

Prometheus 入门:快速搭建基础监控,监控 CPU / 内存指标
核心提要:本文以“快速落地”为核心目标,手把手教你搭建 Prometheus 基础监控体系,实现对主机 CPU、内存指标的采集、存储与可视化展示。全程基于 Linux 环境(新手友好),涵盖 Prometheus Server、Node Exporter、Grafana 三大核心组件的安装、配置与联动,避开入门常见坑,确保你在 1 小时内完成从“0 到 1”的监控搭建。
Prometheus 是一款开源的时序数据库监控系统,核心优势在于轻量级、易部署、支持自定义指标采集,而 Node Exporter 是 Prometheus 生态中专门用于采集主机系统指标(CPU、内存、磁盘、网络等)的工具,Grafana 则用于将 Prometheus 存储的时序数据转化为直观的可视化面板,三者协同构成“采集-存储-可视化”的基础监控闭环。
一、实操前置准备
1. 必备环境与工具
|
组件 |
作用 |
适用系统 |
核心端口 |
|
Prometheus Server |
核心监控服务器(拉取、存储指标) |
Linux(CentOS 7+/Ubuntu 18.04+ 推荐) |
9090(默认,可自定义) |
|
Node Exporter |
采集主机 CPU/内存等系统指标 |
与 Prometheus 同服务器(单机测试) |
9100(默认,可自定义) |
|
Grafana |
可视化监控面板(展示 CPU/内存指标) |
与 Prometheus 同服务器(单机测试) |
3000(默认,可自定义) |
|
辅助工具 |
终端(Xshell/SSH)、浏览器(访问 Web 界面) |
- |
- |
2. 环境前提
-
服务器已关闭防火墙(或开放对应端口:9090、9100、3000)
# CentOS 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
# Ubuntu 关闭防火墙
ufw disable
-
服务器已安装 wget(用于下载安装包)
# CentOS 安装 wget
yum install wget -y
# Ubuntu 安装 wget
apt install wget -y
二、核心概念快速拆解(新手必知)
-
Prometheus Server:监控核心,负责从 Node Exporter 拉取指标数据、存储到本地时序数据库、提供 PromQL 查询接口。
-
Node Exporter:指标采集器,运行在目标主机上,暴露
