Neural Multimodal Cooperative Learning Toward Micro-Video Understanding
- 目标
- 解决途径
- 2.1 数据预处理
- 2.2 网络结构
- 结果
- 3.1 度量标准
- 3.2 数据分布
- 3.3 实验结果
-
目标
根据已有的视频推测出视频所在的场景
-
解决途径
-
2.1 数据预处理
- 从Vine上获得了微视频,并从Foursquare上获取了地理位置信息。排除重复的id之后,获得了442类场景信息和276,264个微视频信息。最后为了解决数据类别不平衡的问题,将样本数低于50的微视频类别去掉。最终得到270,145个微视频,分布在118个场景
- 将处理好的视频信息分为三种类别的特征数据,分别是视觉特征,声音特征和文本特征
- 视觉特征,也就是多张单纯的图片帧数据,作者使用了CNN模型,利用ResNet进行高层特征的提取。在此之前,首先利用opencv对微视频选取关键帧。最后,对每一个微视频对所有关键帧利用平均值池化策略产生一个2048维的向量
- 声音特征,就是从微视频中分离出的单纯的声音信号。分离音频信号利用的是FFmpeg,而后将信号变换为统一的格式,即22,050Hz,16bits,而后使用DAE进行特征提取,最终对每个微视频得到一个200维的声音特征
- 文本特征,就是视频的标题等文本特征,作者使用Sentence2Vector提取文本特征并对每一个微视频得到一个100维的特征
- 丢失信息的补全:由于169个微视频缺少声音信号和24,707个微视频缺少文本信号,所以需要对这些信息进行补全,作者使用了低秩矩阵的分解法进行处理
-
2.2 网络结构
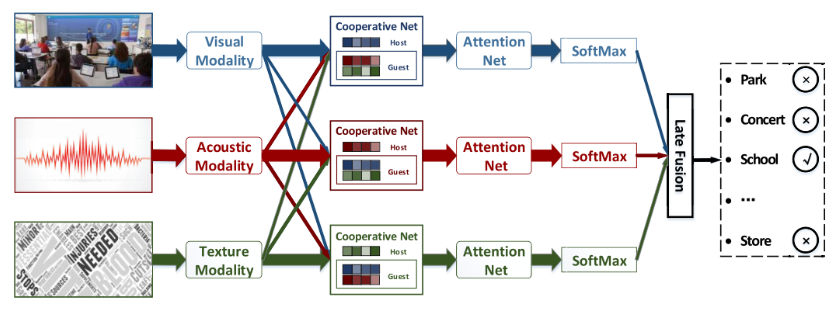
- 主要分为Cooperative Net与Attention Net两个部分,其中的主体是Cooperative Net。见图
![]()
-
Cooperative Net
-
从上图可以看到,Cooperative Net一共有三个,每一个的结构都是类似的,分为host和guest部分,举第一个模块为例,host指的是visual modality,guest则是acoustic modality和texture modality的结合
-
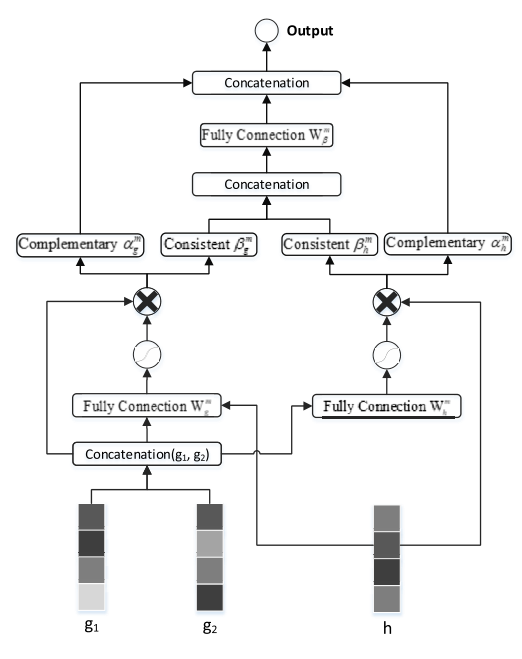
Cooperative Net的内部结构如图所示
![]()
-
将两个不同模态映射到一个共同的空间中 ,可以利用
![]()
