
01-net.cdf文件处理 java语言
初次认识到net.cdf文件,他的主要用途是读取气象专业格式net.cdf文件
一、NetCDF简介
NetCDF全称为network Common Data Format( “网络通用数据格式”),是一个软件库与机器无关的数据格式,支持创建,访问基于数组的科研数据。分别提供了对Java和C / C++ / Fortran语言。 对程序员来说,它和zip、jpeg、bmp文件格式类似,都是一种文件格式的标准。netcdf文件开始的目的是用于存储气象科学中的数据,现在已经成为许多数据采集软件的生成文件的格式。
从数学上来说,netcdf存储的数据就是一个多自变量的单值函数。用公式来说就是f(x,y,z,…)=value, 函数的自变量x,y,z等在netcdf中叫做维(dimension)或坐标轴(axix),函数值value在netcdf中叫做变量(Variables)。而自变量和函数值在物理学上的一些性质,比如计量单位(量纲)、物理学名称在netcdf中就叫属性(Attributes)。
上午的时候,手里没有nc(net.cdf)文件,就想办法找一个,然后就搜到了earthdata,这是他的官网https://disc.gsfc.nasa.gov/
里边可以生成nc文件。在官网生成nc文件,需要nasa账号,nasa账号我注册了一个,earthdata官网生成后,会有一个text,这里的text前2项不要,
第3项需要通过python下载到本地,第三项就是nc文件,也打不开,可能需要可视化工具一类的,目前没有去找,后来直接用java解析,可以解析出来。
教程网站是从这里看到的:https://blog.csdn.net/qq_27386899/article/details/104533226
下边的是教程
可以在GES DISC查找下载数据:https://disc.gsfc.nasa.gov/datasets?keywords=GPM&page=1
现在GPM官网上线了许多数据。为了快速定位,我们可以使用分辨率进行筛选,快速定位数据。
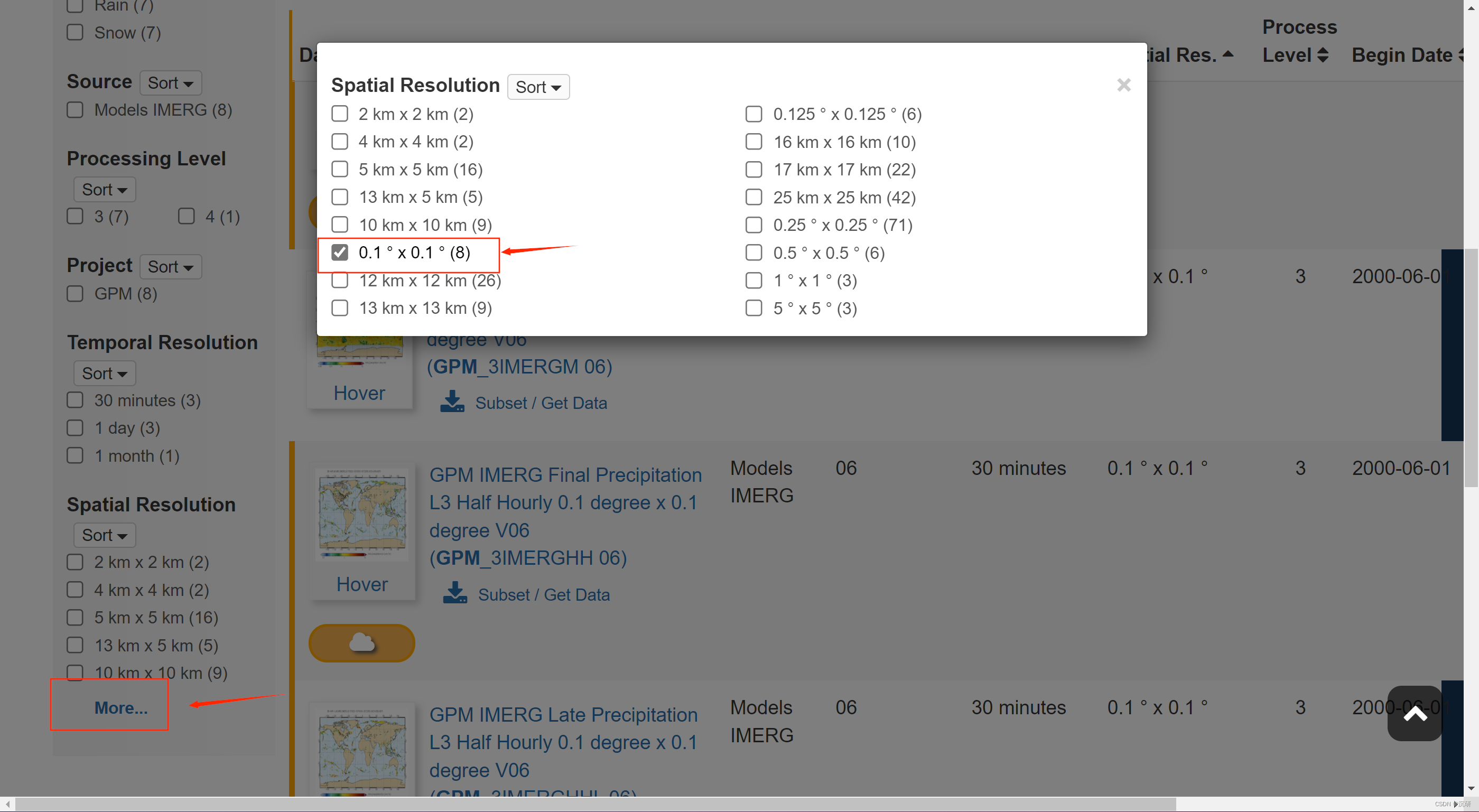
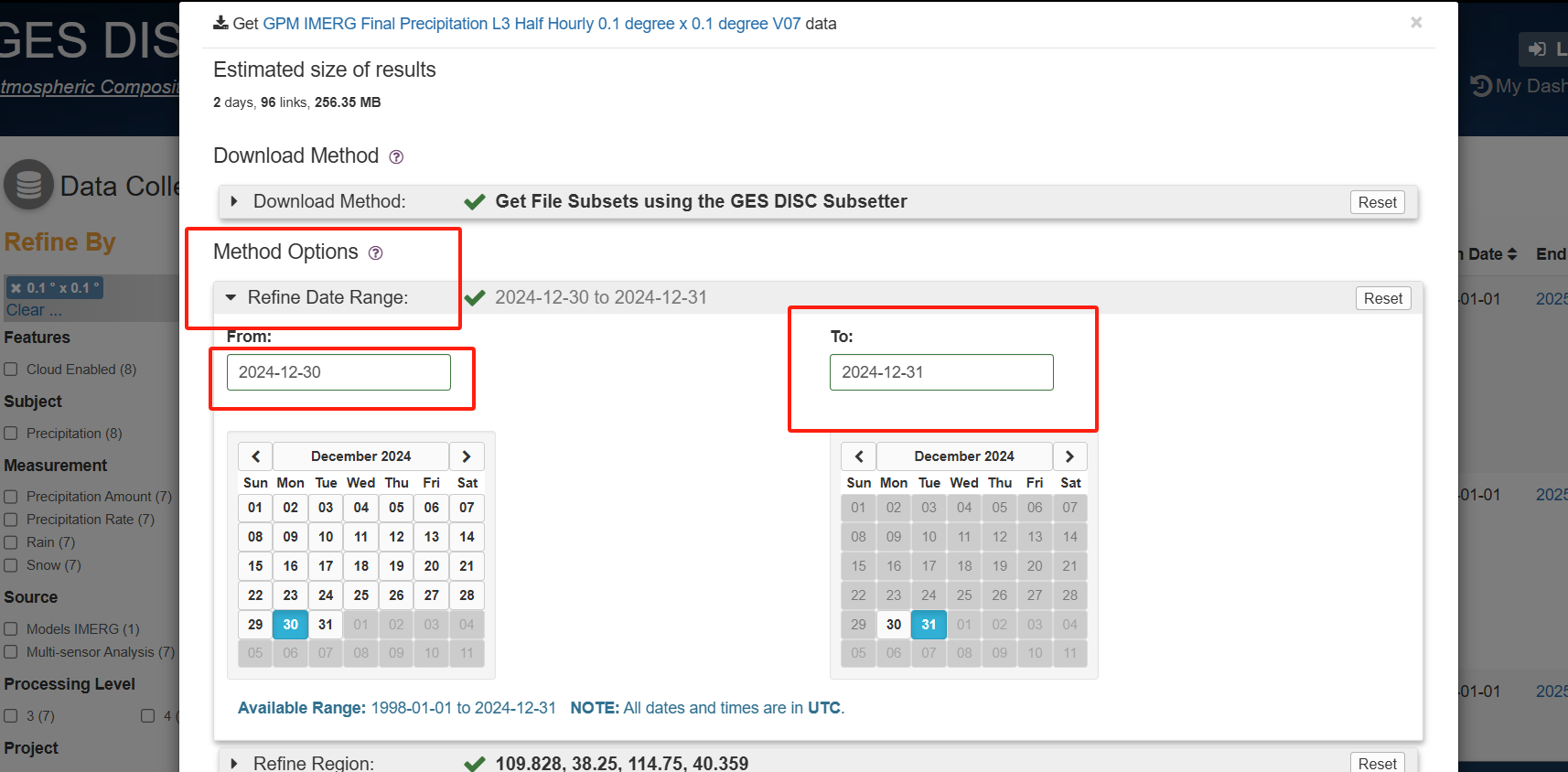
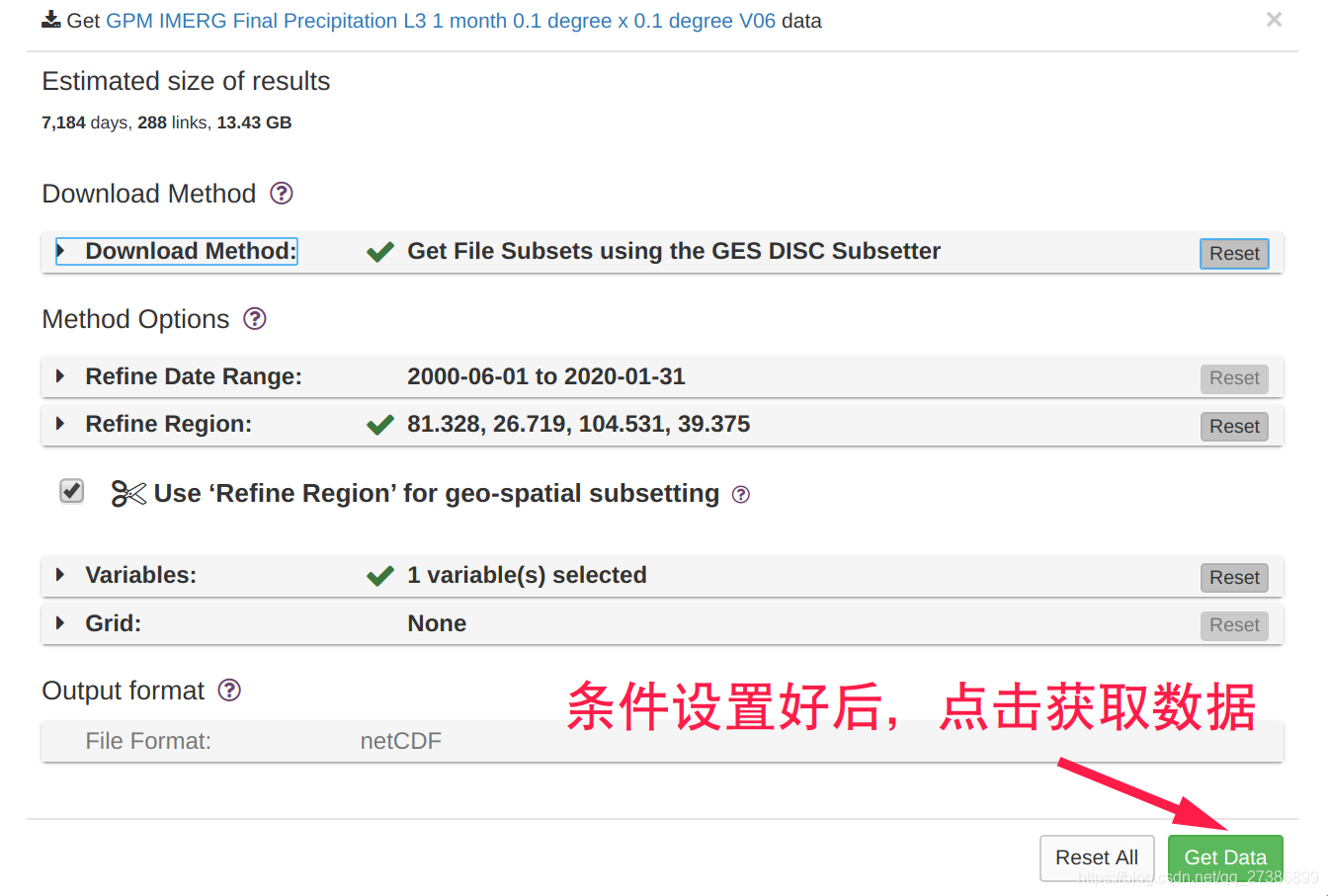
选择需要的时间和空间分辨率数据集,点击Subset/Get Data
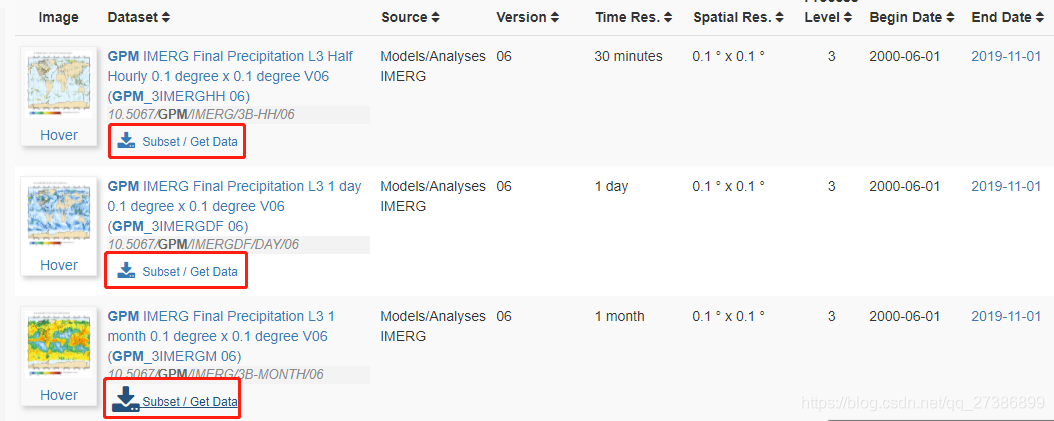
选择想要的时间范围、空间范围(西,南,东,北)、变量、输出文件的格式等,并点击右下角的Get Data获取数据