/metrics接口供 Prometheus 拉取 CPU、内存等系统指标。 -
Grafana:可视化工具,通过对接 Prometheus 数据源,将枯燥的指标数据转化为折线图、仪表盘等直观展示。
-
监控目标:需要被监控的对象(本文中即运行 Node Exporter 的主机),Prometheus 通过配置文件指定监控目标。
-
PromQL:Prometheus 专属查询语言,用于筛选、聚合指标数据(如查询 CPU 使用率、内存使用率)。
三、操作步骤
步骤 1:安装并启动 Node Exporter(采集 CPU/内存指标)
Node Exporter 是采集主机系统指标的核心,先安装它才能获取 CPU、内存数据。
1. 下载并解压 Node Exporter
# 1. 创建工作目录(统一存放监控组件)
mkdir -p /opt/prometheus
cd /opt/prometheus
# 2. 下载 Node Exporter(选择稳定版本,此处以 v1.6.1 为例)
wget https://github.com/prometheus/node_exporter/releases/download/v1.6.1/node_exporter-1.6.1.linux-amd64.tar.gz
# 3. 解压安装包
tar -zxvf node_exporter-1.6.1.linux-amd64.tar.gz
# 4. 重命名目录(简化后续操作)
mv node_exporter-1.6.1.linux-amd64 node_exporter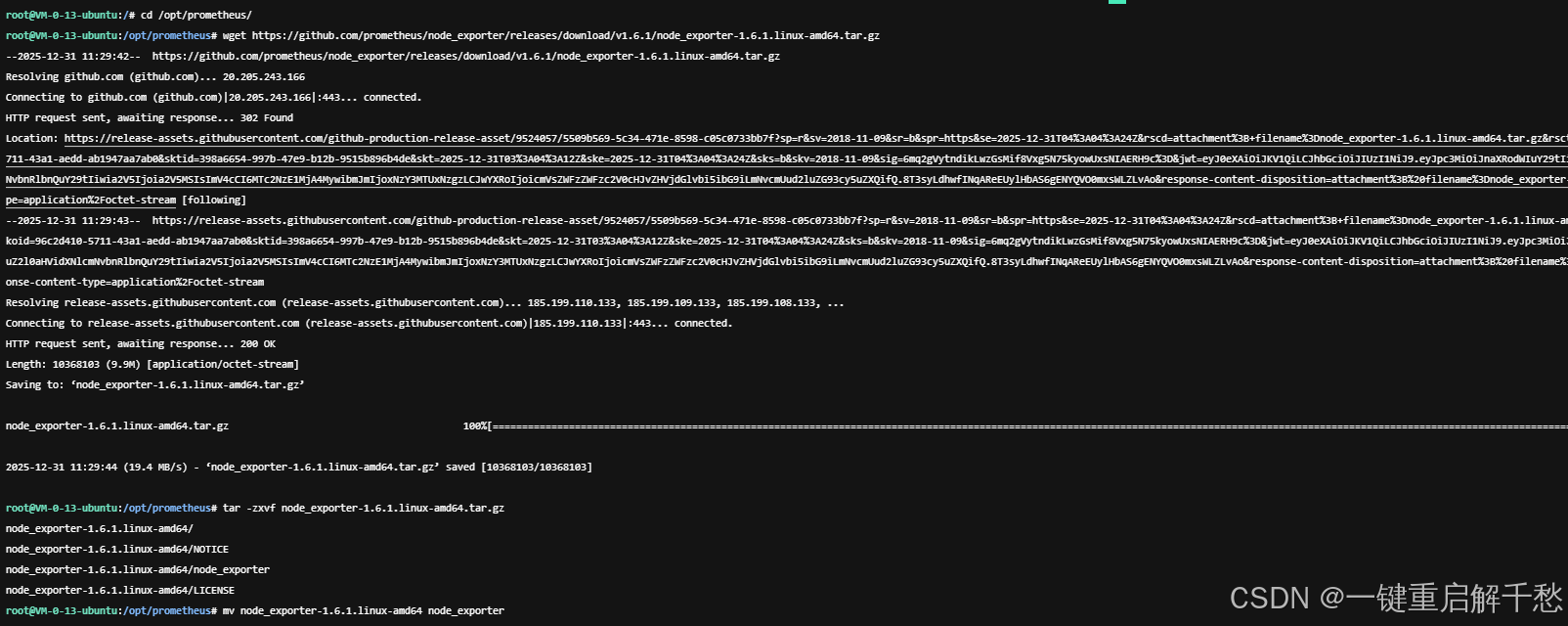
2. 启动 Node Exporter(后台运行,开机自启)
# 1. 后台启动 Node Exporter
nohup /opt/prometheus/node_exporter/node_exporter > /opt/prometheus/node_exporter/nohup.out 2>&1 &
# 2. 验证启动是否成功(查看 9100 端口是否被占用)
netstat -tnlp | grep 9100
# 预期输出:看到 node_exporter 进程占用 9100 端口
# 3. 验证指标是否可访问(访问 /metrics 接口)
curl http://localhost:9100/metrics
# 预期输出:返回大量系统指标(如 node_cpu_usage、node_memory_usage 相关指标)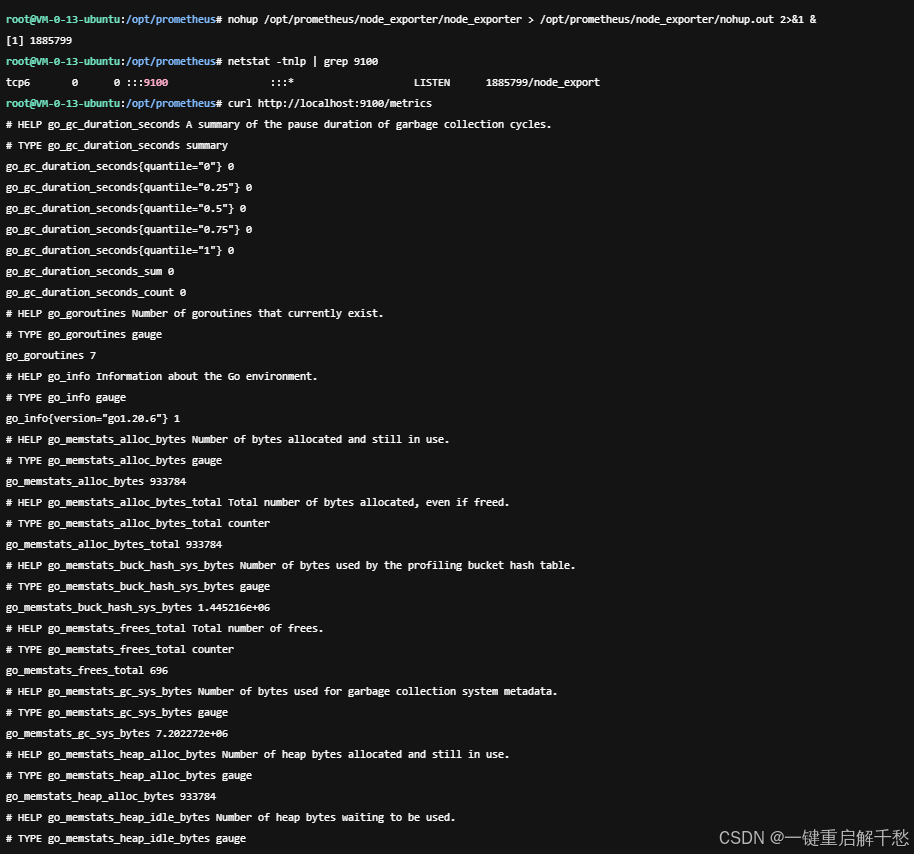
3. 关键说明
