

云区域(region),可用区(AZ),跨区域数据复制(Cross-region replication)与灾备(Disaster Recovery)(部分2)
本文分两部分:部分1 和 部分2。部分1 介绍 AWS,部分2 介绍阿里云和OpenStack云。
2. 阿里云
2.1 阿里云各产品的HA和DR能力
阿里云为全世界多个地域提供云计算服务,每个地域(Region)都包含多个可用区(Avzone)。 同一个地域下的可用区都被设计为相互之间网络延迟很小(3ms 以内)以及故障隔离的单元。

SLB: 当前提供的负载均衡实例大多是多可用区实例,主备实例在同城不同可用区机房,当主实例机房出现故障,能及时进行切换,来实现容灾和服务的高可用性。
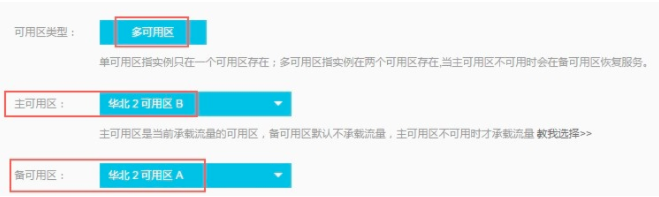
RDS:
- 双机高可用版RDS:也就是RDS单可用区版本,是指RDS实例的主备节点处于相同的可用区。如果ECS和RDS部署在相同的可用区,网络延时更小。在主实例出现故障时候可以进行主备切换,具有高可用和容灾特性。两个实例运行在同一个可用区下的两台物理服务器上,可用区内机柜、空调、 电路、网络都有冗余。通过半同步的数据复制方式和高效的 HA 切换机制,RDS 为用户提供了高于物理服务器极限的数据库可用性。
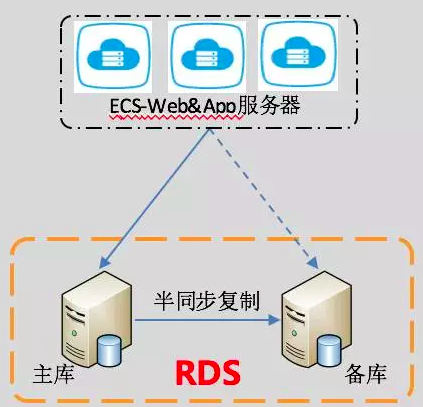
- 多可用区RDS:
为了提供比单可用区实例更高的可用性,RDS 支持多可用区实例(也叫做同城双机房或者同城容灾实例 )。多可用区实例将主备实例部署在不同的可用区,当一个可用区(A) 出现故障时流量可以在短时间内切换到另一个可用区(B)。 整个切换过程对用户透明,应 用代码无需变更。
注意:发生容灾切换时应用到数据库的连接会断开,需要应用重新连接 RDS。只有部分地域有多可用区RDS。

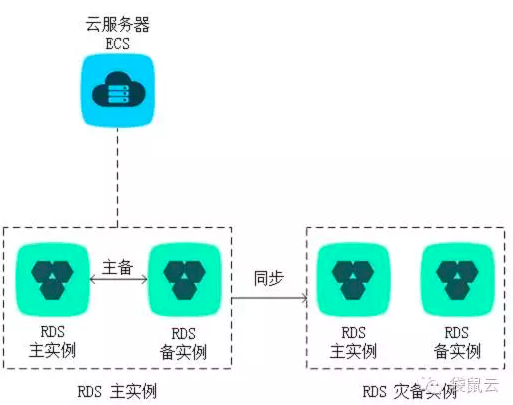
- 跨域容灾实例:RDS 多可用区实例的容灾能力局限在同地域的不同可用区之间。为了提供更高的可用性, RDS 还支持跨地域的数据容灾。 用户可以将地域 A 的 RDS 实例 A’通过数据传输(Data Transmission)异步复制到地域 B 的 RDS 实例 B’(实例 B’是一个完整独立的 RDS 实 例,拥有独 立 的连接地址、账号和权限)。
因此,为了支持跨域容灾,RDS之间还可以用DTS同步和迁移数据,即分别在可用区A和B购买双机高可用RDS,然后创建DTS同步。
配置了跨域容灾实例后,当实例 A’所在地域发生短期不可恢复的重大故障时,用户在另外一个地域的实例 B’随时可以进行容灾切换。切换完成后,用户通过修改应用程序中的数 据库连接配置,可以将应用请求转到实例 B’上,进而获得高于地域极限的数据库可用性。

