

在Kubernetes上运行有状态应用:从StatefulSet到Operator
一开始Kubernetes只是被设计用来运行无状态应用,直到在1.5版本中才添加了StatefulSet控制器用于支持有状态应用,但它直到1.9版本才正式可用。本文将介绍有状态和无状态应用,一个通过K8S StatefulSet来编排有状态应用的示例,以及当前有状态应用容器化现状及将来的发展趋势。
1. 有状态应用和无状态应用
无状态应用(Stateless Application)是指应用不会在会话中保存下次会话所需要的客户端数据。每一个会话都像首次执行一样,不会依赖之前的数据进行响应。有状态的应用(Stateful Application)是指应用会在会话中保存客户端的数据,并在客户端下一次的请求中来使用那些数据。
以服务器端组件为例,判断它是有状态的还是无状态的,其依据是两个来自相同发起者的请求在服务器端是否具备上下文关系。如果是有状态的,那么服务器端一般都要保存请求的相关信息,每个请求可以使用以前的请求信息。而如果是无状态的,其处理的过程必须全部来自于请求所携带的信息,以及其他服务器端自身所保存的、并且可以被所有请求所使用的公共信息。最著名的无状态的服务器应用是WEB服务器。每次HTTP请求和以前都没有啥关系,只是获取目标URI。得到目标内容之后,这次连接就被杀死,没有任何痕迹。有状态的服务器应用有更广阔的应用范围,比如网络游戏等服务器。它在服务端维护每个连接的状态信息,服务端在接收到每个连接的发送的请求时,可以从本地存储的信息来重现上下文关系。这样,客户端可以很容易使用缺省的信息,服务端也可以很容易地进行状态管理。比如说,当一个用户登录后,服务端可以根据用户名获取他的生日等先前的注册信息;而且在后续的处理中,服务端也很容易找到这个用户的历史信息。
一个大型应用往往具有许多功能模块,很难简单地将其整体性地设计为有状态或无状态的,而往往将其整个架构分成两个部分,即无状态部分和有状态部分。业务逻辑部分往往作为无状态的部分,而将状态保存在有状态的中间件中,如缓存、数据库、对象存储、大数据平台、消息队列等。这样无状态的部分可以很容易的横向扩展,而状态保存到后端。而后端的中间件是有状态的,这些中间件设计之初,就考虑了扩容的时候状态的迁移、复制、同步等机制,不用业务层关心。
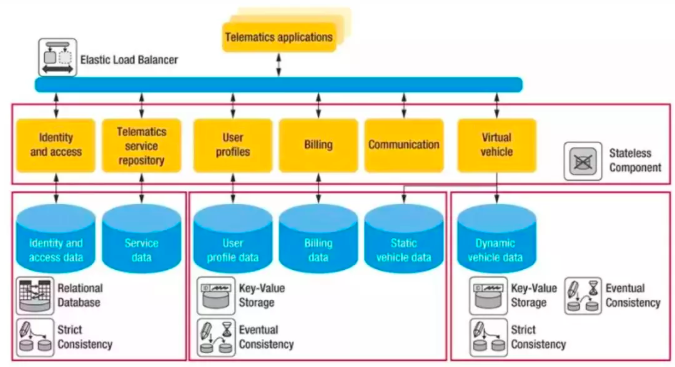
(来源:刘超博文)
通常应用会有如下几种状态数据:
-
持久性状态数据:这种状态数据在应用重启或宕机时需要能被保存下来。典型地,这种状态会被保存到一个冗余的数据库层,而且数据会被周期性地备份。建议将应用组件和数据库分开,以便能使得应用组件变成无状态的。
-
配置状态数据:应用总是会用各种配置数据,比如数据库连接字符串等,过去往往保存在配置文件中。进行容器化时,配置文件应该外部化,或环境变量,或配置中心管理。
-
会话状态数据:每当用户登录进应用后,应用都会为它产生会话数据。在现代应用中,会话数据都会保存在分布式缓存中,因此可以被所有服务实例访问到。但是在传统web应用中,会话数据会被保存在服务器本地,因此,登录后的该用户的所有请求都必须在这台服务器上才能被处理,这就是所谓的粘滞会话(sticky session)。
-
连接状态:一些应用使用有状态通信协议,比如Websocket。另外一些协议比如HTTP被认为是无状态的。对于使用有状态协议的应用,客户端的访问必须被路由到指定的容器内。
