神经网络误差反向传播
神经网络的反向传播
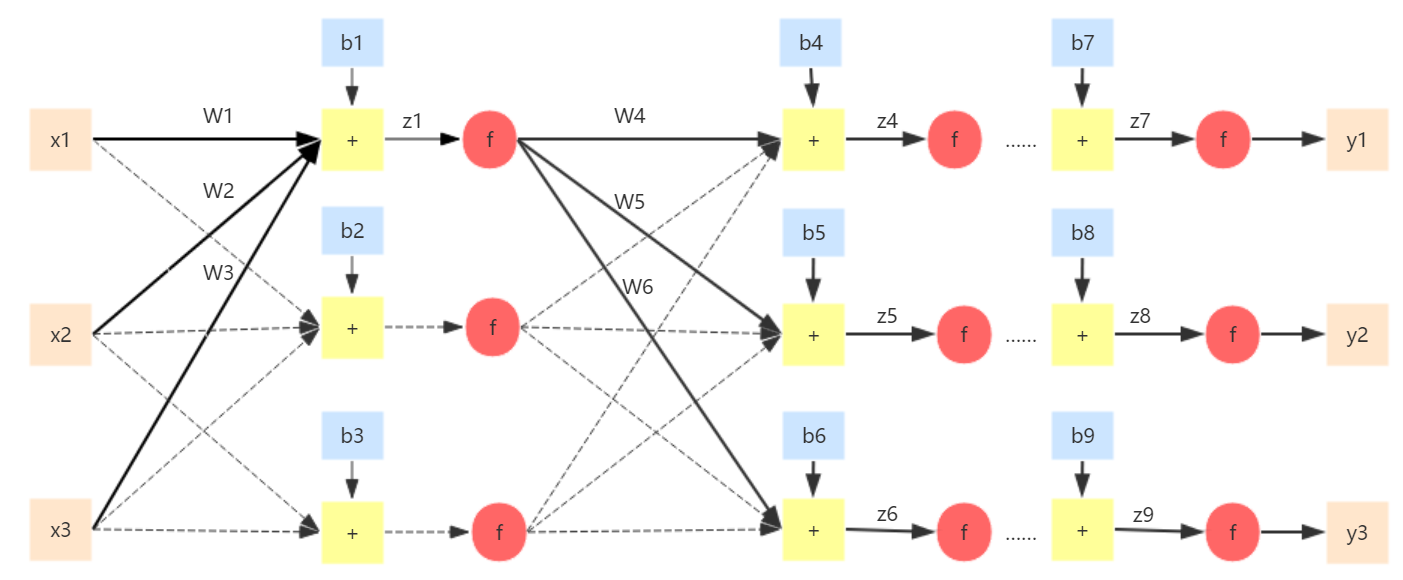
对于下面的神经网络,输入为\(x_1\),\(x_2\),\(x_3\),输出为\(y_1\),\(y_2\),\(y_3\),激活函数\(f\)为逻辑斯蒂函数即\(f=\frac{1}{1+e^{-z}}\),如何用梯度下降法求解呢?