式中B表示共同空间表示,A表示从单模态空间映射到共同空间的变换,惩罚项用来约束变换的范数
-
在Cooperative Net中,我们将guest进行融合
![]()
并对host和guest的一致性进行度量,score越高则越一致,否则则不一致,使用
![]()
进行度量
-
进一步地,我们将host和guest输入神经网络中进行学习,形式化为
![]()
可以看到,网络由一个隐藏层和一个softmax层组成
输出的结果代表host score,是用来度量已给guest衍生出host的程度的
类似地,有
![]()
用以度量host衍生出guest的程度
-
而后,我们使用度量出的结果,具体做法是设置一个阈值,高于阈值的,认为信息一致性程度高,否则认为不一致程度高,形式化地,
![]()
而后对该结果进行连续化,得到
![]()
-
通过以上的计算,我们得到了四个描述一致性与不一致性的度量,我们采用逐点相乘的策略使其与host和guest结合,具体地,
![]()
其中alpha表示不一致的向量 ,beta表示一致的向量
-
最后将一致的向量输入神经网络中,得到增强的一致性向量,即
![]()
-
最后,将不一致的向量放入,以进行下一步的学习
![]()
-
由于在最小化一致性成分的不一致性方面遇到了困难,所以我们将其转变为概率分布来计算KL散度。定义概率为
![]()
而后计算KL散度,并将其加入代价函数以最小化
![]()
-
-
Attention Net
-
在该子网络中,我们根据地点的类别对每个特征引入注意力度量并得到度量化的特征,可以看做是注意力机制的一种
-
首先 ,进行
![]()
其中x为Cooperative Net的输出,w为特征的注意力度量,得到的即是j类别度量化的特征度量
-
而后输入全连接层
![]()
得到无偏化的表示
-
最后,输入全连接层,进行预测
![]()
得到分类概率
![]()
对于多模态,可以对各个模态进行融合
![]()
对于该模型,可以定义代价函数为
![]()
融合以上考虑的KL散度模型,最终代价函数可以定义为
![]()
-
-
训练采用梯度下降法
-
-
结果
-
3.1 度量标准
- 采用三种度量标准,分别是 Macro-F1,Micro-F1和 AUC
-
3.2 数据分布
- 数据分为三个部分,分别是训练集,验证集和测试集,数量分别为132, 370,56, 731和81, 044
-
3.3 实验结果
-
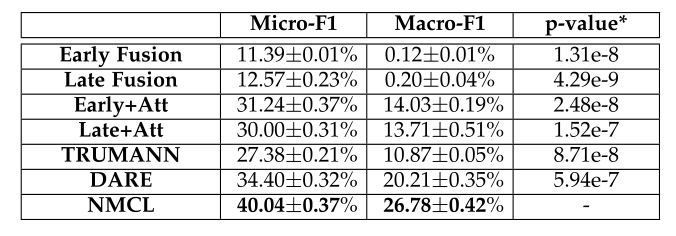