-
集群状态:某些应用以集群形式运行多个实例,以满足可用性和规模性。在这种应用中,集群内每个成员需要了解其他成员的状态和角色,比如MySQL集群。现在,Kubernetes提供了StatefulSet控制器来支持这种应用。
-
日志数据:传统应用的日志通过保存在日志文件中。进行容器化时,要对日志输出格式进行改造,适配集中式日志系统规范,和容器运行时的日志组件对接,使得日志能通过标准输出被收集到再保存到统一容器存储中。

(来源:刘超博文)
2. Kubernetes StatefulSet控制器
常见的Kubernetes控制器不合适处理有状态应用:

2.1 Kubernetes StatefulSet概述
Kubernetes在1.9版本中正式发布的StatefulSet控制器能支持:
-
Pod会被顺序部署和顺序终结:StatefulSet中的各个 Pod会被顺序地创建出来,每个Pod都有一个唯一的ID,在创建后续 Pod 之前,首先要等前面的 Pod 运行成功并进入到就绪状态。删除会销毁StatefulSet 中的每个 Pod,并且按照创建顺序的反序来执行,只有在成功终结后面一个之后,才会继续下一个删除操作。
-
Pod具有唯一网络名称:Pod具有唯一的名称,而且在重启后会保持不变。通过Headless服务,基于主机名,每个 Pod 都有独立的网络地址,这个网域由一个Headless 服务所控制。这样每个Pod会保持稳定的唯一的域名,使得集群就不会将重新创建出的Pod作为新成员。
-
Pod能有稳定的持久存储:StatefulSet中的每个Pod可以有其自己独立的PersistentVolumeClaim对象。即使Pod被重新调度到其它节点上以后,原有的持久磁盘也会被挂载到该Pod。
-
Pod能被通过Headless服务访问到:客户端可以通过服务的域名连接到任意Pod。
以在K8S中部署高可用的PostgreSQL集群为例,下面是其架构示意图:
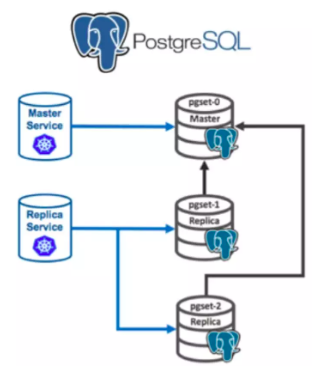
该架构中包含一个主节点和两个副本节点共3个Pod,这三个Pod在一个StatefulSet中。Master Service是一个Headless服务,指向主Pod,用于数据写入;Replica Service也是一个Headless服务,指向两个副本Pod,用于数据读取。这三个Pod都有唯一名称,这样StatefulSet让用户可以用稳定、可重复的方式来部署PostgreSQL集群。StatefulSet不会创建具有重复ID的Pod,Pod之间可以通过稳定的网络地址互相通信。
2.2 使用Kubernetes StatefulSet部署高可用MySQL
当前命名空间为testmysql。
(1)创建ConfigMap,用于向mysql传递配置文件。
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql
labels:
app: mysql
data:
master.cnf: |
#Apply this config only on the master.
[mysqld]
log-bin
slave.cnf: |
#Apply this config only on slaves.
