canal的安装与使用
canal的安装与使用
canal,译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。(实时监控MySQL)
canal的数据同步不是全量的,而是增量。基于binary log增量订阅和消费,canal可以做:
1、数据库镜像
2、数据库实时备份
3、索引构建和实时维护
4、业务cache(缓存)刷新
5、带业务逻辑的增量数据处理
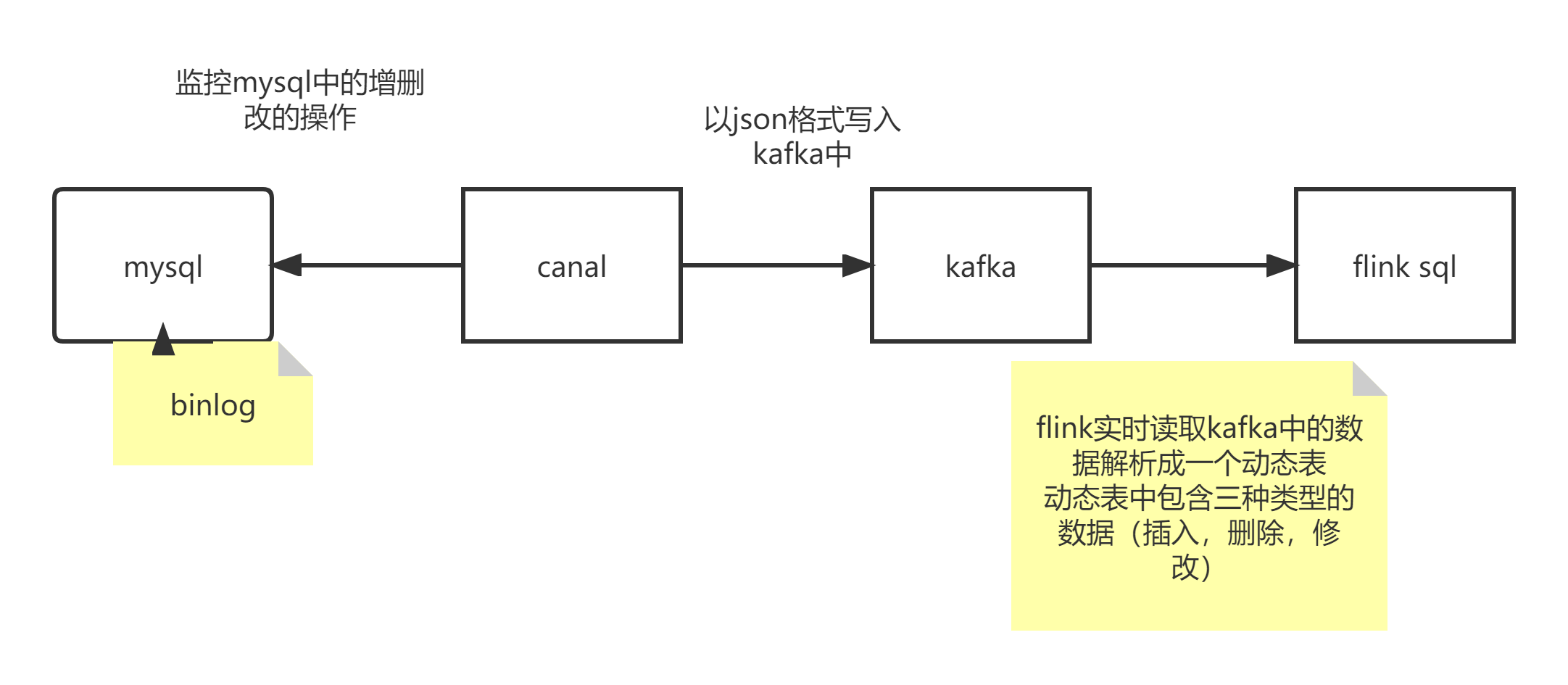
canal 的搭建
1、开启 MySQL binlog
默认没有开启,开启之后mysql的性能会下降
# 修改my.cnf
vim /etc/my.cnf
# my.cnf 这个文件可能会没有,没有的时候可以通过下面的代码复制一个
# cp /usr/share/mysql/my-medium.cnf /etc/my.cnf
# my-medium.cnf 和 my.cnf 实际上是一个东西,如果两个文件都没有,那就在 /etc/ 下面自己创建一个 my.cnf
在[mysqld]下增加几行配置,如下
[mysqld]
# 打开binlog
log-bin=mysql-bin
# 选择ROW(行)模式
binlog-format=ROW
# 配置MySQL replaction需要定义,不要和canal的slaveId重复
server_id=1
# 改完之后,需要看一下后面有没有和这三个新添加的配置重复的,重复的需要删除
# 改了配置文件之后,重启MySQL
service mysqld restart
# 验证:登录mysql,使用命令查看是否打开binlog模式:
show variables like 'log_bin';
# 结果
mysql> show variables like 'log_bin';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_bin | ON |
+---------------+-------+
1 row in set (0.11 sec)
2、上传解压canal
cd /usr/local/soft
# 创建一个解压目录
mkdir canal
tar -xvf /usr/local/soft/canal.deployer-1.1.4.tar.gz -C /usr/local/soft/canal
3、修改配置文件
vim /usr/local/soft/canal/conf/example/instance.properties
#修改以下几个地方
# mysql 地址
canal.instance.master.address=master:3306
# mysql用户名
canal.instance.dbUsername=root
# mysql密码
canal.instance.dbPassword=123456
# 数据写入 kafka 的topic
canal.mq.topic=example #在这下面插入一条动态topic
# 监控bigdata数据库,不同的表发送到对应表名的topic上
# bigdata -- MySQL数据库名
# ..* -- 为每一个表都动态的创建一个对应名称的topic
canal.mq.dynamicTopic=bigdata\\..*
-------------------------------------------------------------------------------
vim /usr/local/soft/canal/conf/canal.properties
#修改以下几个地方
# zk地址
canal.zkServers = master:2181,node1:2181,node2:2181
# 数据保存到kafka
canal.serverMode = kafka
# kafka集群地址
canal.mq.servers = master:9092,node1:9092,node2:9092
4、启动canal
# 启动canal之前需要先启动Kafka,启动kafka之前需要先启动zookeeper
# 启动zookeeper,需要在所有节点启动
zkServer.sh start
