
豆瓣top250爬取-cnblog
豆瓣top250爬取
(文末有完整代码)
这是我做的第一个项目,对于初学者来说我觉得这个项目还是很好入手的,首先导入库并且设置好url和请求头
然后我们打开网址和开发者工具,找到我们想要查找的具体的单元,因为接下来我们要从中提取数据找到对应的页面源代码。

用惰性匹配对变化的部分进行替换,用(?P<>.*?)的格式对于需要的数据进行命名保存。因为我们要重复精选多次筛洗,所以这里用compile做预加载

访问的结果用循环读取,以迭代器的形式存在result中,先预存到list中,在用.groupdict的方法取出来。这里因为要对数据进行存储,所以就存到dic中,注意这里的data的中因为多了一个空格所以去除,最后的最后不要忘了关上请求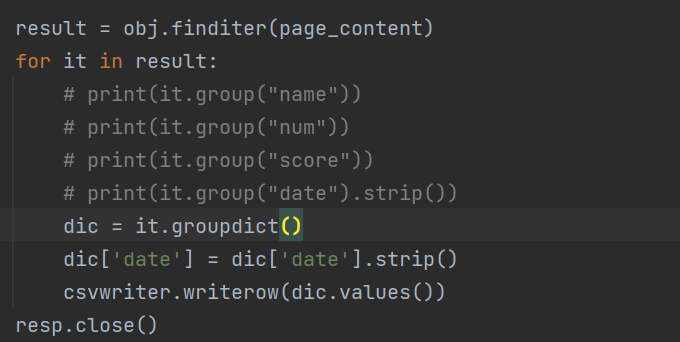
这样我们就完成第一页的爬取,通过观察下一页网址发现https://movie.douban.com/top250?start=25&filter=,翻页的网址由中间的数字提供,通过每页25个达到翻页的目的。我们添加一个循环,在循环中插入变量page每次增加25,总计10次,实现250次读取。
为了避免被当作爬虫拦截,记得在第二次读取前加入time.sleep()进行休息,我这里使用了随机数。
完整代码如下
import re
import requests
import csv
import time
import random
url = "https://movie.douban.com/top250"
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.122"
}
f = open("data.csv", mode="w", encoding="utf-8", newline="")
csvwriter = csv.writer(f) # 创建csv写入对象
page = 0
while page <= 250:
url_page = url + f"?start={page}&filter="
resp = requests.get(url_page, headers=headers)
page_content = resp.text
obj = re.compile(r' <li>.*?<div class="item".*?<span class="title">(?P<name>.*?)</span>'
r'.*? <p>.*?<br>(?P<date>.*?) .*?'
r'<span class="rating_num" property="v:average">(?P<score>.*?)</span>'
r'.*?<span>(?P<num>.*?)</span>', re.S)
result = obj.finditer(page_content)
for it in result:
# print(it.group("name"))
# print(it.group("num"))
# print(it.group("score"))
# print(it.group("date").strip())
dic = it.groupdict()
dic['date'] = dic['date'].strip()
csvwriter.writerow(dic.values())
resp.close()
waite = random.randint(1, 5) # 产生随机的休息时间 1~5秒之间
time.sleep(waite)
page += 25 # 翻页页号
print(f"收集到前{page}个")
f.close()
print("over!")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号