摘要:
  阅读全文
posted @ 2022-04-07 17:08
阿伟宝座
阅读(181)
评论(1)
推荐(0)
摘要:
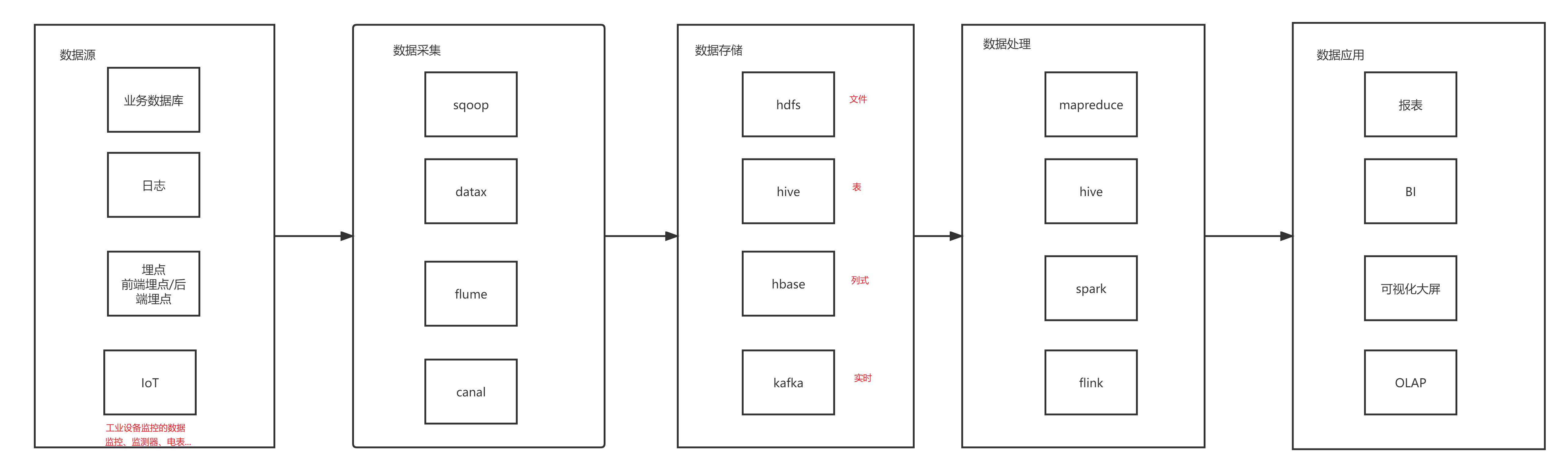
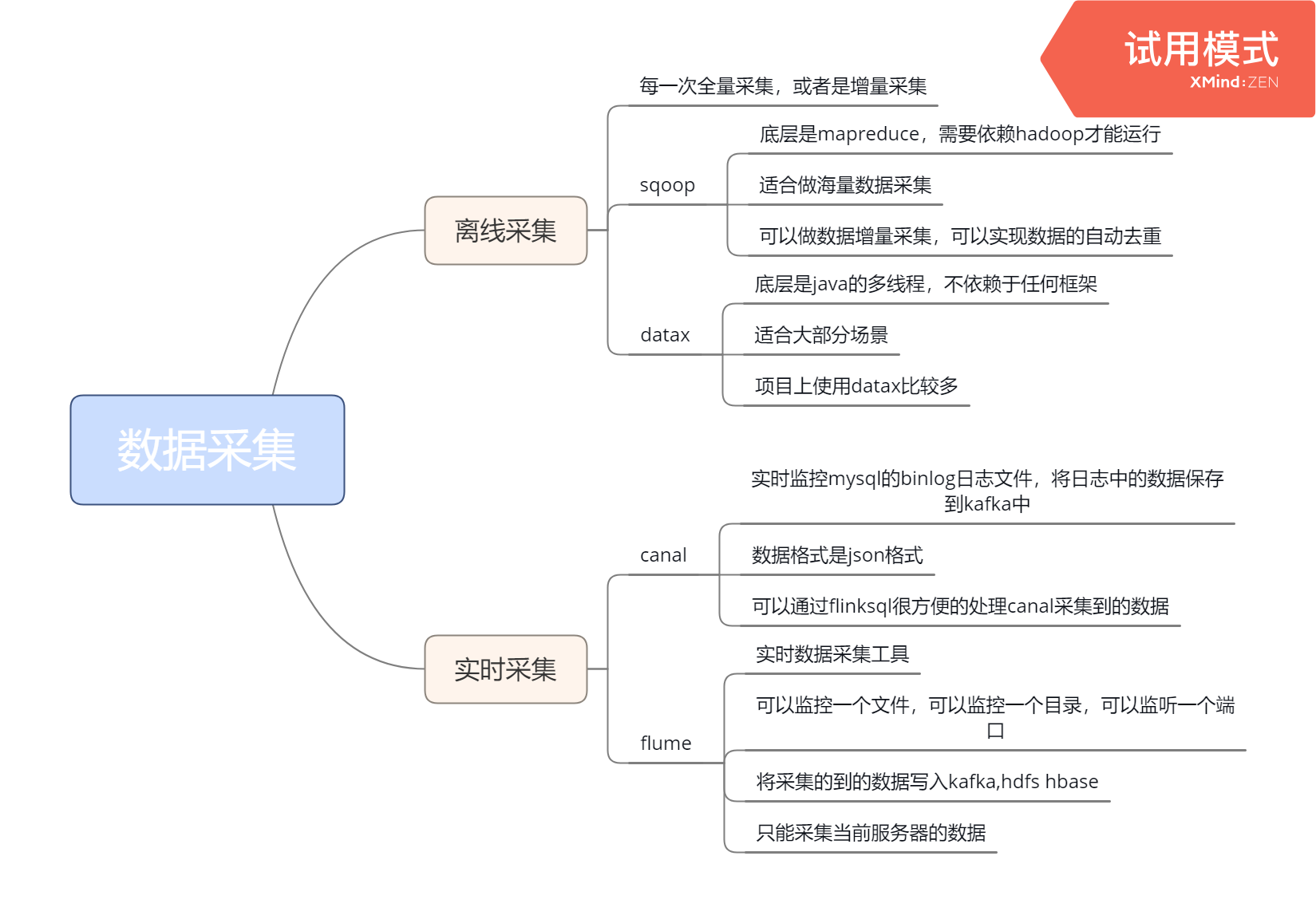
Flume的安装与使用 一、Flume 介绍 实时数据采集工具 可以监控一个文件,可以监控一个目录,可以监听一个端口 将采集到的数据写入Kafka、hdfs、hbase、…… 只能采集当前服务器中的数据 可以关注 GitHub 上的热度 flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传 阅读全文
posted @ 2022-04-07 16:59
阿伟宝座
阅读(723)
评论(0)
推荐(0)
摘要:
伪分布式集群 Linux 查看历史命令 history Linux查看进程运行的状态 top 也能查看集群资源 为了节省计算机的资源,我们将之前分布式的集群,改为伪分布式 伪分布式:即在一个节点上做分布式,可以节省资源 拍摄快照 在改伪分布式之前可以给我们的集群拍个快照,方便之后如果想要用回分布式集 阅读全文
posted @ 2022-04-07 16:02
阿伟宝座
阅读(149)
评论(0)
推荐(0)
摘要:
canal的安装与使用 canal,译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。(实时监控MySQL) canal的数据同步不是全量的,而是增量。基于binary log增量订阅和消费,canal可以做: 1、数据库镜像 2、数据库实时备份 3、索 阅读全文
posted @ 2022-04-07 16:01
阿伟宝座
阅读(840)
评论(0)
推荐(0)
摘要:
Kafka的搭建、启动、测试 一、kafka的搭建 1、上传压缩包到任意节点 2、解压,配置环境变量 所有节点都配置 #解压 cd /usr/local/soft tar -xvf kafka_2.11-1.0.0.tgz #配置环境变量 cd /usr/local/soft/kafka_2.11- 阅读全文
posted @ 2022-04-07 10:53
阿伟宝座
阅读(476)
评论(0)
推荐(0)
 浙公网安备 33010602011771号
浙公网安备 33010602011771号