
OO-第三单元总结
JML语言的理论基础与应用工具链
-
JML(Java Modeling Language)是用于对Java程序进行规格化设计的一种表示语言,是一种行为接口规格语言。用法主要有开展规格化设计,或针对已有的代码书写规格以提高代码的可维护性。在本单元的作业中,主要用到的有
• /public normal_behavior 用来表达方法在正常情况下应该做出的操作
• /public exceptional_behavior 用来表达方法在异常情况下的操作
• /signals 用来表达抛出的异常
• /requires 用来表达本方法满足的前置条件
• /ensures 用来表达本方法的后置条件
• /old 用来表示本方法未经改变时的值
• /result 用来表示本方法返回的正确结果
• /invariant 用来表达在所有可见状态下都必须满足的特性
• /assignable 用来表示方法会改变哪些变量 应用工具链 - 应用工具链
部署SMT Slover验证及其结果
略。安装出现问题
部署JMLUnitNG
在本步骤中由于直接使用课程的代码会出现JML判定错误的情况,所以自己写了简单的代码用于验证正确性。使用的代码如下:
public class Demo1{
/*@
@ public normal_behavior
@ requires a>0 && b>0;
@ ensures \result == a+b;
*/
public static int add (int a,int b){
return a+b;
}
}
其中没有处理溢出问题。
然后按照讨论区的步骤(感谢讨论区各位大佬),运行如下指令
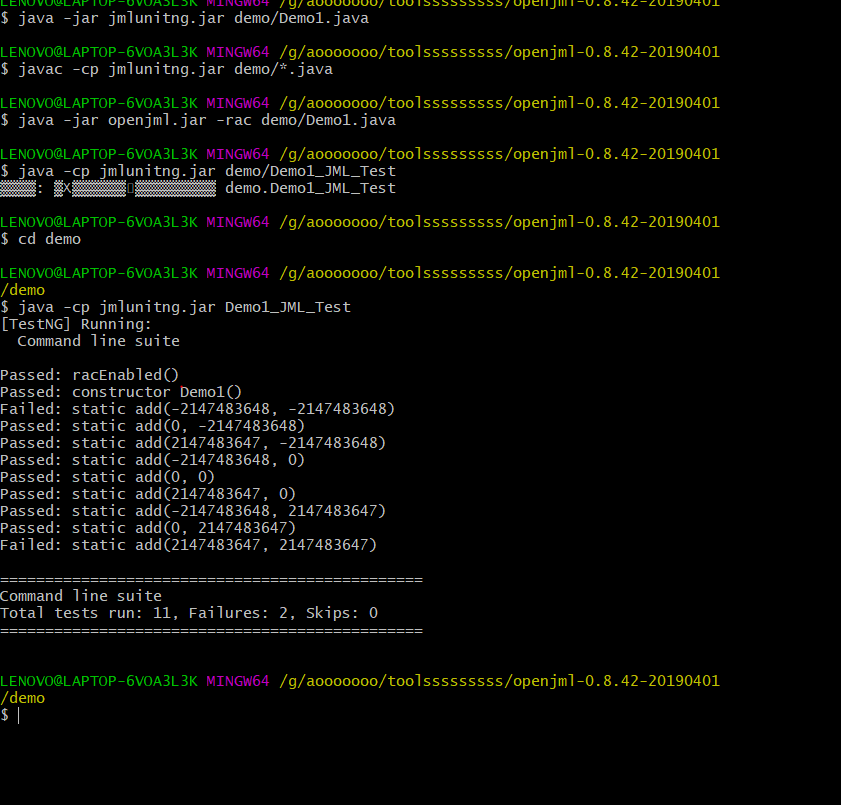
这里需要注意将需要进行测试的代码及openjml,jmlunitng的jar包放在同一个文件夹下,否则会出现无法找到方法的错误。可以看到有两个是失败的,原因是没有处理加法的溢出问题。
总的来说我认为这个方法验证起来没有JUnit方便。因为是自动生成的测试样例,可能有许多复杂代码的边界条件没有被考虑到,而且使用JUnit也能够使我们在编写代码时思考各种边界情况,通过构造断言来判断自己代码的正确性,这种方法的局限性是显然的。并且在Idea中并没有支持jmlunitng,使用起来较为复杂。
本单元代码架构分析
1. 第九次作业
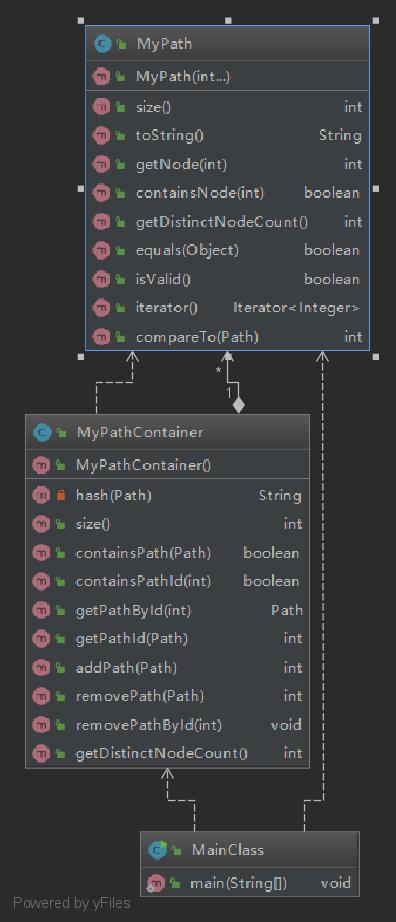
类图如下
复杂度分析如下
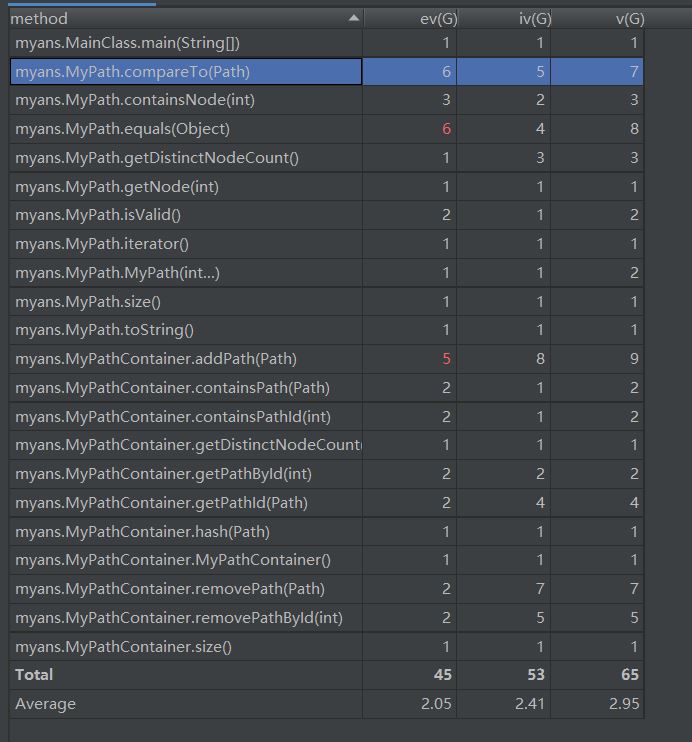
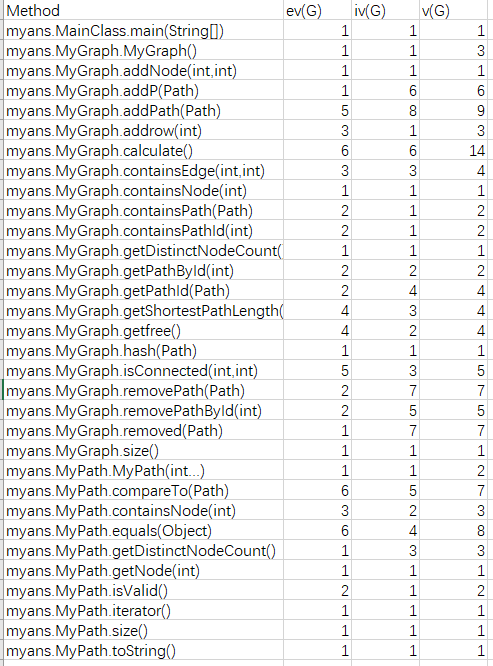
本次作业就是按照JML进行书写,申请了三个HashMap,plist,pidlist,和dot。plist中使用路径的Id作为key,用来存储路径;pidlist使用的是path转为字符串作为Key,用来存储路径对应的Id;dot用结点Id作为key,用来存储点的个数。其中为了减少查找不同点的复杂度,每次addPath的时候都会进行点集合(dot)的增加,每次remove时也会对dot进行修改,使查找不同点方法的复杂度降为O(1)。
