
规则引擎在IoT的重要性?
前言

物联网的强大功能主要来自于它使我们能够实时做出更准确的决策的能力,这些在通知、自动化和预测性维护上都有所体现。因此我们需要能对实时数据进行实时响应的工具,答案就是规则引擎。规则引擎可以通过摄取实时数据,对该数据进行推理并根据该推理过程的结果调用自动操作或者第三方API来履行职责。
IoT案例探讨
这里有一个智能农业的场景:
如果某种植物的生长需要维持恒温恒湿的环境,温度为18~20℃,相对湿度为85~90%。如果温度低于18℃,我们需要升温并对湿度进行补充;当高于20℃,我们需要降温并对湿度进行检查。
您可以在应用程序中轻松实现上述的规则或逻辑。但是,如果您将接到了其他一些需求,例如:
- 如果存在大量逻辑,那么您将如何有效的编写和处理它们? (很好的代码设计模式)
- 如果逻辑经常更改,并且您通常在应用程序中编写逻辑代码,那么您将如何管理或频繁更改代码? (避免频繁部署)
- 设计应用程序以便让业务人员可以轻松维护和理解。(非技术成员使用)
- 如果您必须将所有业务逻辑都放在一个项目中,和其他所有应用程序分开,那么您将在哪里保存它? (微服务架构)
为了在我们的应用程序中满足所有这些要求,但是在启动规则引擎之前,让我们先了解一下规则引擎是什么?
什么是规则引擎?
下面是来自Martin Fowler的一篇文章“我应该使用规则引擎吗?”
规则引擎是一种工具,可以更轻松地使用此计算模型进行编程。它可能是完整的开发环境,也可能是可与传统平台一起使用的框架。近年来,我所见的大多数工具都是设计为适合现有平台的工具。曾经有一种想法是使用这样的工具来构建整个系统,但是现在人们(明智地)倾向于仅将规则引擎用于系统的各个部分。生产规则计算模型最适合仅解决一部分计算问题,因此规则引擎可以更好地嵌入到较大的系统中。
您可以自己构建一个简单的规则引擎。您所需要做的就是创建一堆带有条件和动作的对象,将它们存储在一个集合中,然后遍历它们以评估条件并执行这些动作。但是大多数情况下,当人们提到“规则引擎”时,它们是指专门用来帮助您构建和运行规则引擎的产品。用于指定规则的技术可能有所不同,包括人们将API描述为Java对象的API,表达规则的DSL或允许人们输入规则的GUI。高效的执行引擎有助于使用专门的算法(例如Rete算法)快速评估数百条规则的条件。
规则引擎的一个重要属性是链接 -一条规则的操作部分以改变另一条规则的条件部分的值的方式更改系统状态。链接听起来很吸引人,因为它支持更复杂的行为,但很容易导致很难推理和调试。
这是一个运行在数据上的系统程序, 如果任何条件匹配,那么它就会执行相应的操作。
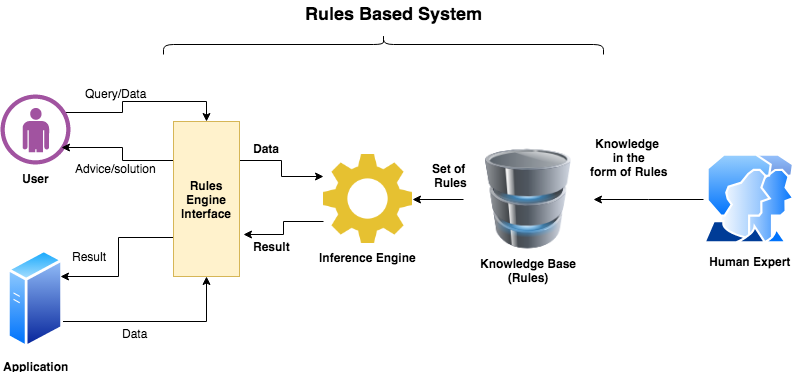
在上图中,显示了我们以规则(if-then)的形式收集知识并将其存储在任何地方。规则可以存储在文件或数据库之类的任何存储中。现在,规则引擎根据需求选择规则,并在输入数据或查询上运行它们。如果有任何模式/条件匹配,则它将执行相应的操作并返回结果或解决方案。
规则引擎的类型
前向链接(Forward-Chaining)引擎
使用前向链接的推理引擎应用一组规则和事实来推导结论,搜索规则,直到发现IF子句为真为止。根据规则匹配新的或现有事实的过程称为模式匹配,它是由前向链接推理引擎通过各种算法执行的,如Linear、Rete、Treat、Leaps等。
当发现条件为真时,引擎将执行THEN子句,这将导致向其数据集添加新信息。换句话说,引擎从大量事实开始,并应用规则从这些事实中得出所有可能的结论。这就是“前向链接”这一名称的由来——即推理引擎从数据开始,通过推理向前得到答案,这与反向链接相反,后者的工作方式是相反的。