-
Node Exporter 无需额外配置,启动后即可采集系统指标。
-
nohup命令确保进程在终端断开后仍能后台运行。 -
若 9100 端口被占用,可通过
--web.listen-address指定端口,如:./node_exporter --web.listen-address=":9101"
步骤 2:安装并配置 Prometheus Server(拉取/存储指标)
1. 下载并解压 Prometheus Server
# 1. 进入工作目录
cd /opt/prometheus
# 2. 下载 Prometheus Server(稳定版本 v2.45.0 为例)
wget https://github.com/prometheus/prometheus/releases/download/v2.45.0/prometheus-2.45.0.linux-amd64.tar.gz
# 3. 解压安装包
tar -zxvf prometheus-2.45.0.linux-amd64.tar.gz
# 4. 重命名目录
mv prometheus-2.45.0.linux-amd64 prometheus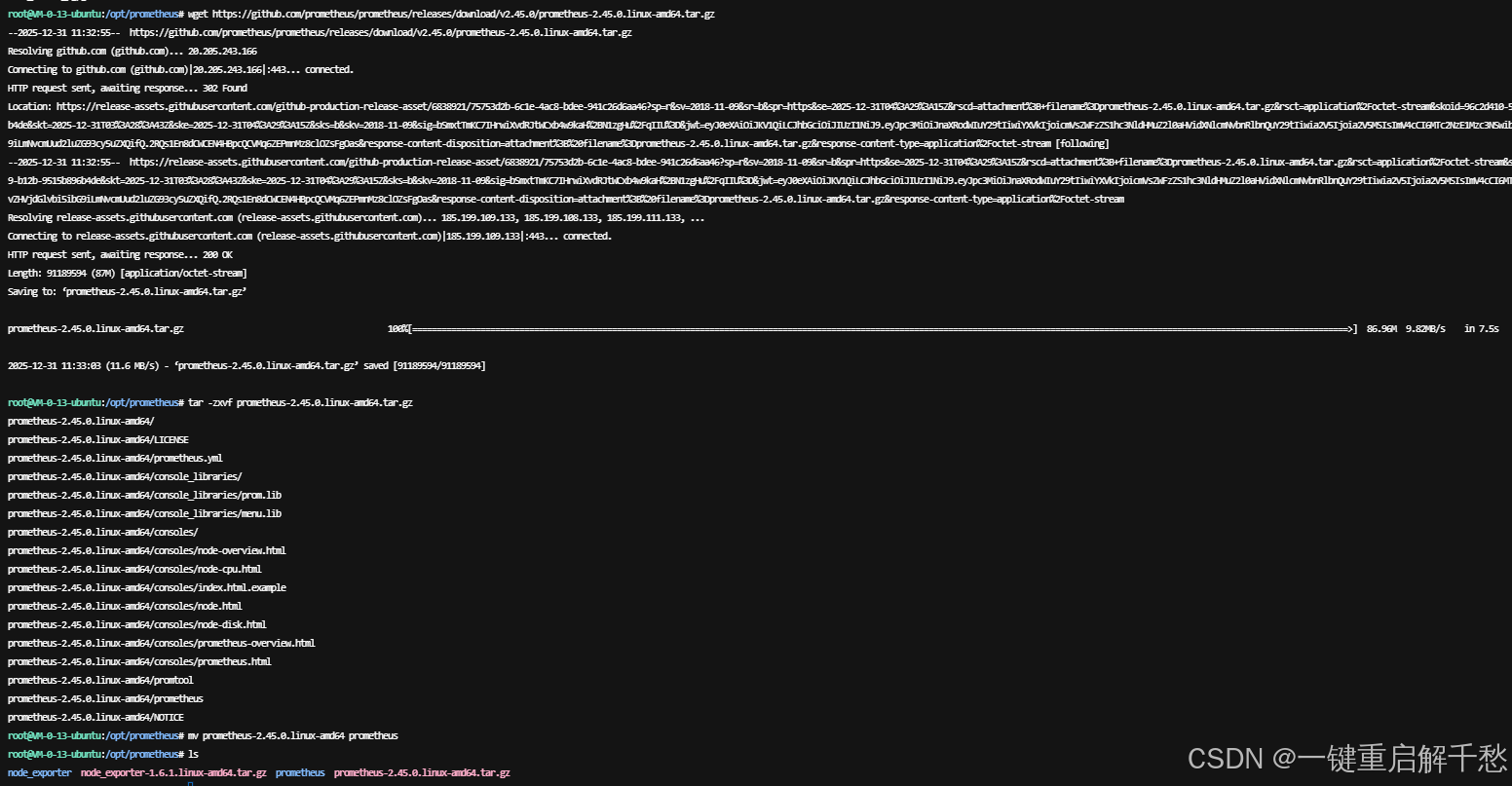
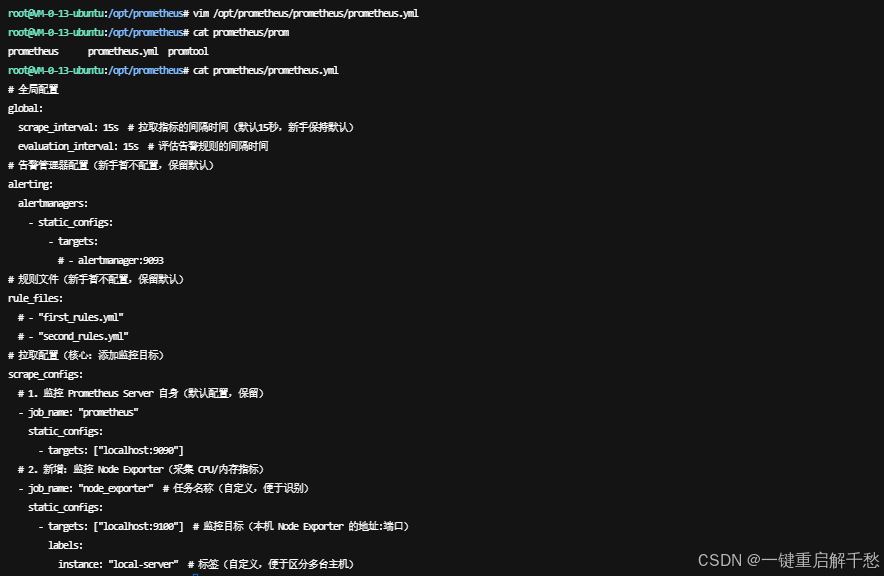
2. 修改 Prometheus 配置文件(添加 Node Exporter 监控目标)
核心是在 prometheus.yml 中配置监控目标,让 Prometheus 知道要从哪里拉取指标。
# 编辑 Prometheus 配置文件
vim /opt/prometheus/prometheus/prometheus.yml修改配置文件内容(重点修改 scrape_configs 节点,添加 Node Exporter 监控目标):
# 全局配置
global:
scrape_interval: 15s # 拉取指标的间隔时间(默认15秒,新手保持默认)
evaluation_interval: 15s # 评估告警规则的间隔时间
# 告警管理器配置(新手暂不配置,保留默认)
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# 规则文件(新手暂不配置,保留默认)
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# 拉取配置(核心:添加监控目标)
