Hive的介绍
Hive的介绍
一、大数据体系
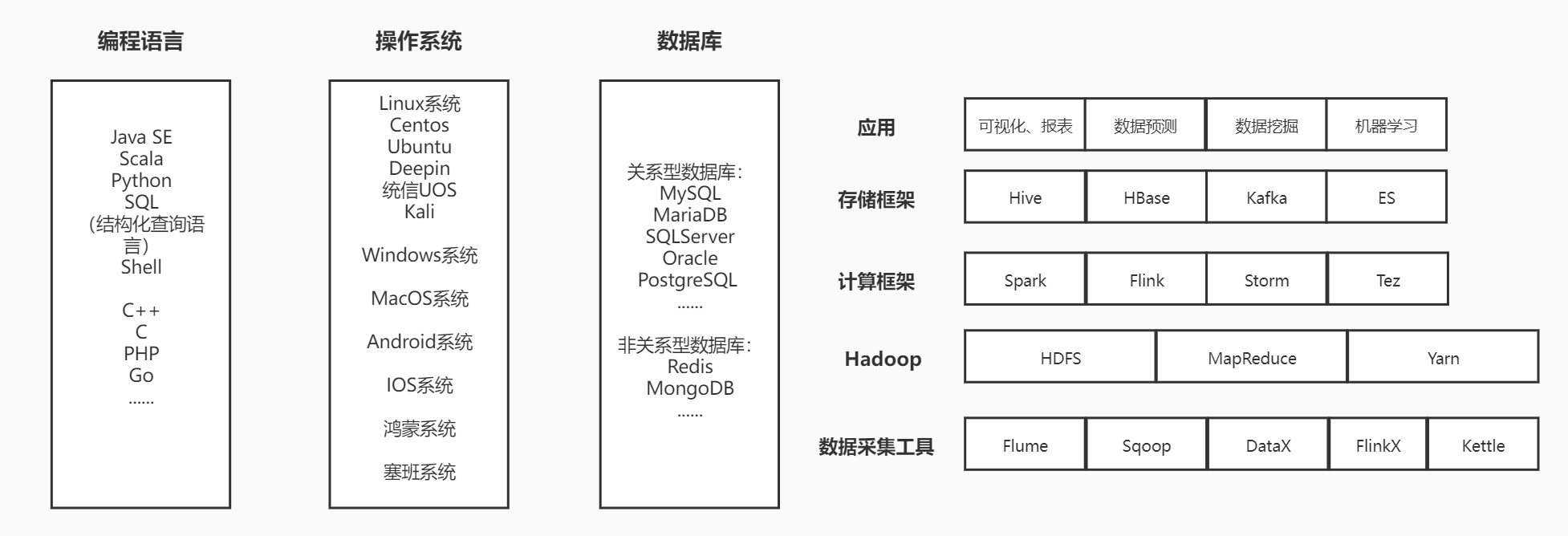
(1)同一系统,命令通用
(2)数据库的四大特性:ACID
也就是事物的四大特性:
原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)
二、Hive的概述
1、Hive是什么?
(1)Hive是建设数据仓库的工具;Hive的数据存在于HDFS
(2)Hive并不是数据仓库,它只是一个工具,数据仓库是一个概念
(3)Hive中有很多数据库,数据库管理每一条记录,数据仓库管理每一种数据库
数据仓库
名称为Data Warehouse,可简写为DW或DWH。
数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它出于分析性报告和决策支持目的而创建。为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量以及控制。
详细介绍Hive
(1)Hive是建立在Hadoop的数据仓库基础构架。
(2)Hive提供了一系列的工具ETL,
可以用来进行数据提取转化加载:萃取(extract)、转化(transform)、加载(loading)
(3)Hive基于HDFS进行存储、查询和分析
(4)HDFS的查询分析是由MapReduce来做的;
在Hive中定义了简单的类SQL查询语言,称为HQL,它允许熟悉SQL的用户查询数据,
(5)在执行的时候,通过写MapReduce可以完成任务;
在Hive中,直接来写SQL就可以来执行任务,更简单方便
(6)Hive是SQL解析引擎,它将SQL语句转译成MR任务,然后在Hadoop的Yarn上执行
(7)在Hive中有数据库DB,数据库DB中有表Table,Hive中的表其实就是HDFS的目录,
按表名把文件夹分开,Hive中表里的数据就是对应HDFS的目录下的数据;
(8)在Hive中还有一种表是分区表,分区表表示表下面又多了一个子目录,则分区值是子文件夹,可以直接在MR任务里使用这些数据。
(9)Hive相当于hadoop的客户端工具,可以直接操作HDFS上的数据;
部署时不一定放在集群管理节点中,也可以放在某个节点上,只要该节点可以访问Hadoop就行
Hive中的表含有表结构,表结构属于元数据(描述数据的数据)
Hive中的元数据存放于Mysql中,Hive中的数据存放于HDFS中(存放于HDFS中的某一个文件)
2、Hive与传统数据库比较
海量数据的分析计算----Hive合适,海量数据的查询----Hbase合适
| 查询语言 | HiveQL | SQL |
|---|---|---|
| 数据存储位置 | HDFS (元数据存在于MySQL) | 本地FS (/var/lib/mysql目录中) |
| 数据格式 | 用户定义 | 系统决定 |
| 数据更新 (增删改) | 1.x以后版本支持 (虽支持,但基本不用) | 支持 |
| 索引 | 新版本有(一般不使用) | 有 |
| 执行 | MapReduce | Executor |
| 执行延迟 | 高(执行慢) | 低(执行快) |
| 可扩展性 | 高 | 低 |
| 数据规模 | 大 | 小 |
详细介绍(了解一下)