[mysqld]
super-read-only
(2)创建StatefulSet对象,它会负责创建Pod。 apiVersion: apps/v1 kind: StatefulSet metadata: name: mysql spec: selector: matchLabels: app: mysql serviceName: mysql replicas: 3 template: metadata: labels: app: mysql spec: initContainers: - name: init-mysql image: mysql:5.7 command: - bash - "-c" - | set -ex # Generate mysql server-id from pod ordinal index. [[ `hostname` =~ -([0-9]+)$ ]] || exit 1 ordinal=${BASH_REMATCH[1]} echo [mysqld] > /mnt/conf.d/server-id.cnf # Add an offset to avoid reserved server-id=0 value. echo server-id=$((100 + $ordinal)) >> /mnt/conf.d/server-id.cnf # Copy appropriate conf.d files from config-map to emptyDir. if [[ $ordinal -eq 0 ]]; then cp /mnt/config-map/master.cnf /mnt/conf.d/ else cp /mnt/config-map/slave.cnf /mnt/conf.d/ fi volumeMounts: - name: conf mountPath: /mnt/conf.d - name: config-map mountPath: /mnt/config-map - name: clone-mysql image: gcr.io/google-samples/xtrabackup:1.0 command: - bash - "-c" - | set -ex # Skip the clone if data already exists. [[ -d /var/lib/mysql/mysql ]] && exit 0 # Skip the clone on master (ordinal index 0). [[ `hostname` =~ -([0-9]+)$ ]] || exit 1 ordinal=${BASH_REMATCH[1]} [[ $ordinal -eq 0 ]] && exit 0 # Clone data from previous peer. ncat --recv-only mysql-$(($ordinal-1)).mysql 3307 | xbstream -x -C/var/lib/mysql # Prepare the backup. xtrabackup --prepare --target-dir=/var/lib/mysql volumeMounts: - name: data mountPath: /var/lib/mysql subPath: mysql - name: conf mountPath: /etc/mysql/conf.d containers: - name: mysql image: mysql:5.7 env: - name: MYSQL_ALLOW_EMPTY_PASSWORD value: "1" ports: - name: mysql containerPort: 3306 volumeMounts: - name: data mountPath: /var/lib/mysql subPath: mysql - name: conf mountPath: /etc/mysql/conf.d resources: requests: cpu: 500m memory: 1Gi livenessProbe: exec: command: ["mysqladmin", "ping"] initialDelaySeconds: 30 periodSeconds: 10 timeoutSeconds: 5 readinessProbe: exec: # Check we can execute queries over TCP (skip-networking is off). command: ["mysql", "-h", "127.0.0.1","-u", "root", "-e", "SELECT 1"] initialDelaySeconds: 5 periodSeconds: 2 timeoutSeconds: 1 - name: xtrabackup image: gcr.io/google-samples/xtrabackup:1.0 ports: - name: xtrabackup containerPort: 3307 command: - bash - "-c" - | set -ex cd /var/lib/mysql # Determine binlog position of cloned data, if any. if [[ -f xtrabackup_slave_info &&"x$(<xtrabackup_slave_info)" != "x" ]]; then # XtraBackup already generated a partial "CHANGE MASTER TO"query # because we're cloning from an existing slave. (Need to remove thetailing semicolon!) cat xtrabackup_slave_info | sed -E 's/;$//g' >change_master_to.sql.in # Ignore xtrabackup_binlog_info in this case (it's useless). rm -f xtrabackup_slave_info xtrabackup_binlog_info elif [[ -f xtrabackup_binlog_info ]]; then # We're cloning directly from master. Parse binlog position. [[ `cat xtrabackup_binlog_info` =~ ^(.*?)[[:space:]]+(.*?)$ ]] || exit 1 rm -f xtrabackup_binlog_info xtrabackup_slave_info echo "CHANGE MASTER TO MASTER_LOG_FILE='${BASH_REMATCH[1]}',\ MASTER_LOG_POS=${BASH_REMATCH[2]}"> change_master_to.sql.in fi # Check if we need to complete a clone by starting replication. if [[ -f change_master_to.sql.in ]]; then echo "Waiting for mysqld to be ready (accepting connections)" until mysql -h 127.0.0.1 -u root-e "SELECT 1"; do sleep 1; done echo "Initializing replication from clone position" mysql -h 127.0.0.1 -u root \ -e"$(<change_master_to.sql.in), \ MASTER_HOST='mysql-0.mysql',\ MASTER_USER='root', \ MASTER_PASSWORD='', \ MASTER_CONNECT_RETRY=10; \ START SLAVE;" ||exit 1 # In case of container restart, attempt this at-most-once. mv change_master_to.sql.in change_master_to.sql.orig fi # Start a server to send backups when requested by peers. exec ncat --listen --keep-open --send-only --max-conns=1 3307 -c \ "xtrabackup --backup --slave-info --stream=xbstream--host=127.0.0.1 --user=root" volumeMounts: - name: data mountPath: /var/lib/mysql subPath: mysql - name: conf mountPath: /etc/mysql/conf.d resources: requests: cpu: 100m memory: 100Mi volumes: - name: conf emptyDir: {} - name: config-map configMap: name: mysql volumeClaimTemplates: -metadata: name: data spec: accessModes: ["ReadWriteOnce"] storageClassName: "nfs" resources: requests: storage: 2Gi
(3)创建服务,用于访问mysql集群。
# Headless service for stable DNS entriesof StatefulSet members.
apiVersion: v1
kind: Service
metadata:
name: mysql
labels:
app: mysql
spec:
ports:
-name: mysql
port: 3306
clusterIP: None
selector:
app: mysql
---
# Client service for connecting to anyMySQL instance for reads.
# For writes, you must instead connect tothe master: mysql-0.mysql.
apiVersion: v1
kind: Service
metadata:
name: mysql-read
labels:
app: mysql
spec:
ports:
-name: mysql
port: 3306
selector:
app: mysql
2.3 MySQL StatefulSet实例
(1)一个StatefulSet对象
NAME DESIRED CURRENT AGE
statefulset.apps/mysql 2 2 2d
(2)三个Pod
[root@master1 ~]# oc get pod
NAME READY STATUS RESTARTS AGE
mysql-0 2/2 Running 0 2d
mysql-1 2/2 Running 0 2d
mysql-2 2/2 Running 0 2d
StatefulSet 控制器创建出三个Pod,每个Pod使用数字后缀来区分顺序。创建时,首先mysql-0 Pod被创建出来,然后创建mysql-1 Pod,再创建mysql-2 Pod。
(3)两个服务
[root@master1 ~]# oc get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE mysql ClusterIP None <none> 3306/TCP 2d mysql-read ClusterIP 172.30.169.48 <none> 3306/TCP 2d
mysql服务是一个Headless服务,它没有ClusterIP,只是为每个Pod提供一个域名,三个Pod的域名分别是:
-
mysql-0.mysql.testmysql.svc.cluster.local
-
mysql-1.mysql.testmysql.svc.cluster.local
-
mysql-2.mysql.testmysql.svc.cluster.local
mysql-read 服务则是一个ClusterIP服务,作为集群内部的负载均衡,将数据库读请求分发到后端的两个Pod。
(4)三个PVC
[root@master1 ~]# oc get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
data-mysql-0 Bound pvc-98a6f5c9-11a9-11ea-b651-fa163e71648a 2Gi RWO nfs 2d
data-mysql-1 Bound pvc-845c0eae-11bb-11ea-b651-fa163e71648a 2Gi RWO nfs 2d
data-mysql-2 Bound pvc-018762f6-11bc-11ea-b651-fa163e71648a 2Gi RWO nfs 2d
每个pvc和一个pod相对应,从名字上也能看出来其对应关系。mysql Pod的 /var/lib/mysql 文件夹保存在PVC卷中。
2.4 MySQL 集群操作
(1)集群访问
客户端通过 mysql-0.mysql.testmysql.svc.cluster.local 域名来向数据库写入数据:
[root@master1 ~]# mysql -h mysql-0.mysql.testmysql.svc.cluster.local -P 3306 -u root
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MySQL connection id is 142230
Server version: 5.7.28-log MySQL Community Server (GPL)
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MySQL [(none)]> show databases;
客户端通过 mysql-read.testmysql.svc.cluster.local 域名来从数据库读取数据:
[root@master1 ~]# mysql -h mysql-read.testmysql.svc.cluster.local -P 3306 -u root
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MySQL connection id is 142318
Server version: 5.7.28-log MySQL Community Server (GPL)
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MySQL [(none)]> show databases;
(2)集群扩容
当前的MySQL集群,具有一个写节点(mysql-0)和两个读节点(mysql-1和mysql-2)。如果要提升读能力,可以对StatefulSet对象扩容,以增加读节点。比如以下命令将总Pod数目扩大到4,读Pod数目扩大到3.