scrape_configs:
# 1. 监控 Prometheus Server 自身(默认配置,保留)
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
# 2. 新增:监控 Node Exporter(采集 CPU/内存指标)
- job_name: "node_exporter" # 任务名称(自定义,便于识别)
static_configs:
- targets: ["localhost:9100"] # 监控目标(本机 Node Exporter 的地址:端口)
labels:
instance: "local-server" # 标签(自定义,便于区分多台主机)保存并退出 vim(按 Esc,输入 :wq 回车)。
3. 启动 Prometheus Server(后台运行)
# 1. 后台启动 Prometheus Server
nohup /opt/prometheus/prometheus/prometheus --config.file=/opt/prometheus/prometheus/prometheus.yml > /opt/prometheus/prometheus/nohup.out 2>&1 &
# 2. 验证启动是否成功(查看 9090 端口)
netstat -tnlp | grep 9090
# 预期输出:看到 prometheus 进程占用 9090 端口
# 3. 浏览器访问验证(服务器 IP:9090)
# 示例:http://192.168.1.100:9090
# 能打开 Prometheus Web UI 即说明启动成功4. 验证指标拉取是否成功
-
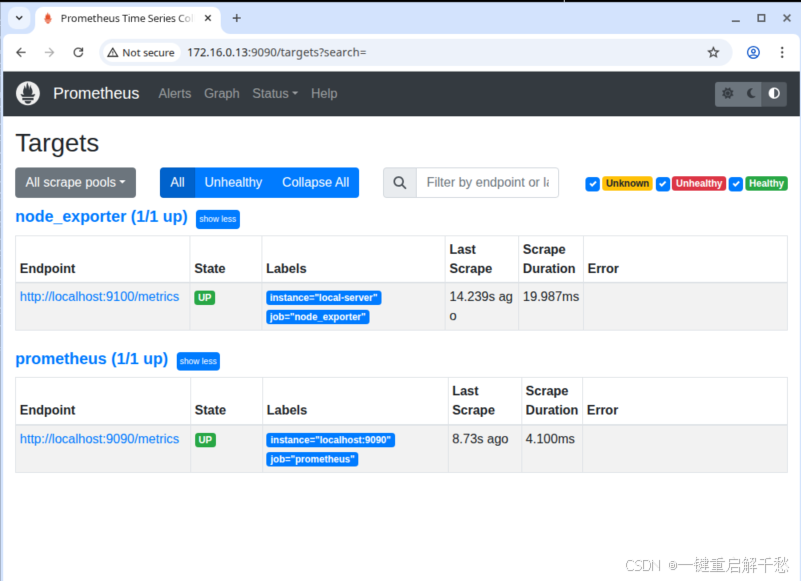
打开浏览器,访问
http://服务器IP:9090,进入 Prometheus Web UI。 -
点击顶部导航栏
Status→Targets,进入目标监控页面。 -
查看
node_exporter任务的状态,若显示UP(绿色),说明 Prometheus 已成功连接 Node Exporter,指标拉取正常;若显示DOWN,检查配置文件和 Node Exporter 状态。
步骤 3:安装并配置 Grafana(可视化 CPU/内存指标)
Prometheus 仅能存储和查询指标,Grafana 可将其可视化,快速看到 CPU/内存使用率的变化趋势。
1. 安装 Grafana