(1)查询语言。类 SQL 的查询语言 HQL。熟悉 SQL 开发的开发者可以很方便的使用 Hive 进行开发。
(2)数据存储位置。所有 Hive 的数据都是存储在 HDFS 中的。而数据库则可以将数据保存在块设备或者本地文件系统中。
(3)数据格式。Hive 中没有定义专门的数据格式。而在数据库中,所有数据都会按照一定的组织存储,因此,数据库加载数据的过程会比较耗时。
(4)数据更新。Hive 对数据的改写和添加比较弱化,0.14版本之后支持,需要启动配置项。而数据库中的数据通常是需要经常进行修改的。
(5)索引。Hive 在加载数据的过程中不会对数据进行任何处理。因此访问延迟较高。数据库可以有很高的效率,较低的延迟。由于数据的访问延迟较高,决定了 Hive 不适合在线数据查询。
(6)执行计算。Hive 中执行是通过 MapReduce 来实现的而数据库通常有自己的执行引擎。
(7)数据规模。由于 Hive 建立在集群上并可以利用 MapReduce 进行并行计算,因此可以支持很大规模的数据;对应的,数据库可以支持的数据规模较小。
3、Hive的存储格式
(1)Hive的数据存储基于Hadoop HDFS
(2)Hive没有专门的数据文件格式,常见的有以下几种:textfile、orcfile、parquet
TextFile:
即正常的文本格式,是Hive默认文件存储格式
(1)大多数情况下源数据文件都是以text文件格式保存(便于查看验数和防止乱码)
(2)TextFile格式的表文件在HDFS上是明文,可用hadoop fs -cat命令查看,从HDFS上get下来后也可以直接读取。
(3)TextFile存储文件默认每一行就是一条记录,可以指定任意的分隔符进行字段间的分割。
(4)缺点是但这个格式无压缩,需要的存储空间很大。
(5)虽然可结合Gzip、Bzip2、Snappy等使用,但使用这种方式,Hive不能对数据进行切分,从而无法对数据进行并行操作。
一般只有与其他系统由数据交互的接口表采用TEXTFILE 格式,其他事实表和维度表都不建议使用
ORCFile:
存储格式:ORC文件格式
存储方式:列式文件存储
优点:有着很高的压缩比,并且对于MapReduce来说是可切分的(即可以进行分布式计算)
因此,在Hive中使用ORC作为表的文件存储格式,不仅可以很大程度的节省HDFS存储资源,而且对数据的查询和处理性能有着非常大的提升,因为ORC较其他文件格式压缩比高,查询任务的输入数据量减少,使用的Task也就减少了。ORC能很大程度的节省存储和计算资源,但它在读写时候需要消耗额外的CPU资源来压缩和解压缩,当然这部分的CPU消耗是非常少的。
Parquet:
存储方式:列式存储
较ORC的优势:支持嵌套结构的存储方式(类似于json格式)
了解一下:
通常我们使用关系数据库存储结构化数据,而关系数据库中使用数据模型都是扁平式的,
遇到诸如List、Map和自定义Struct的时候就需要用户在应用层解析。但是在大数据环境下,
通常数据的来源是服务端的埋点数据,很可能需要把程序中的某些对象内容作为输出的一部分,
而每一个对象都可能是嵌套的,所以如果能够原生的支持这种数据,这样在查询的时候就不需要额外的解析便能获得想要的结果。
Parquet支持嵌套结构的存储格式,并且使用了列式存储的方式提升查询性能。
Parquet仅仅是一种存储格式,它是语言、平台无关的,并且不需要和任何一种数据处理框架绑定。
