

AI 运维工程师的核心技能树:从基础到进阶的成长地图
核心提要:本文系统拆解 AI 运维工程师从“入门新手”到“高阶专家”的 3 大成长阶段,梳理各阶段核心技能、学习重点、实操场景与避坑指南,附可视化技能树与成长时间线,帮从业者清晰定位自身短板、规划提升路径,快速具备“模型稳定落地+系统高效运维”的核心能力。
在 AI 技术规模化落地的趋势下,AI 运维工程师已成为企业核心岗位——既要懂传统 IT 运维的“系统稳定保障”,又要通 AI 领域的“模型特性、数据逻辑”,是连接算法团队与业务落地的“桥梁”。但很多从业者面临“技能杂乱无章,不知道该先学什么、后补什么”的困境。本文按“基础→进阶→高阶”的成长逻辑,搭建系统化技能树,让成长路径一目了然。
一、基础阶段:筑牢地基,打通“IT 运维+AI 基础”
核心目标:具备 AI 项目基础运维能力,能独立完成“文件管理、进程监控、环境部署”等常规操作,理解 AI 项目基本流程。
核心技能模块(附学习重点+实操场景)
|
技能模块 |
核心学习重点 |
AI 运维专属实操场景 |
避坑点 |
|
Linux 基础命令 |
文件/目录操作(ls/cd/rsync 等)、进程管理(ps/kill/nohup)、日志分析(grep/awk/tail) |
1. 跨服务器同步大模型文件(rsync);2. 监控 GPU 训练进程(nvidia-smi);3. 提取训练日志中的 loss 指标(grep+awk) |
1. 避免直接用 |
|
AI 基础认知 |
核心概念(模型训练/推理、数据集/标签、GPU/显存)、主流框架(TensorFlow/PyTorch)基础 |
1. 区分训练进程与推理进程的资源需求差异;2. 识别模型 OOM(内存溢出)、数据格式错误等基础报错 |
1. 不用深入学习模型算法,但要懂“模型需要什么资源、依赖什么环境”;2. 重点记框架版本兼容性(如 PyTorch 1.12 不兼容 CUDA 12.0) |
|
基础运维工具 |
Docker 容器化、SSH 远程操作、基础监控(Prometheus 入门) |
1. 用 Docker 封装 PyTorch 训练环境,避免“本地能跑、服务器报错”;2. 用 SSH 远程启动模型训练脚本(nohup) |
1. Docker 镜像构建时,清理冗余依赖(减少镜像大小);2. SSH 断开后进程中断,必须搭配 nohup+& 后台运行 |
|
数据基础 |
数据格式(CSV/JSON/TFRecord)、数据质量校验(缺失值/异常值排查) |
1. 校验训练数据集完整性(wc -l 统计行数);2. 转换数据格式(如 CSV 转 TFRecord) |
1. 处理用户隐私数据时,先做脱敏(如手机号隐藏中间 4 位);2. 大数据集(>10GB)优先分块存储,避免单文件过大 |
必备工具栈
-
命令行工具:Linux 内置命令(核心)、htop(资源监控增强版)、nvidia-smi(GPU 监控)
-
容器工具:Docker(环境封装)、Docker Compose(多容器编排)
-
基础监控:Prometheus+Grafana(可视化监控系统资源)
阶段达标标准
-
能独立部署 Python+PyTorch/TensorFlow 基础环境;
-
能通过命令行完成模型文件传输、训练进程监控、基础日志排查;
-
能解决“环境依赖冲突、显存不足、文件传输损坏”等常见基础问题。
二、进阶阶段:聚焦核心,深耕“模型运维+监控体系”
核心目标:从“基础操作”转向“问题解决”,能搭建 AI 专属监控体系、处理模型部署与迭代中的核心故障,理解 AI 运维的特殊需求。
核心技能模块(附学习重点+实操场景)
|
技能模块 |
核心学习重点 |
AI 运维专属实操场景 |
避坑点 |
|
模型运维核心 |
模型部署(API 封装、TensorRT 加速)、模型版本管理、模型漂移监控 |