# 1. 安装 Grafana 依赖(CentOS 系统)
yum install -y fontconfig freetype freetype-devel fontconfig-devel libstdc++
# Ubuntu 系统安装依赖
# apt install -y apt-transport-https software-properties-common
# 2. 下载 Grafana 安装包(稳定版本 v10.0.3 为例)
cd /opt/prometheus
wget https://dl.grafana.com/oss/release/grafana-10.0.3.linux-amd64.tar.gz
# 3. 解压安装包
tar -zxvf grafana-10.0.3.linux-amd64.tar.gz
# 4. 重命名目录
mv grafana-10.0.3 grafana2. 启动 Grafana(后台运行)
# 1. 后台启动 Grafana
nohup /opt/prometheus/grafana/bin/grafana-server --homepath=/opt/prometheus/grafana > /opt/prometheus/grafana/nohup.out 2>&1 &
# 2. 验证启动是否成功(查看 3000 端口)
netstat -tnlp | grep 3000
# 预期输出:看到 grafana-server 进程占用 3000 端口3. 登录 Grafana 并添加 Prometheus 数据源
-
浏览器访问
http://服务器IP:3000,进入 Grafana 登录页面。 -
默认账号:
admin,默认密码:admin(首次登录需修改密码,新手可暂时跳过,直接点击Skip)。 -
进入 Grafana 首页后,点击左侧导航栏
Connections→Data sources→Add data source。 -
在数据源列表中选择
Prometheus。 -
配置 Prometheus 数据源信息:
-
Name:自定义名称(如Prometheus-Local) -
URL:Prometheus 访问地址(http://localhost:9090,若 Grafana 与 Prometheus 不在同一服务器,填写服务器 IP:9090) -
其他配置保持默认,点击底部
Save & test。
-
-
若显示
Data source is working(绿色提示),说明数据源添加成功。
4. 导入官方 Node Exporter 仪表盘(快速展示 CPU/内存指标)