首先定义这里的损失函数:\(L(\theta)=\frac{1}{2}\sum_{i}{(y_i-\widehat{y_{i}})^2}\)
要使用梯度下降,先复习一下求导的链式法则(Chain Rule):
1.若\(y=g(x),z=h(y)\),那么\(\frac{d z}{d x}=\frac{d z}{d y}\frac{d y}{d x}\)。
2.若\(x=g(s),y=h(s),z=k(x,y)\),那么\(\frac{dz}{ds}=\frac{\partial z}{\partial y}\frac{\partial y}{\partial s}+\frac{\partial z}{\partial x}\frac{\partial x}{\partial s}\)。
其实梯度下降的想法就是通过求梯度,得到在当前位置参数引起函数变化的方向,然后向使函数下降的方向来更新参数,如此不停的迭代更新参数,直到达到停止条件。
同样我们也计算梯度\(\frac{\partial L(\theta)}{\partial \theta}\)。
例如,要求出\(\frac{\partial L(\theta)}{\partial w_1}\),利用链式法则有:\(\frac{\partial L(\theta)}{\partial w_1}=\frac{\partial L(\theta)}{\partial z_1}\frac{\partial z_1}{\partial w_1}\),可以分别求\(\frac{\partial L(\theta)}{\partial z_1}\)和\(\frac{\partial z_1}{\partial w_1}\)。
由于\(z_1=w_1x_1+w_2x_2+w_2x_2+b_1\),因此\(\frac{\partial z_1}{\partial w_1}=x_1\)。
接下来需要求\(\frac{\partial L(\theta)}{\partial z_1}\),还是利用链式法则$$\frac{\partial L(\theta)}{\partial z_1}=\frac{\partial L(\theta)}{\partial f(z_1)} \frac{\partial f(z_1)}{\partial z_1}=\frac{\partial L(\theta)}{\partial f(z_1)}f'(z_1)$$,由于这里的\(f\)是逻辑斯蒂函数,因此\(f'(z_1)=\frac{e^{-z}}{(1+e^{-z})^2}\)。
我们还需要计算\(\frac{\partial L(\theta)}{\partial f(z_1)}\),从神经网络结构可以看出\(z_1\)通过\(w_4,w_5,w_6\)三个方向来影响\(L(\theta)\),因此还是利用链式法则$$\frac{\partial L(\theta)}{\partial f(z_1)}=\frac{\partial L(\theta)}{\partial z_4}\frac{\partial z_4}{\partial f(z_1)}+\frac{\partial L(\theta)}{\partial z_5}\frac{\partial z_5}{\partial f(z_1)}+\frac{\partial L(\theta)}{\partial z_6}\frac{\partial z_6}{\partial f(z_1)}$$$$\frac{\partial L(\theta)}{\partial f(z_1)}=w_4\frac{\partial L(\theta)}{\partial z_4}+w_5\frac{\partial L(\theta)}{\partial z_5}+w_6\frac{\partial L(\theta)}{\partial z_6}$$
再回过头看一下,我们想要计算\(\frac{\partial L(\theta)}{\partial z_1}\),结果得出$$\frac{\partial L(\theta)}{\partial z_1}=f'(z_1)[w_4\frac{\partial L(\theta)}{\partial z_4}+w_5\frac{\partial L(\theta)}{\partial z_5}+w_6\frac{\partial L(\theta)}{\partial z_6}]$$,因此先要计算\(\frac{\partial L(\theta)}{\partial z_4}\),\(\frac{\partial L(\theta)}{\partial z_5}\)和\(\frac{\partial L(\theta)}{\partial z_6}\)才能得到\(\frac{\partial L(\theta)}{\partial z_1}\),而同样的情况,需要计算下一层的\(\frac{\partial L(\theta)}{\partial z_{...}}\)才能得到\(\frac{\partial L(\theta)}{\partial z_4}\),\(\frac{\partial L(\theta)}{\partial z_5}\)和\(\frac{\partial L(\theta)}{\partial z_6}\)。一直到计算到输出层时,\(\frac{\partial L(\theta)}{\partial z_7}=\frac{\partial L(\theta)}{\partial y_1}\frac{\partial y_1}{\partial z_7}=\frac{\partial L(\theta)}{\partial y_1}f'(z_7)\),在这里由于损失函数定义为\(L(\theta)=\frac{1}{2}\sum_{i}{(y_i-\widehat{y_{i}})^2}\)因此,\(\frac{\partial L(\theta)}{\partial y_1}=y_1-\widehat{y_{1}}\),训练时真实值\(y_1\)是已知的,而\(\widehat{y_{1}}\)可以通过上一次的参数计算得到。\(\frac{\partial L(\theta)}{\partial z_8}\)和\(\frac{\partial L(\theta)}{\partial z_9}\)的计算也和\(\frac{\partial L(\theta)}{\partial z_7}\)一样。
至于求\(\frac{\partial L(\theta)}{\partial b}\)的过程和求\(\frac{\partial L(\theta)}{\partial w}\)类似。