oc scale statefulset mysql --replicas=4
(3)集群缩容
运行以下命令,将集群节点数目缩容到3:
oc scale statefulset mysql --replicas=3
然后mysql-3 Pod会被删除:
[root@master1 ~]# oc get pod
NAME READY STATUS RESTARTS AGE
mysql-0 2/2 Running 0 2d
mysql-1 2/2 Running 0 2d
mysql-2 2/2 Running 0 2d
mysql-3 2/2 Terminating 0 2m
3. Kubernetes Operator
StatefulSet 无法解决有状态应用的所有问题,它只是一个抽象层,负责给每个Pod打上不同的ID,并支持每个Pod使用自己的PVC卷。但有状态应用的维护非常复杂,否则每个公司也不用有一个独立的DBA团队来负责管理数据库。从上文也能看出,通过StatefulSet实例的操作,也只能做到创建集群、删除集群、扩缩容等基础操作,但比如备份、恢复等数据库常用操作,则无法实现。
3.1 Kubernetes Operator概述
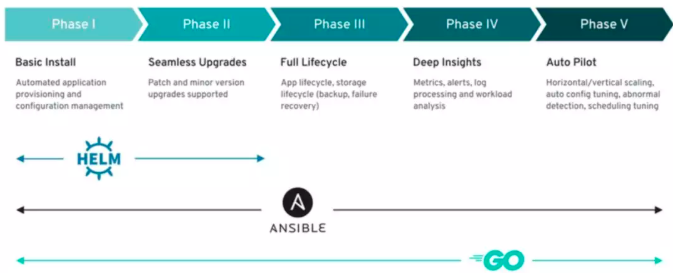
基于此,CoreOS团队提出了K8SOperator概念。Operator是一个自动化的软件管理程序,负责处理部署在K8S和OpenShift上的软件的安装和生命周期管理。它包含一个Controller和CRD(Custom Resource Definition),CRD扩展了K8S API。其基本模式如下图所示:
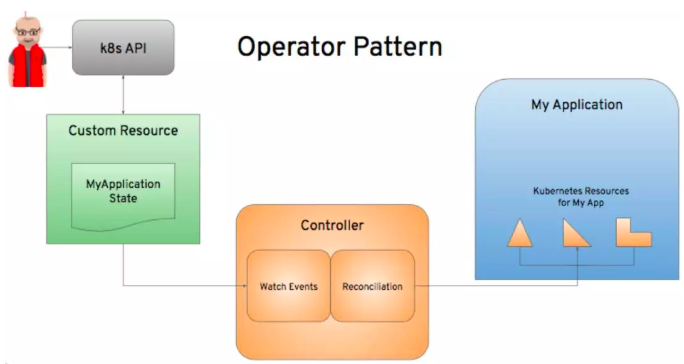
OpenShift 在V4中发布了全新的OperatorHub,集成了原厂商的或第三方的或RedHat开发的各种Operator,用来部署和维护相应的服务。
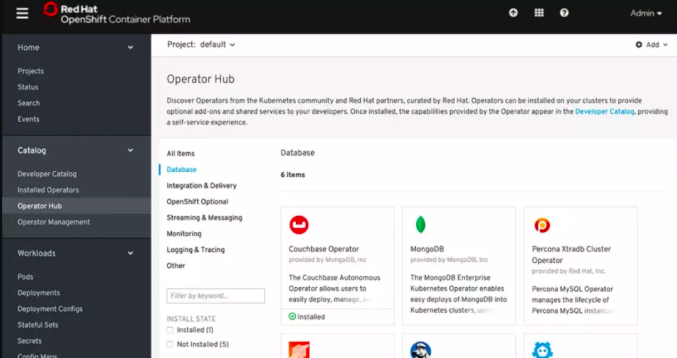
Operator可以很简单,比如只负责软件安装,也可以很复杂,比如软件更新、完整生命周期管理、监控告警甚至自动伸缩等等。
3.2 MySQL Operator
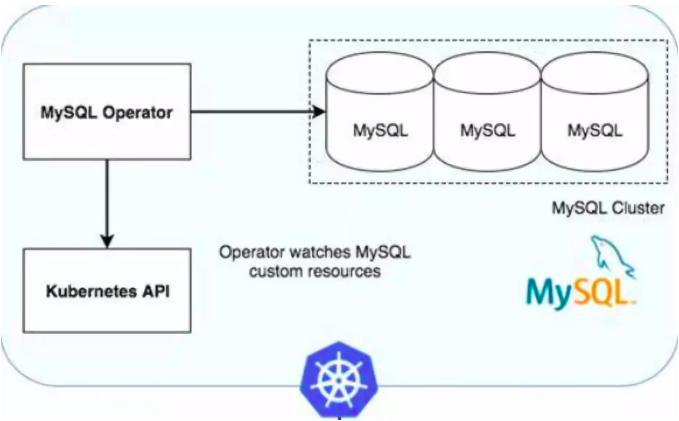
一年以前,Oracle在github上开源了K8S MySQL Operator,它能在K8S上创建、配置和管理MySQL InnoDB 集群,其地址是https://github.com/oracle/mysql-operator。其主要功能包括:
-
在K8S上创建和删除高可用的MySQL InnoDB集群
-
自动化数据库的备份、故障检测和恢复操作
-
自动化定时备份和按需备份
-
通过备份恢复数据库
其基本架构如下图所示:
定义一个1主2备MySQL集群:
apiVersion: mysql.oracle.com/v1alpha1
kind: Cluster
metadata:
name: mysql-test-cluster
spec:
members: 3
定义一个3主集群:
apiVersion: mysql.oracle.com/v1alpha1
kind: Cluster
metadata:
name: mysql-multimaster-cluster
spec:
multiMaster: true
members: 3
创建一个到S3的备份:apiVersion: "mysql.oracle.com/v1"
kind: MySQLBackup
metadata:
name: mysql-backup
spec:
executor:
provider: mysqldump
databases:
- test
storage:
provider: s3
secretRef:
name: s3-credentials
config:
endpoint: x.compat.objectstorage.y.oraclecloud.com
