flink与spark执行的区别
flink与spark执行的区别
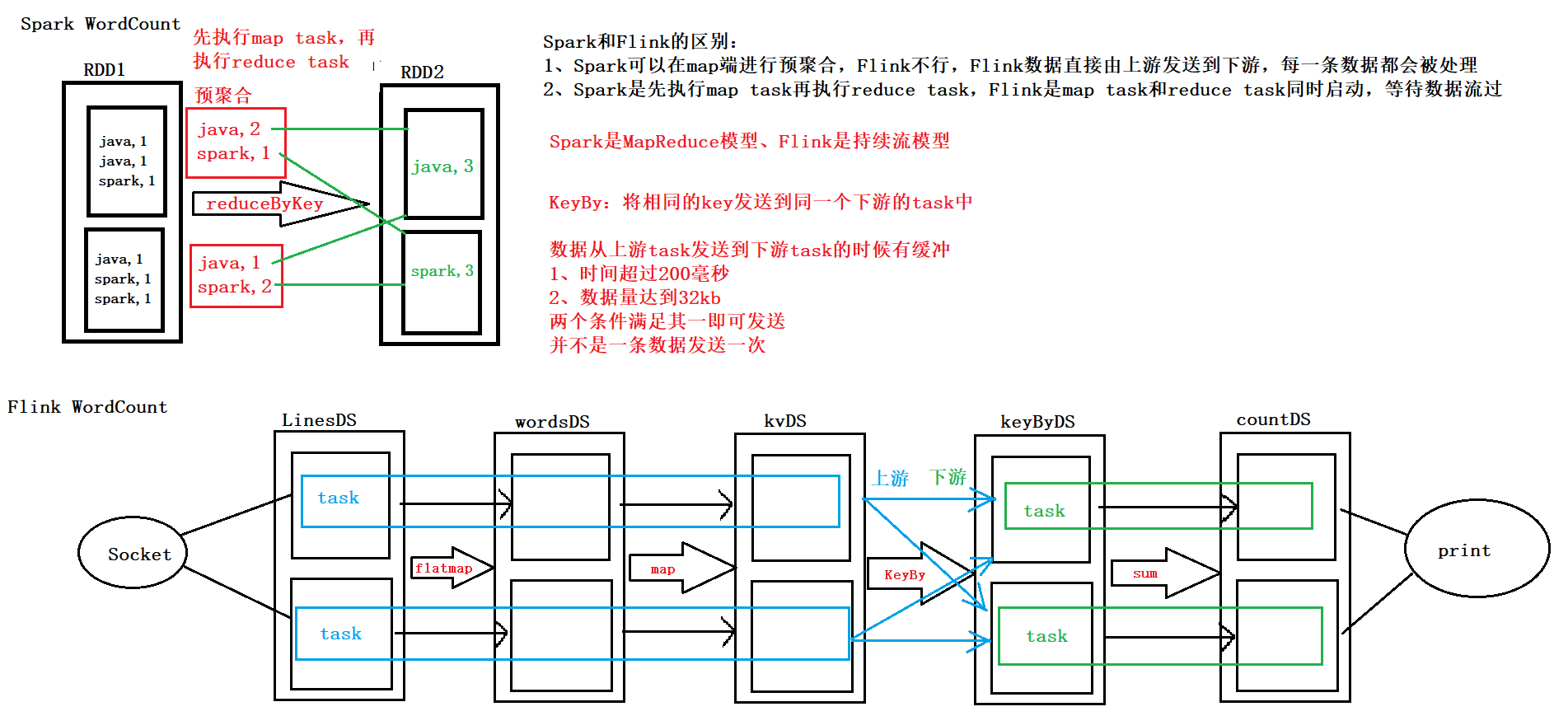
(1)spark可以在map端进行预聚合,flink却不可以;
flink数据直接发送到下游,并且每一条数据都会被处理
(2)spark先执行maptask,再执行reducetask;
flink是maptask和reducetask同时执行,等待数据过来
(3)spark是mapreduce模型
flink是持续流模型
flink与spark都是粗粒度资源调度(mapreduce是细粒度资源调度)
flink的keyBy将相同的key发送到同一个下游的task中;
从上游往下游发送数据,并不是一条数据发送一次
数据从上游task发送到下游task有缓冲
满足下面两个条件的一个,都会产生缓冲:
1、时间超过200ms
2、数据量达到32kb

 浙公网安备 33010602011771号
浙公网安备 33010602011771号