应用案例:目前市场上的大多数物联网平台实际上都有这种类型的规则引擎。下面是几个基于前向链接引擎的自动化工具的例子,这些工具在我们写这篇博客的时候已经在市场上出现了:Redhat Drools, Cumulocity, Eclipse Smart Home, AWS Rules, Thingsboard等等。
条件动作(Condition-Action)引擎
基于条件-动作(CA)规则引擎属于前向链接引擎,但存在一些相关的差异,特别是在物联网领域。与前向链接引擎相比,条件-动作规则引擎不允许多个条件,这使得它们一方面在逻辑表达能力上非常有限,另一方面——可伸缩性更强。条件操作规则引擎(如果-那么)有时使用ELSE语句进行扩展(如果-那么- 或者 - 那么)。
应用案例:物联网领域中这种规则引擎最流行的例子之一是ifttt.com服务。
流处理(flow processing)引擎
基于流的编程是一种将应用程序定义为“黑盒”流程网络的编程范式。这些进程,即函数,被表示为节点,通过消息传递在预定义的连接之间交换数据。节点可以被不断地重新连接,从而形成不同的应用程序,而不必更改它们相关联的功能。
基于流的编程(FBP)自然是“面向组件的”。FBP的好处包括:
- 更改连接接线而不重写组件。
- 本质上是并发的——适合多核CPU世界。
应用案例:
Yahoo! Pipes和Node-RED是使用基于流的编程构建的规则引擎的两个例子。随着“serverless”计算的引入,基于流的编程变得更加流行,在“serverless”计算中,可以通过链接函数构建云应用程序。
IBM的OpenWhisk是一个基于流的编程示例,它通过链接云函数(IBM称之为动作)实现编程。另一种无服务器编排方法(如AWS step functions)基于有限状态机规则引擎。
决策树(decision trees)引擎
捕获条件规则复杂性的一种流行方法是使用决策树,决策树是使用分支方法来说明决策的每一个可能结果的图。
应用案例:
Drools主要以其基于前向链接的规则引擎而闻名,它有一个可与决策表集成的扩展,可以将excel表与嵌入代码片段结合使用,以容纳任何额外的逻辑或所需的阈值。
有限状态机(finite state machines)引擎
状态机可用于根据系统经历的一组状态来描述系统。状态是对等待执行转换的系统状态的描述。过渡是在满足条件或接收到事件时要执行的一组动作。
FSM的概念易于由不同类型的用户掌握。BRE(业务规则引擎)的主要销售论点是BRE软件允许非程序员在业务流程管理(BPM)系统中实现业务逻辑。
FSM经常忽略的一件事是状态暗含着过渡,也就是说,将某种事物建模为状态的唯一目的是导航特定的决策流程。
这样做的直接结果是,FSM缺乏可读性,因为规则变得更加复杂,或者需要将特定的极端情况建模为状态。由于FSM一次只能执行一个转换,因此当用户尝试引入在某些条件下可能发生的事件时,她需要添加一个新状态。当状态数过多时,状态机的可读性会大大下降。
规则引擎的优势
我们可以将给定示例中的所有上述特定要求视为规则引擎的优势。
- 规则很容易被业务分析师,客户团队等任何非技术人员阅读和编码。在这里,您必须专注于“该做什么”,而不是“该怎么做”。
- 您可以将所有规则存储在中心存储中。这意味着您将拥有所有业务规则和逻辑的中心位置。这将是您的真理之源。
- 逻辑与核心应用程序逻辑分开管理,因此可以对其进行管理和重用。
- 在规则引擎中,我们使用不同的模式匹配和冲突解决算法,可提供高性能。
- 对于经常变化的需求,我们可以轻松地更新规则。无需更改代码。
- 如果代码包含许多决策点,则代码的复杂性会更高。规则引擎可以更好地处理它,因为它们使用业务规则的一致表示形式。
- 不同的应用程序可以将相同的规则引擎用于相同的逻辑。它提高了可重用性。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号