Flink流处理测试
Flink流处理测试
package com.shujia.flink.core
import org.apache.flink.streaming.api.scala._
object Demo1WordCount {
def main(args: Array[String]): Unit = {
/**
* 1、创建flink的运行环境
* 这是flink程序的入口
*/
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
/**
* 2、读取数据
* DataStream相当于spark中的DStream
*/
val linesDS: DataStream[String] = env.socketTextStream("master", 8888)
/**
* 3、开启socket
* 在虚拟机中输入 nc -lk 8888 回车
*/
//先不做处理,直接打印处理
//流处理不能使用foreach循环打印
linesDS.print()
/**
* 4、启动flink程序(运行该代码)
*/
env.execute("wordcount")//给该程序起个名字
}
}
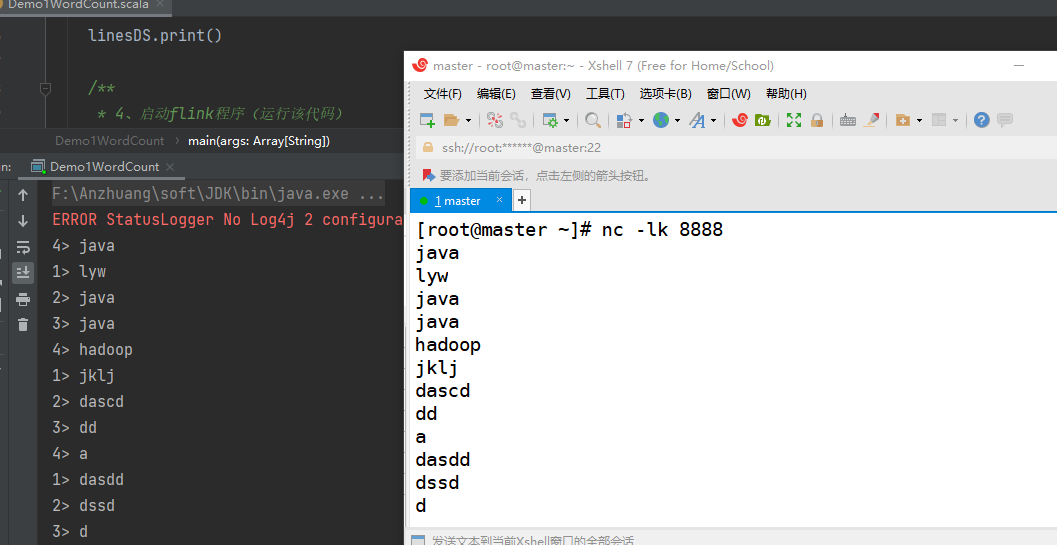
步骤:
- 1、创建flink的运行环境
- 2、读取数据
- 3、返回虚拟机中,输入
nc -lk 8888回车 - 4、编写启动flink程序的代码,然后运行整个代码
回到虚拟机中,输入一些数据,在IDEA中会对应生成;
因为我的电脑性能-逻辑处理器是4,所以在IDEA中的输出结果并行度编号有4种
Flink处理WordCount时,想要打印日志
(1)增加依赖
<dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-slf4j-impl</artifactId> <version>${log4j.version}</version> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-api</artifactId> <version>${log4j.version}</version> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-core</artifactId> <version>${log4j.version}</version> </dependency>(2)在IDEA的
resources目录中增加一个配置文件log4j2.properties(3)重新运行代码
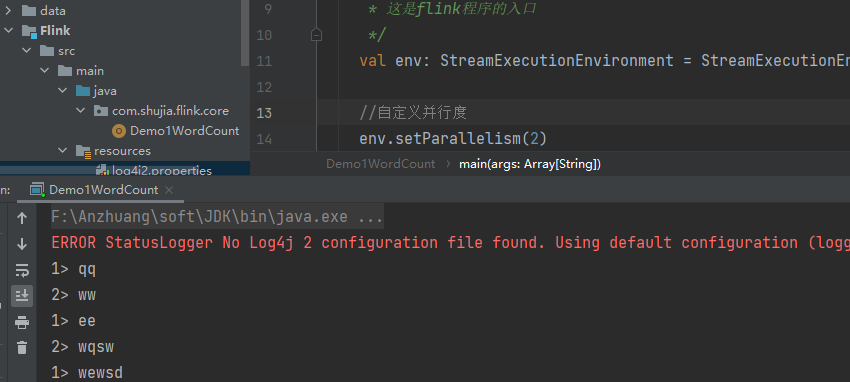
默认并行度是计算机核心数(逻辑处理器)有关,我们通过代码可以自定义并行度
//在读取数据之前设置并行度
env.setParallelism(2)
重新执行代码

 浙公网安备 33010602011771号
浙公网安备 33010602011771号