RDS 数据复制方式有以下三种方式:
- 异步复制(Async):应用发起更新(含增加、删除、修改操作)请求,Master 完成相应操作后立即 响应应用,Master 向 Slave 异步复制数据。因此异步复制方式下, Slave 不可用不影响主库上的操 作,而 Master 不可用有较小概率会引起数据不一致。
- 强同步复制(Sync):应用发起更新(含增加、删除、修改操作)请求,Master 完成操作后向 Slave 复制数据,Slave 接收到数据后向 Master 返回成功信息,Master 接到 Slave 的反馈后再响应 应用。Master 向 Slave 复制数据是同步进行的,因此 Slave 不可用会影响 Master 上的操作,而 Master 不可用不会引起数据不一致。
- 半同步复制(Semi-Sync):正常情况下数据复制方式采用强同步复制方式,当 Master 向 Slave 复 制数据出现异常的时候(Slave 不可用或者双节点间的网络异常),Master 会暂停对应用的响应,直 到复制方式超时退化成异步复制。如果允许应用在此时更新数据,则 Master 不可用会引起数据不一 致。当双节点间的数据复制恢复正常(Slave 恢复或者网络恢复),异步复制会恢复成强同步复制。 恢复成强同步复制的时间取决于半同步复制的实现方式,阿里云数据库 MySQL5.5 版和 MySQL5.6 版有所不同。
2.2 阿里云的容灾部署架构
2.2.1 基础容灾架构
在阿里云平台上,对于中小型企业,业务量不是特别大,对异地容灾要求不是特别强烈,则可采用以下高可用方案,可以在同一地域下选择购买云产品。建议在VPC网络环境下,选择同一可用区或者同地域不同可用区的云产品。
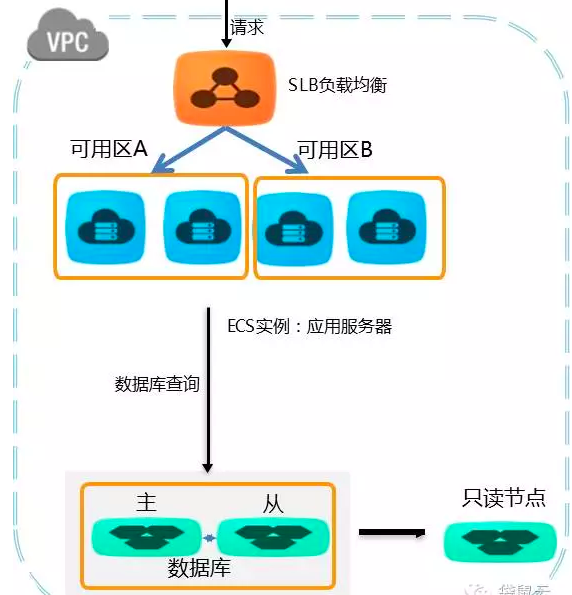
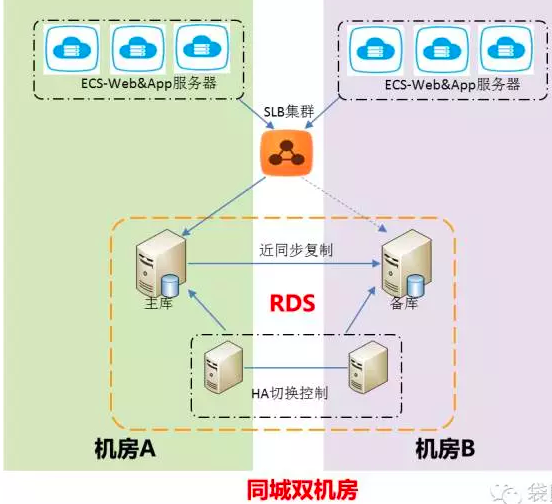
2.2.2 同城容灾架构
对中大型用户来说,希望业务系统要求具备同城容灾的能力,可以考虑在同城不同可用区之间对原有应用架构做一套完整的备份。如果某个可以去出现像IDC机房断电或者火灾等故障时,可以通过前端切换DNS来及时恢复业务。