region: ociregion
bucket: mybucket
clusterRef:
name: mysql-cluster
详细信息,请阅读 github项目文档以及https://blogs.oracle.com/developers/introducing-the-oracle-mysql-operator-for-kubernetes博文。可惜的是,已经快有一年该项目没什么更新了。4. 展望未来
通过K8S Operator实现常见运维操作是容易的,但对于复杂问题,Operator要么会做得非常复杂,但也可能无法面面俱到,对某些复杂场景甚至会无能为力。以etcd Operator为例,其开源项目地址是 https://github.com/coreos/etcd-operator。etcd本身应该不算特别复杂的有状态应用,etcd Operator的功能看起来也很基础,主要包括创建和删除集群、扩缩容、切换、滚动升级、备份和回复等基础功能,但其代码超过了9000行。
因此,Operator要解决“有“的问题还相对容易,但要解决”好“的问题,确实非常困难。这是因为管理有状态应用本来就是非常困难的,更何况在容器云平台上进行管理。从技术上讲,维护有状态数据非常困难。大量研究和方式都被提了出来,比如冗余、高可用等等,但问题并没彻底解决。从商务上讲,所有云供应商都提供了托管数据库服务。因此,他们没有太大兴趣去提供另一个会跟他们直接竞争的方案,也许Oracle没继续更新K8S MySQL Operator项目也有这方面的考虑。从实际情况来看,在传统企业中,数据库的架构变迁一直就很缓慢,很多企业的数据库还部署在小机上,部分数据库部署在x86物理机上,部分数据库部署在虚拟机上。
因此,短期内,对于生产环境,需要有稳定性,因此如果你用公有云,那就使用公有云的各种托管服务,将你的精力更多用到业务应用自身上吧;如果你用私有云,对生产环境来说,短期内有状态应用还是放在虚拟化环境甚至物理机环境上,然后安排专业运维团队来维护吧。对于开发测试环境,可以自己通过K8S StatefulSet来做编排或者使用Operator,来利用其便捷性。
但是,有状态应用要想在K8S上生产就绪地运行,目前来看,Operator也许是最可行的路径,这也是为什么RedHat在上面大量投入的原因。可以想象,在将来所有要发布在K8S上的应用,厂商在发布软件时都会发布对应的Operator。其实现在已经有厂商这么做了,比如PingCAP公司已经发布了TiDB K8S Operator,其开源项目地址在https://github.com/pingcap/tidb-operator。在某种意义上,Operator也符合DevOps理念,因为开发人员通过编写代码做了本该是运维团队干的事情。
让我们一起期待Operator时代的到来吧!
参考链接:
-
Run a Replicated Stateful Application,https://kubernetes.io/docs/tasks/run-application/run-replicated-stateful-application/
-
Containerizing Stateful Applications,https://dzone.com/articles/containerizing-stateful-applications
-
The sad state of stateful Pods in Kubernetes, https://elastisys.com/2018/09/18/sad-state-stateful-pods-kubernetes/
-
刘超,微服务化之无状态化与容器化,https://myopsblog.wordpress.com/2017/02/06/why-databases-is-not-for-containers/
感谢您的阅读,欢迎关注我的微信公众号:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号