
专题 (五) map 数据结构
1、用法
| 用法 | 说明 |
|
1、declare -A map 2、declare -A myMap=(["my01"]="01" ["my02"]="02") 3、declare -A map=() |
1、声明map变量 2、声明map变量的同时可以赋值 3、定义一个空map |
| map[$_key]=$_count |
指定key赋值value,其中_key 和 _value 均是 shenll 变量 |
|
1、echo ${!myMap[@]} 2、echo ${!myMap[*]} |
若未使用declare声明map,则此处将输出0 输出所有的key |
|
1、echo ${myMap[@]} 2、echo ${myMap[*]} |
输出所有的value |
| echo ${#myMap[@]} | 输出map长度 |
| unset map[$key] | 从map 中删除指定的key 对应的项 |
| echo ${map["hello"]} | 输出指定key的value值 |
2、案例
(1) 遍历,根据key找到对应的value
for key in ${!myMap[*]};do echo $key echo ${myMap[$key]} done
(2) 遍历所有的value
for val in ${myMap[@]};do echo $val done
(3) map 转字符串
# 声明关联数组 declare -A my_array my_array=([apple]='100' [banana]='200' [cherry]='150') function print_array() { _key_array=($1) _value_array=($2) _size=${#_key_array[@]} for ((i=0;i<_size;i++)){ echo "${_key_array[$i]}: ${_value_array[$i]}" } } print_array "${!my_array[*]}" "${my_array[*]}"
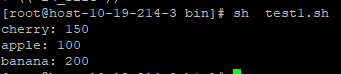
(4) 函数输出 map 格式数据,调用该函数的方法使用map数据
function generateMapWithEcho(){ echo "1:hello1" echo "2:hello2" } while IFS=: read -r key value; do echo $key echo $value done < <(generateMapWithEcho)
结果输出
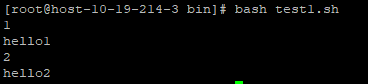
可以看出,结果输出上 已经按照脚本逻辑预期输出了k-v
#!/bin/bash # 使用了进程替换命令 <(command) 或 >(command) 的脚本,必须使用 bash xxx.sh 执行脚本 # 定义一个函数,该函数通过echo输出多行数据 function print_lines() { echo "第一行" echo "第二行" echo "第三行" } cat <(ls -l) # 使用while循环读取函数的echo输出 while IFS= read -r line; do echo "读取到的行: $line" done < <(print_lines)
小知识点:这里 使用了进程替换命令 <(command) 或 >(command)
进程替换
1)含义
把一个命令的输出结果传递给另一个(组)命令。
2)用法
| 写法 | 含义 | 注意点 | 本质 |
|---|---|---|---|
| <(commands) |
它借助于输入重定向,可以将它的输出结果作为另一个命令的输入 |
commands 是一组命令列表,多个命令之间以分号;分隔。注意,<或>与圆括号之间是没有空格的。 |
/dev/fd/n文件接受(commands)的输出,作为另一个命令的输入 |
| >(commands) |
它借助于输出重定向,可以接受另一个命令的标准输出结果 |
从/dev/fd/n文件中读取内容,作为(commands)的输入 |
3)使用进程替换的必要性
| 举栗 | 结果 | 说明 |
|---|---|---|
|
普通模式
|
输出结果为空 |
echo 命令在父 Shell 中执行,而 read 命令在子 Shell 中执行,当 read 执行结束时,子 Shell 被销毁,AA 变量也就消失了。 管道中的命令总是在子 Shell 中执行的,任何给变量赋值的命令都会遭遇到这个问题。 |
|
使用进程替换
|
输出结果为aaaaa | 整体上来看,Shell 把echo "aaaaa"的输出结果作为 read 的输入。<()用来捕获 echo 命令的输出结果,<用来将该结果重定向到 read。注意,两个 <之间是有空格的,第一个<表示输入重定向,第二个<和()连在一起表示进程替换。read 命令和第二个 echo 命令都在当前 Shell 进程中运行,读取的数据也会保存到当前进程的 AA 变量,所以使用 echo 能够成功输出。 |
|
进程替换用作「接受标准输入」的例子 echo "qpy" > >(read; echo "你好,$REPLY") |
运行结果:你好,qpy | 因为使用了重定向,read 命令从echo "qpy"的输出结果中读取数据。 |
4)进程替换的本质
/dev/fd/n(n 是一个整数)。该文件会作为参数传递给()中的命令,()中的命令对该文件是读取还是写入取决于进程替换格式是<还是>:
- 如果是
>(),那么该文件会给()中的命令提供输入;借助输出重定向,要输入的内容可以从其它命令而来。 - 如果是
<(),那么该文件会接收()中命令的输出结果;借助输入重定向,可以将该文件的内容作为其它命令的输入。
使用 echo 命令可以查看进程替换对应的文件名:
| 命令 | 输出 | 说明 |
|---|---|---|
|
echo >(true) |
/dev/fd/63 |
/dev/fd/目录下有很多序号文件,进程替换一般用的是 63 号文件,该文件是系统内部文件,我们一般查看不到。
|
|
echo <(true) |
/dev/fd/63 |
|
|
echo >(true) <(true) |
/dev/fd/63 /dev/fd/62 |
|
| echo "qpy" > >(read; echo "hello, $REPLY") |
hello, qpy |
第一个
|
5)执行含有进程替换命令的脚本
必须使用 bash xxx.sh 执行脚本,否则执行不成功,一直报语法错误
参考资料:
https://www.cnblogs.com/yy3b2007com/p/11267237.html
https://www.cnblogs.com/yinguohai/p/11193592.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号