无需手动配置面板,直接导入 Grafana 官方仪表盘模板,一键展示 CPU、内存、磁盘等指标。
-
左侧导航栏点击
Dashboards→New dashboard→Import dashboard。 -
在
Import via grafana.com输入框中填写官方模板 ID:1860(Node Exporter 全面监控模板,最常用),点击Load。 -
选择数据源:在
Prometheus下拉框中选择刚才添加的 Prometheus 数据源(如Prometheus-Local),点击Import。 -
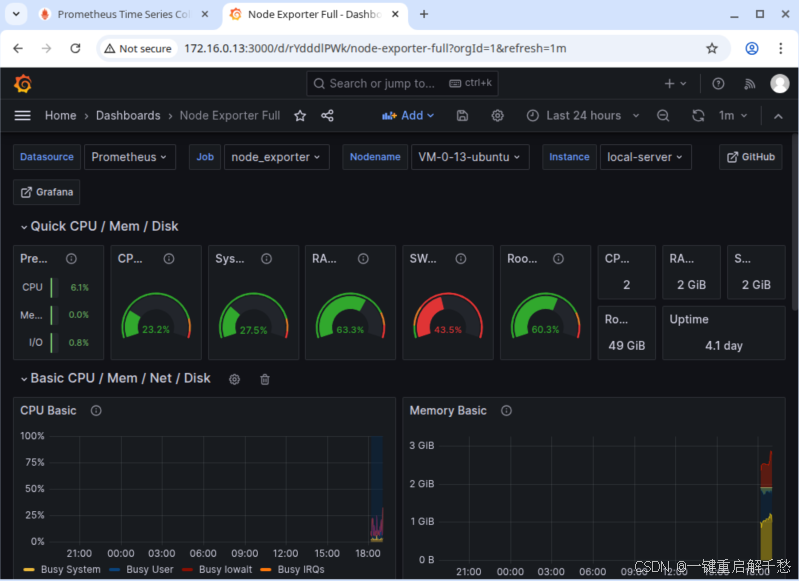
导入成功后,自动进入监控面板,即可看到 CPU 使用率、内存使用率、磁盘使用率等直观的可视化图表。
步骤 4:验证 CPU/内存监控效果
1. 可视化面板验证
在 Grafana 仪表盘页面,可清晰看到:
-
CPU 相关指标:CPU 整体使用率、每个 CPU 核心的使用率、空闲 CPU 占比等(折线图展示变化趋势)。
-
内存相关指标:内存总容量、已使用内存、空闲内存、缓存内存等(仪表盘展示实时占比,折线图展示变化趋势)。
-
可通过面板顶部的时间筛选器(如近 15 分钟、近 1 小时),查看不同时间段的指标变化。
2. PromQL 查询验证(手动查询 CPU/内存指标)
若想手动查询指标,可回到 Prometheus Web UI(http://服务器IP:9090):
-
查询 CPU 使用率:在顶部查询框输入以下 PromQL 语句,点击
Execute(执行),即可看到 CPU 使用率的时序数据:# CPU 使用率(排除空闲状态,计算整体使用率) 100 - (avg by (instance) (irate(node_cpu_seconds_total{mode="idle"}[1m])) * 100) -
查询内存使用率:输入以下 PromQL 语句,执行后查看内存使用率:
# 内存使用率(已使用内存/总内存 * 100) 100 * (1 - (node_memory_MemAvailable_bytes / (node_memory_MemTotal_bytes))) -
若能查询到对应数据,且与 Grafana 面板展示一致,说明监控体系搭建成功。
四、入门常见坑与解决方案
坑 1:Prometheus Targets 显示 Node Exporter 为 DOWN
-
原因:防火墙未开放 9100 端口、Node Exporter 未启动、配置文件中目标地址填写错误。
-