因此神经网络的求解分为前向和后向两个部分,其中前向就是从输入层开始依次计算后一层的输出,一直到输出层。前向过程可以得到\(\frac{\partial z}{\partial w}\)。后向传播过程就是从输出层开始依次计算前一层的\(\frac{\partial L(\theta)}{\partial z}\)。结合前向和后向过程就能够得到梯度\(\frac{\partial L(\theta)}{\partial w}=\frac{\partial L(\theta)}{\partial z}\frac{\partial z}{\partial w}\)。
用python实现了一个简单的神经网络(每个隐含层的节点数等于输入个数相同)的求解过程。
class NeuralNetwork:
def __init__(self,num_inputs=3, num_hidden=4,learn_rate=0.1):
self.num_inputs=num_inputs
self.num_hidden=num_hidden
self.w=np.random.rand(num_hidden,num_inputs,num_inputs)
self.b=np.random.rand(num_hidden,num_inputs)
self.z=np.zeros([num_hidden,num_inputs])
self.fz=np.zeros([num_hidden,num_inputs])
self.learn_rate=learn_rate
def fit(self,xdata,ydata,step=100):
self.xdata=xdata
self.ydata=ydata
self.ydata_hat=np.zeros([len(xdata)])
for i in range(step):
self.ydata_hat=self.get_y_hat(self.xdata)
self.calcu_loss()
self.bp()
print 'ydata:'
print self.ydata
print 'ydata_hat:'
print self.ydata_hat
def calcu_loss(self):
tmp=self.ydata-self.ydata_hat
loss=np.dot(tmp,tmp)
print 'loss =',loss
return
def f(self,z):
return 1 / (1 + math.exp(-z))
def f_derivative(self,z):
return self.f(z)*self.f(1-z)
def get_y_hat(self,x):
##前向传播
for j in range(self.num_hidden):
for i in range(self.num_inputs):
if j==0:
self.z[j][i]=np.dot(self.w[j][i],x)+self.b[j][i]
else:
self.z[j][i]=np.dot(self.w[j][i],self.fz[j-1])+self.b[j][i]
self.fz[j][i]=self.f(self.z[j][i])
return self.fz[-1]
def bp(self):
##反向传播
partial_z=np.zeros([self.num_hidden,self.num_inputs])
for j in range(self.num_hidden-1,-1,-1):
for i in range(self.num_inputs-1,-1,-1):
if j==self.num_hidden-1:
partial_z[j][i]=(self.ydata_hat[i]-self.ydata[i])*self.f_derivative(self.z[j][i])
else:
partial_z[j][i]=np.dot(self.w[j+1][:,i],partial_z[j+1])*self.f_derivative(self.z[j][i])
partial_w=np.zeros([self.num_hidden,self.num_inputs])
for j in range(self.num_hidden):
for i in range(self.num_inputs):
partial_w[j][i]=self.fz[j][i]*partial_z[j][i]
##更新权值
for j in range(self.num_hidden):
for i in range(self.num_inputs):
self.w[j][i]=self.w[j][i]-self.learn_rate*partial_w[j][i]
self.b[j][i]=self.b[j][i]-self.learn_rate*partial_z[j][i]
return
x=np.random.rand(3)
Network=NeuralNetwork(3,10)
Network.fit(x,x,500)
输出为:
loss = 0.547469323789
loss = 0.536159432604
loss = 0.524672257147
loss = 0.513012035223
loss = 0.50118506728
loss = 0.489199903185
loss = 0.477067497426
loss = 0.464801322584
loss = 0.45241743075
loss = 0.439934453094
loss = 0.427373529142
loss = 0.414758159653
loss = 0.402113980187
.
.
.
loss = 1.01721611578e-05
loss = 1.00128950233e-05
loss = 9.85614814176e-06
loss = 9.70188005636e-06
loss = 9.55005097445e-06
loss = 9.40062175636e-06
loss = 9.25355390437e-06
loss = 9.10880955183e-06
loss = 8.96635145246e-06
ydata:
[ 0.27196578 0.45844752 0.48791713]
ydata_hat:
[ 0.27495838 0.45844681 0.48802049]
从结果可以看出确实在不断接近真实值。
参考:
http://speech.ee.ntu.edu.tw/~tlkagk/courses/ML_2016/Lecture/BP.pdf

 浙公网安备 33010602011771号
浙公网安备 33010602011771号