# 启动kafka
kafka-server-start.sh -daemon /usr/local/soft/kafka_2.11-1.0.0/config/server.properties
# 启动canal
cd /usr/local/soft/canal/bin
./startup.sh -- 启动
# 启动之后会有一个CanalLauncher进程
./restart.sh -- 重启
./stop.sh -- 停止
启动之后,只要数据库中有变化,canal就会自动的采集
5、canal测试使用
# 在 MySQL bigdata 数据库创建一个'订单表',并且执行几个简单的DML:
use bigdata;
# 创建表
CREATE TABLE `order`
(
id BIGINT UNIQUE PRIMARY KEY AUTO_INCREMENT COMMENT '主键',
order_id VARCHAR(64) COMMENT '订单ID',
amount DECIMAL(10, 2) COMMENT '订单金额',
create_time DATETIME COMMENT '创建时间',
UNIQUE uniq_order_id (`order_id`)
) COMMENT '订单表';
# 插入数据
INSERT INTO `order`(order_id, amount) VALUES ('10087', 999);
# 更新数据
UPDATE `order` SET amount = 99 WHERE order_id = '10087';
# 删除数据
DELETE FROM `order` WHERE order_id = '10087';
=====================================================================
# 可以利用Kafka的kafka-console-consumer或者Kafka Tools查看bigdata这个topic的数据:
kafka-topics.sh --list --zookeeper master:2181,node1:2181,node2:2181
# 结果
bigdata.order
# 使用Kafka消费一下bigdata.order的数据,查看数据的实时情况
kafka-console-consumer.sh --bootstrap-server master:9092,note01:9092,note2:9092 --from-beginning --topic bigdata.order
# 结果:返回的是一个json格式的数据(在MySQL中操作数据,这边就会更新数据)
======================================================================
# 使用flink sql读取canal-json格式的数据,构建动态表
# 1、启动flink集群
yarn-session.sh -jm 1024m -tm 1096m
@ 进入flink-sql的命令行
sql-client.sh embedded
# 动态表的表结构和数据库中表的结构保持一致
# 基于canal-json创建的动态表是一个不断更新的表,不是一个append表
CREATE TABLE canal_student (
id STRING,
name STRING,
age BIGINT,
gender STRING,
clazz STRING
) WITH (
'connector' = 'kafka',
'topic' = 'bigdata.student2',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'testGroup',
'format' = 'canal-json',
'scan.startup.mode' = 'earliest-offset',
'canal-json.ignore-parse-errors' = 'true' # 解析异常的数据自动跳过
);
select clazz,count(1) from canal_student group by clazz;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号