1. 用 FastAPI 封装推理模型为 API 接口;2. 用 MLflow 管理模型版本(支持回滚);3. 用 PSI 指标监控数据分布变化(识别模型漂移) |
1. 模型部署前先做轻量化(如 TensorRT 加速),避免推理延迟过高;2. 模型版本标签要规范(如 model_v2.1_20240601),方便追溯 |
|
云原生与容器编排 |
K8s 核心功能(部署/扩缩容/滚动更新)、AI 任务调度(Kubeflow) |
1. 用 K8s 部署高并发推理服务(支持自动扩缩容);2. 用 Kubeflow 管理分布式训练任务 |
1. 避免 K8s 资源配置过高(如 GPU 实例过多)导致成本浪费;2. 分布式训练需配置共享存储(如 NFS),确保数据同步 |
|
监控告警体系 |
全链路监控(系统层+模型层)、告警降噪、可视化面板搭建 |
1. 监控维度:GPU 使用率(阈值 85%)、模型推理延迟(阈值 500ms)、准确率波动(阈值±5%);2. 用 Grafana 搭建 AI 专属监控面板 |
1. 不要只盯系统指标(CPU/GPU),忽略模型指标(准确率/漂移);2. 告警设置分级(一级故障 5 分钟响应,二级故障 30 分钟响应) |
|
故障排查进阶 |
常见故障定位(模型加载失败、推理延迟过高、训练中断)、日志分析进阶 |
1. 排查“模型加载失败”:先校验模型文件完整性(md5sum),再检查框架版本兼容性;2. 解决“推理延迟高”:优化 GPU 显存分配、模型轻量化 |
1. 故障排查按“先系统后模型”逻辑:先查资源(CPU/GPU/网络),再查模型本身;2. 保留故障日志(如 |
必备工具栈
-
模型运维:MLflow(模型版本管理)、TensorRT(模型加速)、FastAPI/Flask(API 封装)
-
云原生工具:Kubernetes(容器编排)、Kubeflow(AI 任务调度)、NFS(共享存储)
-
监控工具:Prometheus+Grafana(监控核心)、ELK 栈(日志收集分析)、PSI 计算工具(模型漂移监控)
阶段达标标准
-
能独立搭建 AI 项目全链路监控体系,覆盖“系统+模型”双维度;
-
能解决 80% 常见故障(如模型漂移、推理延迟高、分布式训练同步失败);
-
能通过 K8s 实现推理服务的高可用部署与自动扩缩容。
三、高阶阶段:架构思维,实现“自动化+平台化+跨团队协同”
核心目标:从“单点运维”转向“体系化建设”,能设计 AI 运维平台、制定运维规范,推动跨团队协同,兼顾成本优化与安全合规。
核心技能模块(附学习重点+实操场景)
|
技能模块 |
核心学习重点 |
AI 运维专属实操场景 |
避坑点 |
|
AI 运维平台化 |
平台架构设计(数据采集→监控→告警→处置)、自动化脚本开发(Shell/Python) |
1. 开发自动化运维脚本:模型自动迭代(新数据→训练→部署→回滚);2. 搭建 AI 运维平台,集成监控面板、故障工单、资源调度功能 |
1. 平台设计先满足核心需求(如自动化部署),再迭代扩展功能,避免“大而全”导致落地困难;2. 脚本需加异常捕获(如训练失败自动触发告警) |
|
成本优化 |
资源动态调度、闲置资源回收、云资源选型(按需付费/预留实例) |
1. 配置 K8s 动态扩缩容规则(高峰扩容、低峰缩容);2. 训练任务错峰执行(避开业务高峰,利用低价时段资源) |
1. 成本优化不能牺牲稳定性(如低峰缩容不能关闭核心推理服务);2. 定期统计资源使用率(如 GPU 平均使用率<30% 需调整配置) |
|
安全合规 |
数据安全(加密传输/存储)、模型安全(访问控制/防泄露)、合规审计 |
1. 训练数据传输用 HTTPS 加密,存储用 AES 加密;2. 模型访问设置 RBAC 权限(仅算法/运维人员可查看) |