parquet相较于orc的仅有优势:支持嵌套结构。
Parquet不支持update操作(数据写成后不可修改),不支持ACID(事物)等
RCFile(不常见):
存储格式:列文件存储
存储方式:行列存储相结合
优点:能够很好的压缩和快速的查询性能
缺点:写操作比较慢
两种二进制的存储格式(不常见,了解一下)
SequenceFile:
(1)SequenceFile是Hadoop API提供的一种二进制文件,将数据以<key,value>的形式序列化到文件中。
这种二进制文件内部使用Hadoop的标准的Writable 接口实现序列化和反序列化,
它与Hadoop API中的MapFile互相兼容的。
(2)Hive中的SequenceFile继承自Hadoop API 的SequenceFile,不过它的key为空,使用value存放实际的值,这样是为了避免MR在运行map阶段的排序过程。
(3)SequenceFile支持三种压缩选择:NONE, RECORD, BLOCK。 Record压缩率低,一般建议使用BLOCK压缩。 SequenceFile最重要的优点就是Hadoop原生支持较好,有API,但除此之外平平无奇,实际生产中不会使用。
Avro:
Avro是一种用于支持数据密集型的二进制文件格式。它的文件格式更为紧凑,若要读取大量数据时,Avro能够提供更好的序列化和反序列化性能。并且Avro数据文件天生是带Schema定义的,所以它不需要开发者在API 级别实现自己的Writable对象。Avro提供的机制使动态语言可以方便地处理Avro数据。最近多个Hadoop 子项目都支持Avro 数据格式,如Pig 、Hive、Flume、Sqoop和Hcatalog。
4、Hive的四大常用存储格式存储效率及执行速度对比
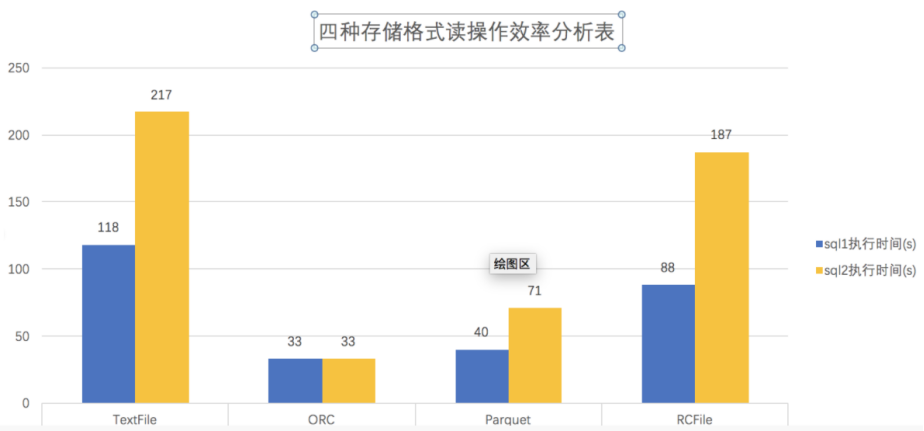
结论:ORCFile存储文件读操作效率最高
耗时比较:ORC<Parquet<RC<Text
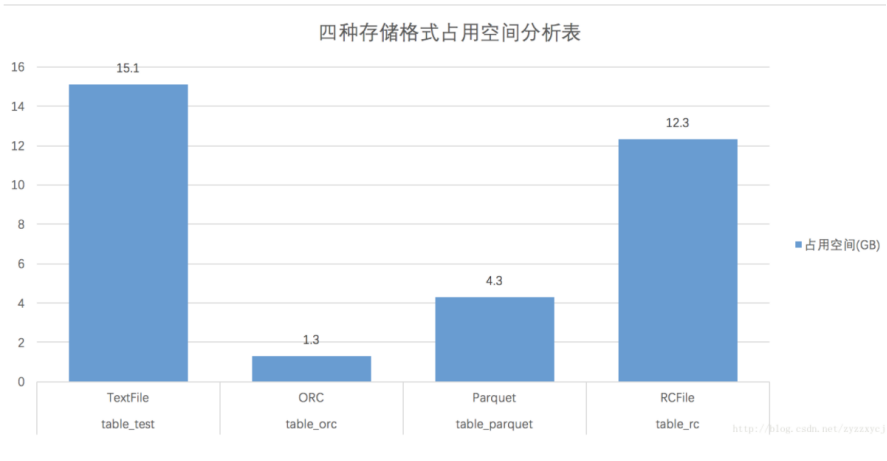
结论:ORCFile存储文件占用空间少,压缩效率高
占用空间:ORC<Parquet<RC<Text
5、Hive的操作客户端
操作
Mysql的客户端:shell(cli),JDBC(java),Navicat(基于JDBC)
Hive常用的两个客户端:CLI,JDBC/ODBC
(1)CLI,即Shell命令行
(2)JDBC/ODBC 是 Hive 的Java,与使用传统数据库JDBC的方式类似。
Hive将元数据存储在数据库中(metastore),目前只支持 mysql、derby(不常用)。
Hive中的元数据包括表的名字、列、分区、属性等,表的属性是否为外部表、表的数据所在目录等;
执行:
(1)由解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划(plan)的生成,
生成的查询计划存储在HDFS中,并在随后由MapReduce调用执行。
(2)Hive的数据存储在HDFS中,大部分的查询由MapReduce完成;
不涉及计算的不会产生MR任务
例如:select * from table 不会生成MapRedcue任务

 浙公网安备 33010602011771号
浙公网安备 33010602011771号