备注:我认为从Intenet到右边方框的线条应该为为虚线,因为右边的环境在正常情况下不提供服务,而只有在左边环境不可用后切换到右边环境。
2.2.3 跨城市容灾
对于一些大型企业在业务安全全性、服务可用性和数据可靠性方面既要求具备同城容灾又要求具备异地容灾时,可以采用这种容灾架构方式既可以解决单机房故障也可以应对像地震等灾难性故障。
不同地域之间可以采用阿里云的高速通道进行私网通信,保障数据库之间的数据实时同步,将数据传输延迟降到最低。故障发生时可以通过前端DNS实现秒级切换,及时恢复业务。
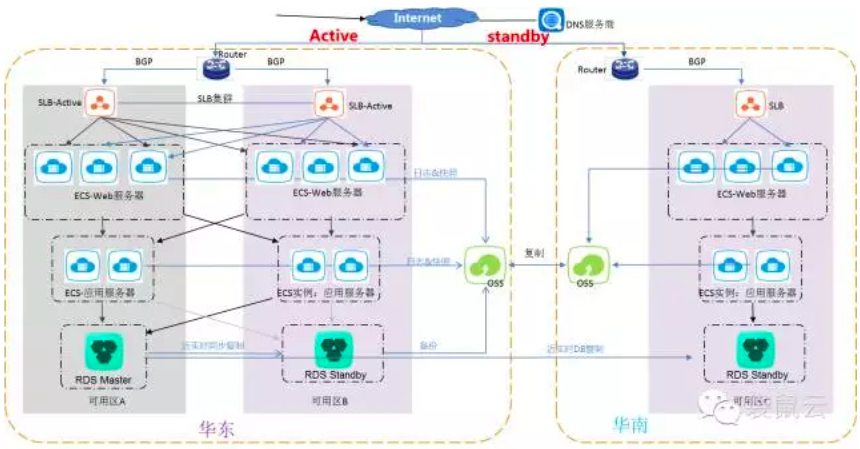
说明:图上华东的两个环境可以同时运行,因为都是采用可用区A里面的 RDS-Master,当可用区A不可用时,会切换到使用可用区B 中的 RDS-Standy;当华东整个区域不可用时,会切换到华南区域中的环境。
3. OpenStack云
3.1 OpenStack 中的有关概念

要在OpenStack环境中实现AWS那样的AZ架构还是非常不容易的,主要困难包括但不限于:
- 网络层:AZ IDC之间的大二层物理网络,SDN 网络,跨区域网络等
- 存储层:对象存储跨区域复制;数据备份到对象存储,现在的cinder backup 功能还是很弱;其它各种备份功能;
- 平台层:跨IDC的OpenStack部署架构,跨AZ的虚机迁移,大规模节点纳管,CMP实现等
在实际实现中,看到较多的案例都是每个IDC内搭建一个OpenStack region,然后在region 内实现以机架为单元的可用区。
3.2 容灾
3.2.1 容灾架构
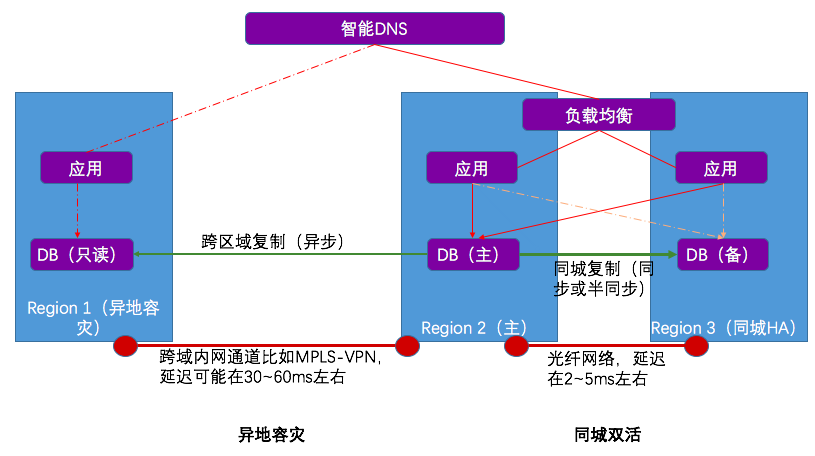
3.2.2 容灾场景
根据AWS 上容灾的四个场景,对OpenStack 云容灾做下总结:
| 容灾场景 | OpenStack 云 | 不足和问题 |
| 备份&恢复 |
1. 将虚机的系统盘打包为自有镜像,保存到对象存储中 2. 对磁盘做快照 3. 对磁盘做备份 |
1. 如果对象存储不能跨区域复制的话,那么无法跨区域拷贝自有镜像 2. 磁盘备份的效率比较低,而且受限于对象存储的跨区域复制能力 |
| Pilot Light(Cold Standny) | 在另一个region上创建数据库实例,并设置数据同步机制 |
1. 数据同步方式是采用同步的还是异步的,如何处理数据不一致 2. 恢复是需要回复应用环境,但受限于跨区域的应用系统镜像拷贝能力,很多情况下需要手工搭建应用环境 |
| 温备 (Warm Standby) | 在另一个region 上创建完整的但规格较小的热备环境,但不提供服务 |
1. 跨数据中心的流量切换手段。如果是公网,可以借助公有云的智能DNS;如果是内网,则需要搭建跨数据中心的负载均衡。 2. 数据同步问题同上 3. 虚机镜像问题同上 |
| 热备 (Hot Standby) | 在另一个region 上创建完整但规格较小的运行环境,承担少部分生产流量 |
1. 跨region 流量分流手段。如果是公网,可以借助公有云的智能DNS;如果是内网,则需要搭建跨数据中心的负载均衡。 2. 数据同步问题同上 3. 虚机镜像问题同上 |
参考链接:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号