采用6个模型进行参照实验,分别是Early Fusion,Late Fusion,Early+Att,Late+Att,TRUMANN和DARE
-
采用Xavier进行参数初始化,batchsize与learning rate分别设置为{128, 256, 512},
-
表现如下
![]()
-
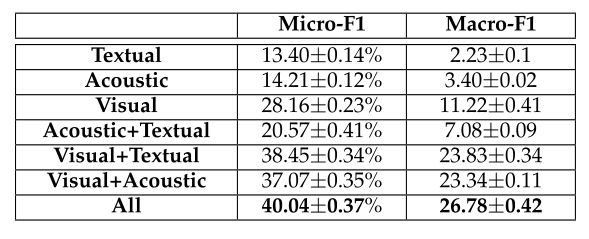
模型中各个成分的贡献如下
![]()
-
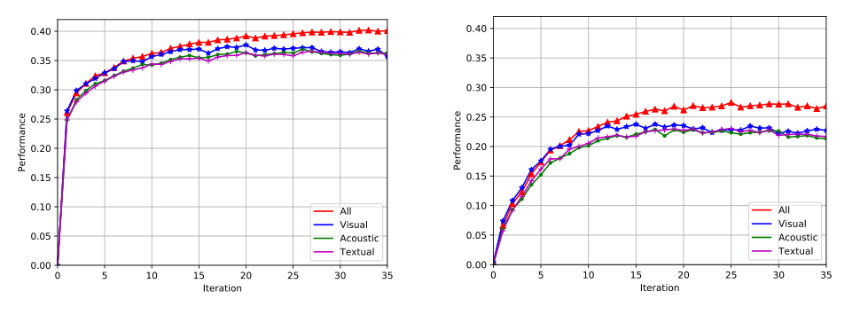
模型在迭代时的收敛以及性能
![]()
-
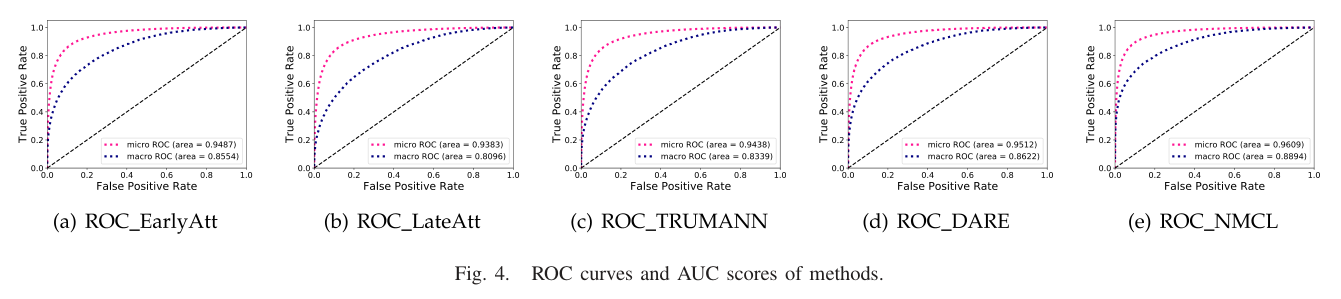
模型的ROC曲线
-
-
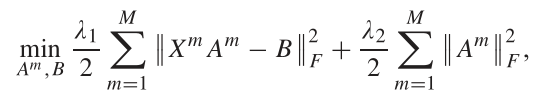

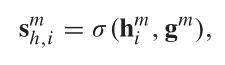
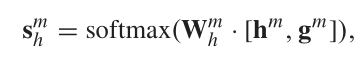
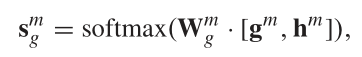
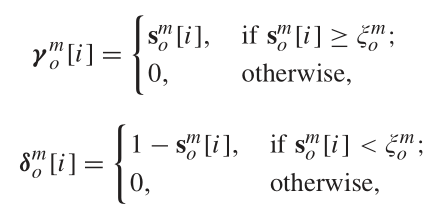
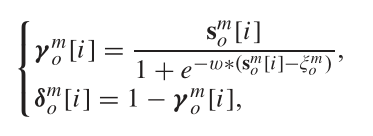
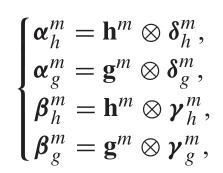
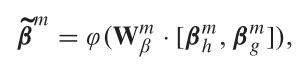
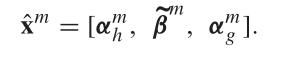
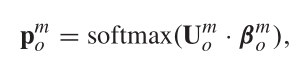
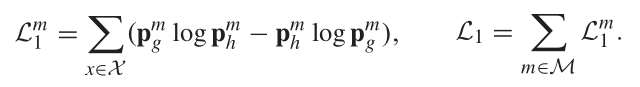
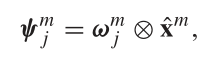
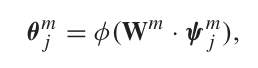
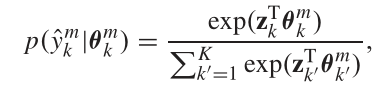
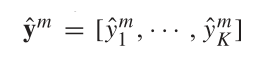
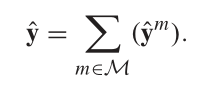
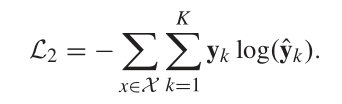
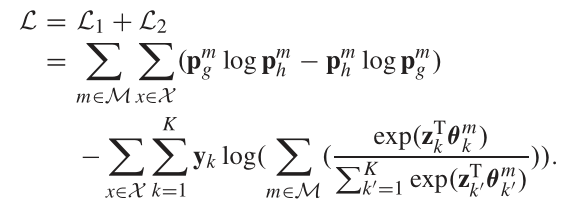

 浙公网安备 33010602011771号
浙公网安备 33010602011771号