1. 合规需提前规划(如 GDPR/个人信息保护法),避免事后整改;2. 定期做安全审计(如检查模型访问日志,排查异常访问) |
|
跨团队协同 |
运维规范制定、与算法/业务团队协作流程、故障复盘机制 |
1. 制定《AI 模型部署规范》《日志输出标准》,统一跨团队协作口径;2. 组织故障复盘会(算法+运维+业务),输出改进措施 |
1. 规范要“落地可行”(如日志格式明确字段要求),避免空泛;2. 协作中要明确责任边界(如数据质量问题由算法团队负责,资源问题由运维负责) |
必备工具栈
-
自动化工具:Python(脚本开发)、Airflow(任务调度)、Ansible(批量操作)
-
平台化工具:Django/Flask(平台开发)、MySQL/Elasticsearch(数据存储)
-
安全工具:SSL 证书(数据加密)、RBAC 权限管理工具、合规审计工具
-
协同工具:Jira(工单管理)、Confluence(规范文档)
阶段达标标准
-
能设计并落地 AI 运维自动化平台,减少 50% 重复性运维工作;
-
能制定完善的 AI 运维规范与安全合规体系,支持多团队协同;
-
能通过资源优化降低 30% 以上 AI 项目运维成本,同时保障 99.9% 系统可用性。
四、AI 运维核心技能树可视化
1. 技能树树形图

2. 成长路径时间线(清晰标注阶段目标与关键节点)
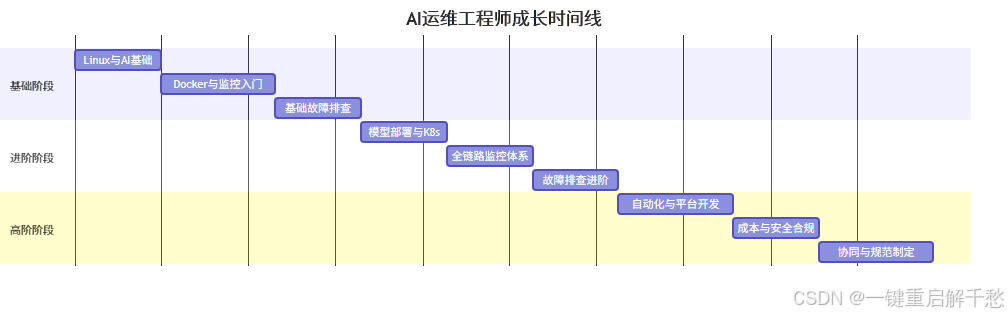

五、术语小词典
-
模型漂移:模型输入数据分布或业务场景变化,导致性能(准确率/召回率)下降的现象;
-
TensorRT:NVIDIA 推出的模型加速工具,可提升 GPU 推理效率,降低延迟;
-
Kubeflow:基于 K8s 的 AI 任务调度平台,支持分布式训练、模型部署等全流程;
-
PSI(群体稳定性指标):衡量数据分布变化的核心指标,PSI<0.1 表示数据稳定,PSI>0.2 需警惕模型漂移;
-
RBAC:基于角色的访问控制,用于管理模型、数据的访问权限,保障安全;
-
OOM(Out of Memory):内存/显存溢出,AI 训练/推理中常见故障,多因资源配置不足或模型过大导致。
六、常见成长误区(避坑指南)
-
误区 1:只学 AI 算法,忽视运维基础解决:AI 运维的核心是“运维”,算法仅需基础认知,重点先夯实 Linux、Docker、监控等运维技能,再补充 AI 领域特性。
-
误区 2:追求“全栈”,所有工具都学解决:按阶段聚焦核心工具(基础阶段重点学 Docker,进阶阶段重点学 K8s,高阶阶段重点学 Python 脚本开发),避免“样样懂、样样不精”。
-
误区 3:只做操作,不总结规范解决:每解决一个故障、完成一个项目,都要记录“操作步骤、问题原因、改进措施”,积累到一定阶段整理成规范,形成个人方法论。
-
误区 4:忽视成本与合规,只关注稳定性解决:高阶 AI 运维需兼顾“稳定+成本+合规”,比如资源配置避免“过度预留”,数据处理提前考虑隐私保护,否则会导致项目落地受阻。
总结
AI 运维工程师的成长,本质是“运维基础+AI 特性+架构思维”的逐步升级——基础阶段打通“能干活”的底线,进阶阶段聚焦“干得好”的核心,高阶阶段实现“干得巧”的突破。不用急于求成,按阶段聚焦核心技能,结合实操场景积累经验,再通过可视化技能树和时间线校准方向,就能稳步从“新手”成长为“不可替代的专家”。
随着 AI 技术的持续普及,具备“系统化技能+场景化经验”的 AI 运维工程师,将成为企业数字化转型的核心稀缺人才。建议将本文技能树作为“成长地图”,定期复盘自身能力短板,针对性补充,同时保持对新技术(如大模型运维、边缘 AI 运维)的关注,持续迭代技能体系。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号