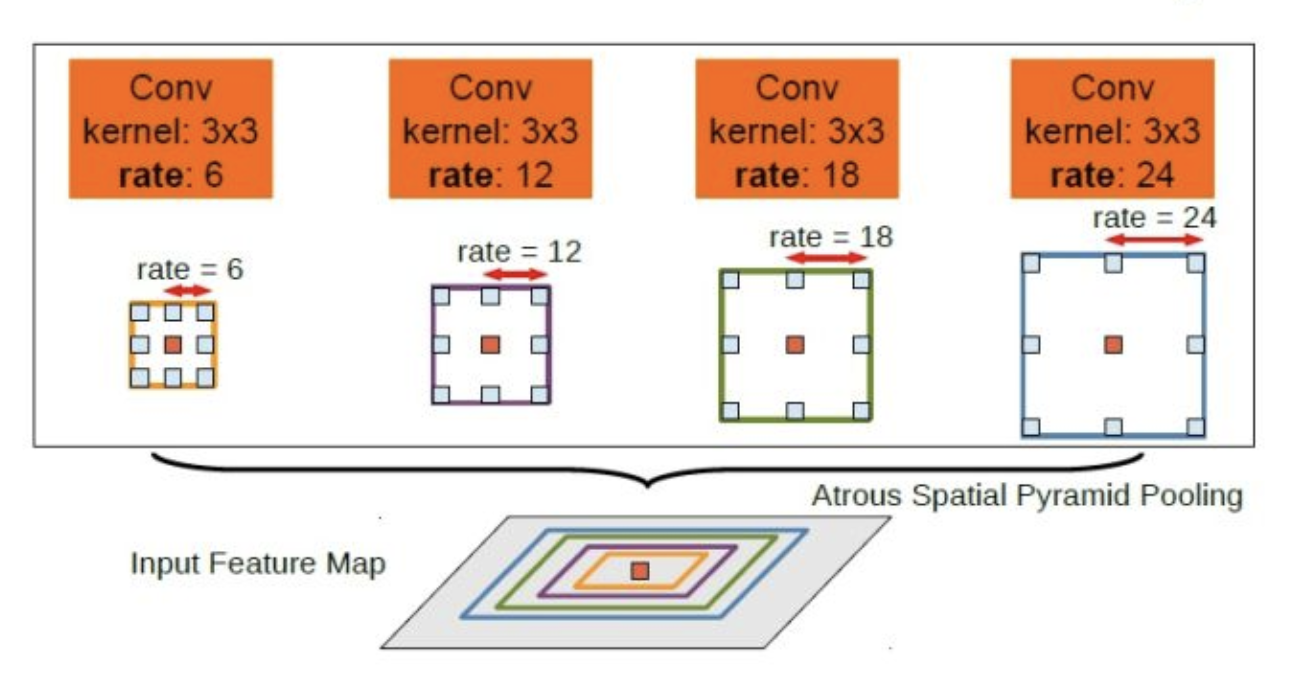
2:文字回答:怎样理解ASPP模块
ASPP是在SPP的基础上,用不同比例的膨胀卷积构造“空间金字塔结构”。它对所给定的输入以不同采样率的空洞卷积并行采样,相当于以多个比例捕捉图像的上下文。
![]()
3:文字回答:简述从v1到v3+,模型的发展历程
DeepLab v1:
1)结合了深度卷积神经网络和概率图模型的方法。 深度卷积神经网络是采样FCN的思想,修改VGG16网络,得到粗略映射图并插值到原图大小。
2)概率图模型(DenseCRFs):借用fully connected CRF对从DCNN得到的分割结果进行细节上的refine.
3)把全连接层(fc6、fc7、fc8)改成卷积层(端到端训练),把最后两个池化层(pool4、pool5)的步长2改为1,保证feature的分辨率。
4)把最后三个卷积层(conv5_1、conv5_2、conv5_3)的dilate rate设置为2, 且第一个全连接层的dilate rate设置为4(保持感受野)。
DeepLab v2:
1) 针对分辨率过低的特征图,文章通过修改最后几个池化操作,避免特征图分辨率损失过大,通过引入空洞卷积,在没有增加参数与计算量的情况下增大了感受野(基本同理v1)。
2)需要分割的目标具有多样的尺度大小。针对这个问题,文章参考了SPP的思想,使用了不同比例的膨胀卷积构造“空间金字塔结构”——ASPP。
3)DCNN网络对目标边界的分割准确度不高,文章引入CRF使得分割边界的定位更加准确,从而解决该问题。
DeepLab v3:
1) 本文重新讨论了空洞卷积的使用,在串行模块和空间金字塔池化的框架下,能够获取更大的感受野从而获取多尺度信息。
2)改进了ASPP模块,由于不同采样率的空洞卷积核BN层组成,采用了串行和并行的方式布局模块。
3)讨论了一个重要问题:使用大采样率的3x3的空洞卷积,因为图像边界响应无法捕捉远距离信息(小目标),会退化为1x1的卷积,因此将图像级特征融合到ASPP模块中。
DeepLab v3+:
1) 提出了一种编码器-解码器结构,采样DeepLab v3作为encoder, 添加decoder得到新的模型。取消了CRF后处理。
2)将Xception模型应用于分割任务,模型中广泛使用深度可分离卷积。
4:代码实现:用v3+实现对CamVid数据集的分割

 浙公网安备 33010602011771号
浙公网安备 33010602011771号