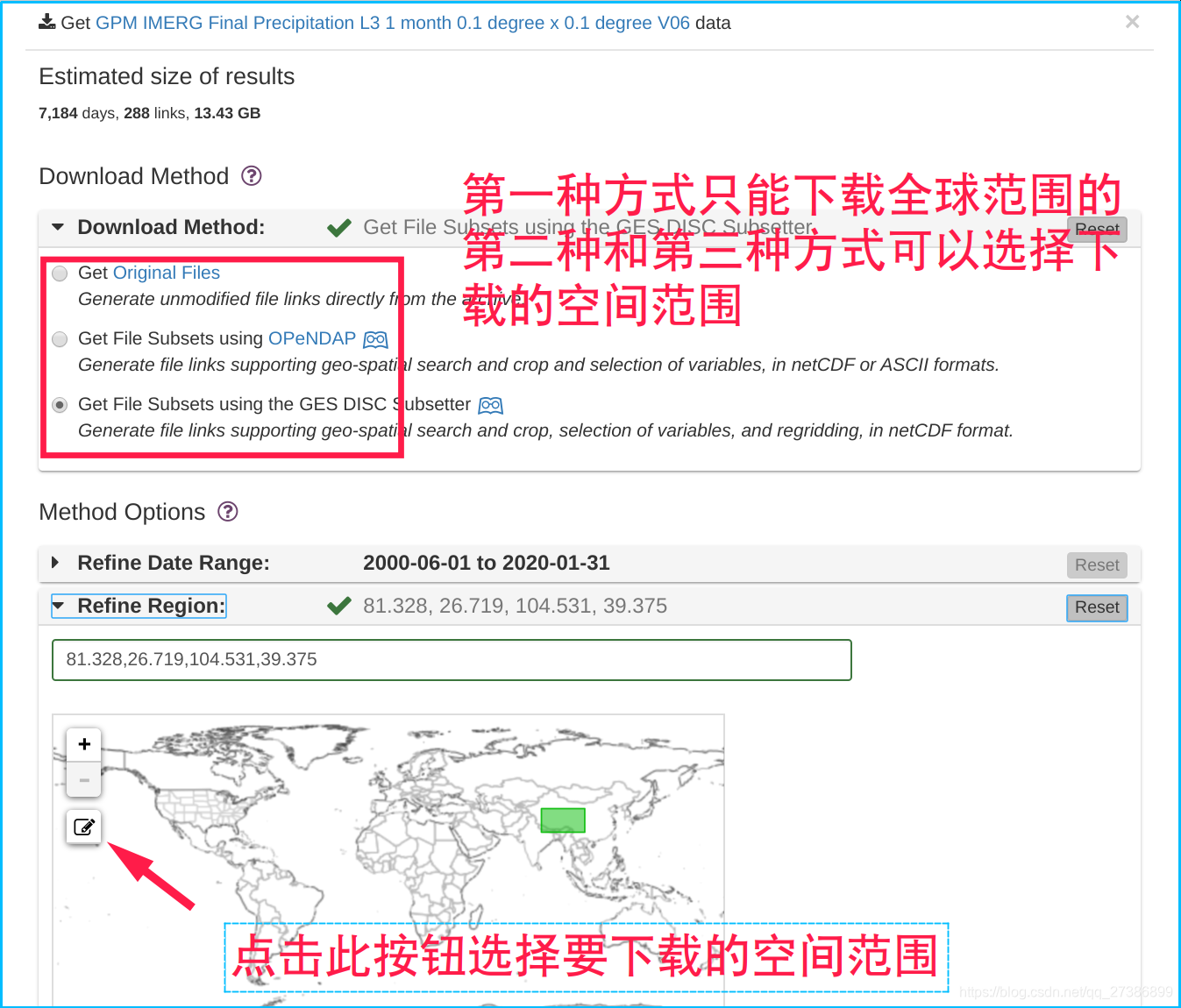
这里有一点就是他要选择你需要的气象类型
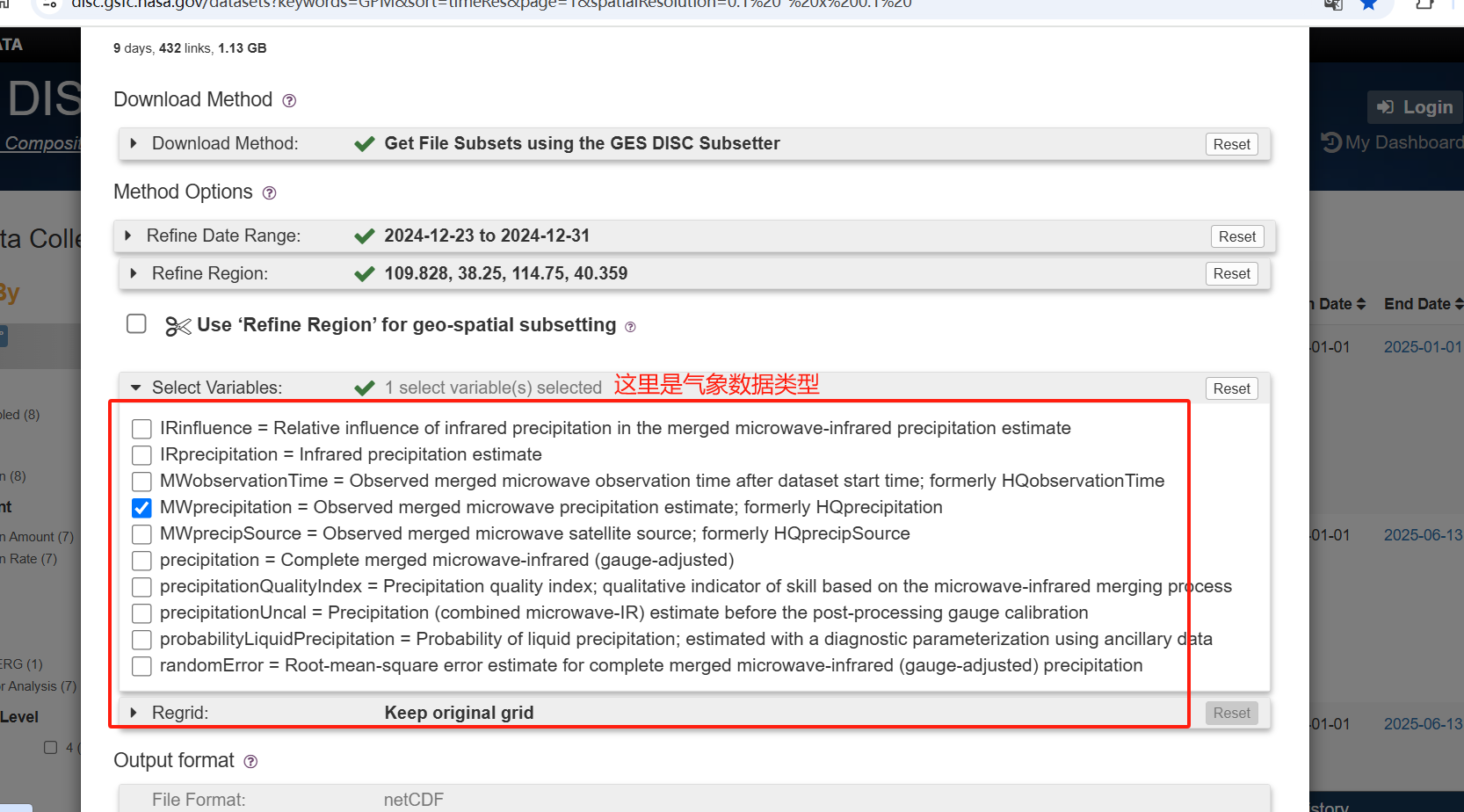
这里感觉最好筛选下日期范围 不然不知道会不会很大
3. 下载
注意:
本文使用的是Python脚本,来批量下载文件。如果使用本文的下载方式,请先下载Python3.6以上的版本,并使用pip安装data_downloader包:
pip install data_downloader
如果之前安装过此包,需要更新到最新版:
pip install --upgrade data-downloader
3.1. 授权
下载GPM数据需要NASA的账户与密码,如果没有请先在NASA官网注册一个。
注意:GPM使用NASA账号需要授权, 请按照官方教程进行授权:https://disc.gsfc.nasa.gov/earthdata-login
跟着官方的提示一步一步做 最后就能开通授权了 就可以下载
3.1.1 通过 .netrc 文件授权
.netrc 文件可以保存网站的帐号密码信息,当程序下载时,会自动读取对应网站的帐号密码,无须用户反复输入。
.netrc 文件中的账号密码信息可以通过如下方式写入:
将下面代码中的your_username与your_password,改为自己在NASA注册的用户名与密码,并复制到Python编辑器中执行。
from data_downloader import downloader netrc = downloader.Netrc() netrc.add('urs.earthdata.nasa.gov','your_username','your_password')
执行后会在用户目录创建一个.netrc文件,当下载需要帐号密码的时候,会读取此文件。 (我操作的时候没有 但是不影响最后下载)
如果账号或密码输入错误,执行以下代码进行更新:
netrc.add('urs.earthdata.nasa.gov','your_username','your_password',overwrite=True)
3.1.2 *通过浏览器授权(通过 .netrc 文件授权现在已经可以正常工作,不建议使用此方法)
打开下载的包含所有url的文件,随便复制一条(从第三条开始,第一,二条是说明文档),粘贴在浏览器中,回车后输入用户名和密码进行登陆授权。在下载代码中将参数 authorize_from_browser 设置为 True,程序即可加载浏览器中的cookies,得到网站授权,从而可以正常下载。
目前支持的浏览器有:Chrome,Firefox, Opera, Edge, Chromium。请使用此中的某一个浏览器进行登陆。
注意:
在浏览器登陆后,最好不要关闭浏览器。关闭后有可能清除浏览器cookies,导致无法授权。
3.2. 批量下载
创建一个Python文件,复制下面代码,并根据自己情况改变
folder_out与url_file路径,执行即可批量下载。可以通过改变folder_out 与url_file 路径,来改变文件下载目录与包含url的文件路径
本脚本会自动跳过已下载的文件,并且支持断点续传(仅全球范围,即下载方式1支持此功能)。如果下载中断,个别文件下载不完整,重新执行本脚本即可。如果脚本提示无法从网站获取到文件大小信息(opendap,下载方式2会有这种情况),则需要自行判断文件是否下载完整,并手动删除下载不完整的文件。#!/usr/bin/env python3 """ Created on Thu Feb 27 13:49:03 2020 @author: Chengyan Fan """ from data_downloader import downloader, parse_urls #################################################################################################### # 在此修改输入输出文件路径 ######################### # 文件输出目录 folder_out = r'/media/fanchy/新加卷/dem_temp/test' # 包含url的文件路径 url_file = r"/media/fanchy/新加卷/dem_temp/test/subset_GPM_3IMERGM_06_20200513_134318.txt" #################################################################################################### urls = parse_urls.from_urls_file(url_file) downloader.download_datas(urls, folder_out) # 通过浏览器方法 # downloader.download_datas(urls, folder_out, authorize_from_browser=True)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号