Flink流处理---WordCount:统计单词数量
Flink流处理---WordCount:统计单词数量
注意:导包的时候需要手动修改一下
修改为import org.apache.flink.streaming.api.scala._
package com.shujia.flink.core
import org.apache.flink.streaming.api.scala._
object Demo1WordCount {
def main(args: Array[String]): Unit = {
/**
* 1、创建flink的运行环境
* 这是flink程序的入口
*/
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//自定义并行度
env.setParallelism(2)
/**
* 2、读取数据
* DataStream相当于spark中的DStream
*/
val linesDS: DataStream[String] = env.socketTextStream("master", 8888)
//1、展开数据
val wordsDS: DataStream[String] = linesDS.flatMap(line => line.split(","))
//2、将展开的数据转成kv格式
val kvDS: DataStream[(String, Int)] = wordsDS.map((_, 1))
//3、对key进行分组----keyBy
val keyByDS: KeyedStream[(String, Int), String] = kvDS.keyBy(kv => kv._1)
//4、对value进行求和----sum,指定下标进行聚合
val countDS: DataStream[(String, Int)] = keyByDS.sum(1)
//打印结果
countDS.print()
/**
* 3、开启socket
* 在虚拟机中输入 nc -lk 8888 回车
*/
/**
* 4、启动flink程序
*/
env.execute("wordcount")
}
}
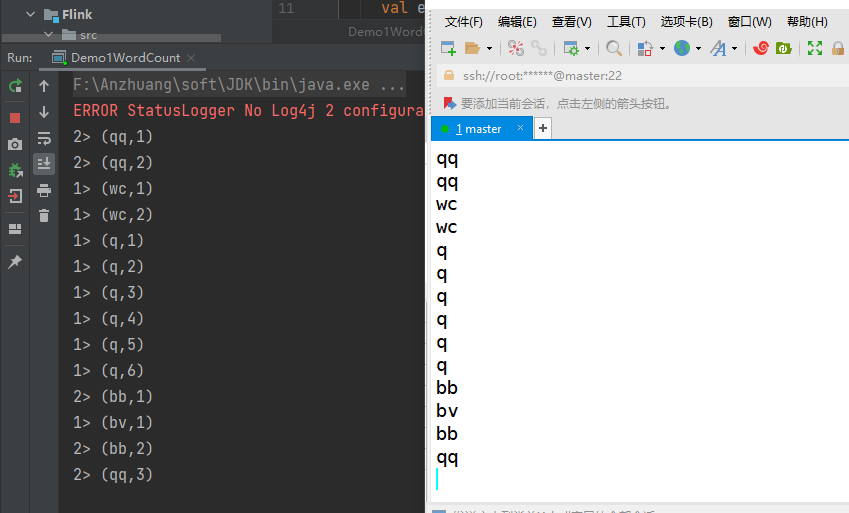
结论:当输入相同的数据,结果会自动累加
原因:flink中的算子本身就是有状态的算子,程序执行的是有状态计算
状态:之前的结果
有状态计算:计算的时候累加之前的结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号