解决方案:① 检查 Node Exporter 状态(
ps -ef | grep node_exporter);② 验证 9100 端口可访问(curl http://服务器IP:9100/metrics);③ 检查prometheus.yml中targets配置是否正确。
坑 2:Grafana 导入模板失败
-
原因:网络问题(无法访问 Grafana 模板仓库)、数据源未添加成功。
-
解决方案:① 手动下载模板 JSON 文件导入;② 确认 Prometheus 数据源添加成功(
Save & test显示正常);③ 检查服务器网络是否通畅。
坑 3:Grafana 面板无数据
-
原因:Prometheus 未拉取到指标、数据源配置错误、时间筛选器选择不当。
-
解决方案:① 先在 Prometheus Web UI 用 PromQL 查询指标,确认有数据;② 检查 Grafana 数据源 URL 是否正确;③ 调整时间筛选器(选择“近 15 分钟”,确保有足够的指标数据)。
坑 4:端口被占用导致组件启动失败
-
原因:9090/9100/3000 端口被其他进程占用。
-
解决方案:① 用
netstat -tnlp | grep 端口号查看占用进程;② 停止占用进程,或修改组件端口(如 Prometheus 启动时添加--web.listen-address=":9091"指定端口)。
五、总结与进阶方向
1. 核心成果回顾
-
完成了「Node Exporter(采集)→ Prometheus Server(存储/查询)→ Grafana(可视化)」的基础监控闭环。
-
成功监控主机 CPU、内存指标,可通过 Grafana 直观查看指标变化,通过 PromQL 手动查询指标。
-
掌握了 Prometheus 生态三大核心组件的安装、配置与联动方法。
2. 进阶学习方向
-
告警配置:集成 AlertManager,实现 CPU/内存使用率超过阈值时(如 CPU 使用率>85%)自动发送邮件/钉钉告警。
-
多主机监控:在 Prometheus 配置文件中添加多台主机的 Node Exporter 地址,实现批量监控。
-
自定义指标:除了系统指标,还可采集应用指标(如 Python 应用、Docker 容器指标)。
-
数据持久化:配置 Prometheus 数据持久化存储,避免服务器重启后指标丢失。
-
面板自定义:根据业务需求,修改 Grafana 仪表盘,添加自定义指标展示。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号