机器学习之异常检测
异常检测
异常检测(Anomaly Detection):根据输入数据,对不符合预期模式的数据进行识别
概率密度
概率密度:描述随机变量在某个确定的取值点附近的可能性的函数

- 计算数据均值µ,标准差σ
- 计算对应的高斯分布概率函数
- 根据数据点概率,进行判断,如果p(x) < ε;该点为异常点
当数据维度高于一维时:
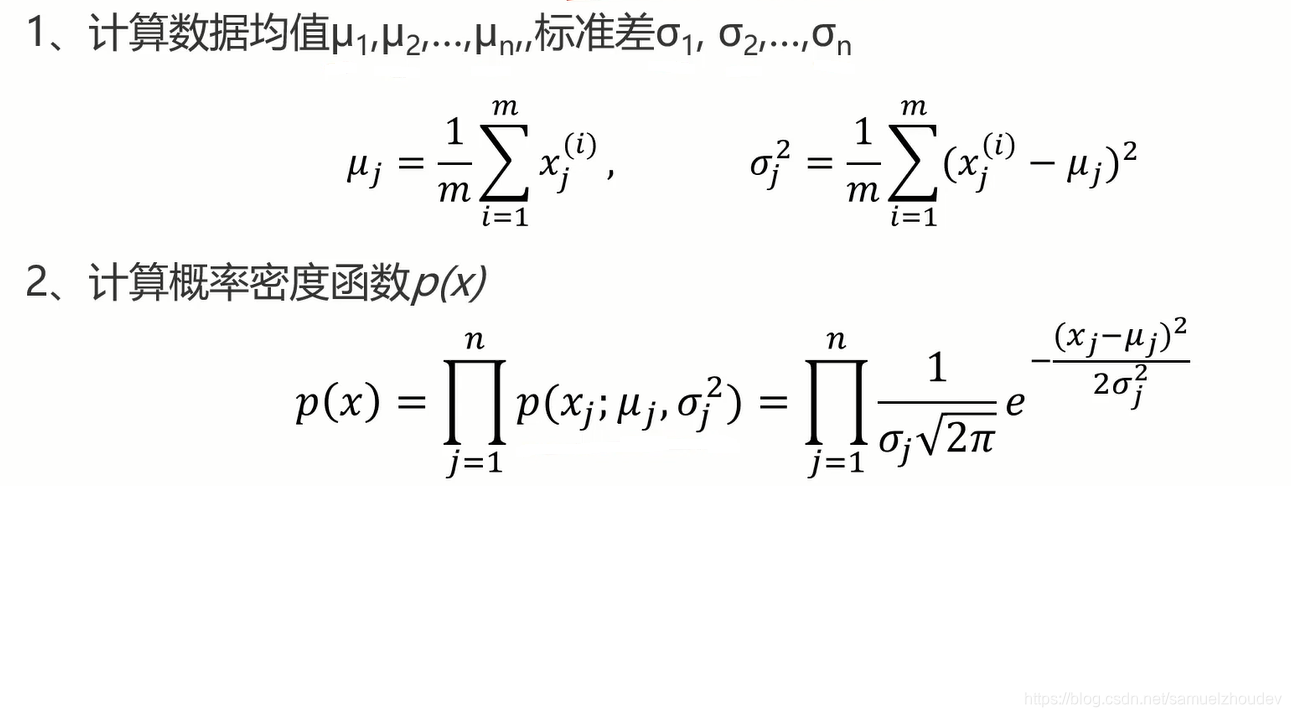
同理,根据数据点概率,进行判断,如果p(x) < ε;该点为异常点
代码实现
#数据分布统计
plt.hist(x1,bins = 100)
#计算数据均值、标准差
x1_mean = x1.mean()
x1_sigma = x1.std()
# 计算对应的高斯分布数值:
from scipy.stats import norm
x1_range = np.linspace(0,20,300)
normal1 = norm.pdf(x1_range,x1_mean,x1_sigma)
# 可视化高斯分布曲线:
Plt.plot(x1_range,normal1)
# 模型训练:
from sklearn.covariance import EllipticEnvelope
clf = EllipticEnvelope()
clf.fit(data)
# 可视化异常数据:
anamoly_points = plt.scatter(
data.loc[:,'x1'][y_predict == -1],
data.loc[:,'x2'][y_predcit == -1],
marker = "o",
facecolor = "none",
edgecolor = "red", s = 250
)
好文可以于大家分享,请注明转载

 浙公网安备 33010602011771号
浙公网安备 33010602011771号