2. 第十次作业
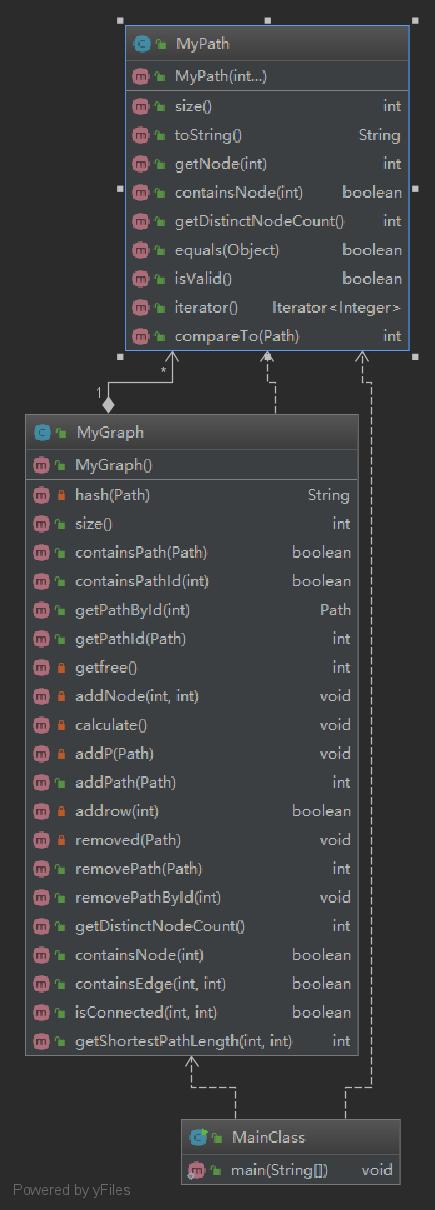
类图如下
复杂度分析如下
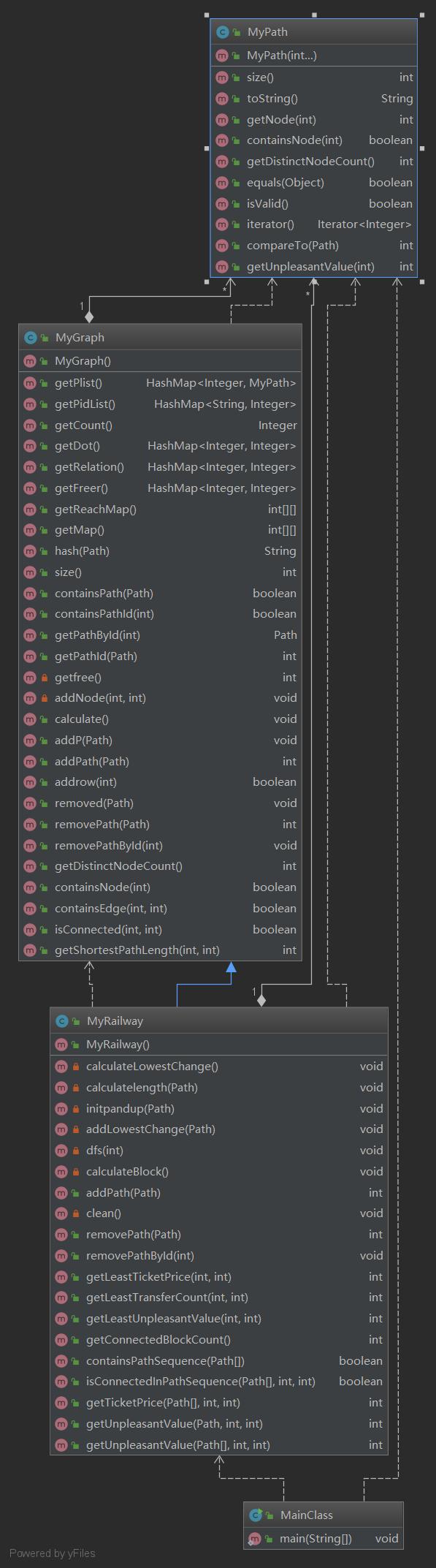
本次作业本来是应该使用继承的,但是我当时将想要继承的上一次的PathContainer中的属性修改为public或protected时checkstyle会报错,于是就选择了将上次的代码复制粘贴到本次的graph中。当然这种方法是错误的,我在后面一周由于代码量变多了再复制粘贴会超过500行...还好寻找到了正确的继承方法。本次的graph类中,由于点的个数是固定的,所以使用了一个120*120的静态数组。但是想要这样使用就需要实现一个点与数组下标的对应关系。所以本次作业中比上次多了两个hashmap:relation和freer,relation中使用结点Id作为key,用来存储对应的数组下标;freer中使用数组下表作为key,用来存储对应的结点Id。还新增了reachmap和map两个120*120的静态数组,分别用来存储可达矩阵和最短路径。同样,本次通过改写addPath和pathRemove,在每次增减路径时都会将两个静态数组重新进行计算,这样能够将复杂度分在出现次数较少的路径增减指令中(总共为20),使得整体能够快一些。在计算最短路时我使用的是DFS,在针对没有权重的图复杂度还是可以接受的。
3. 第十一次作业
类图如下
复杂度分析如下
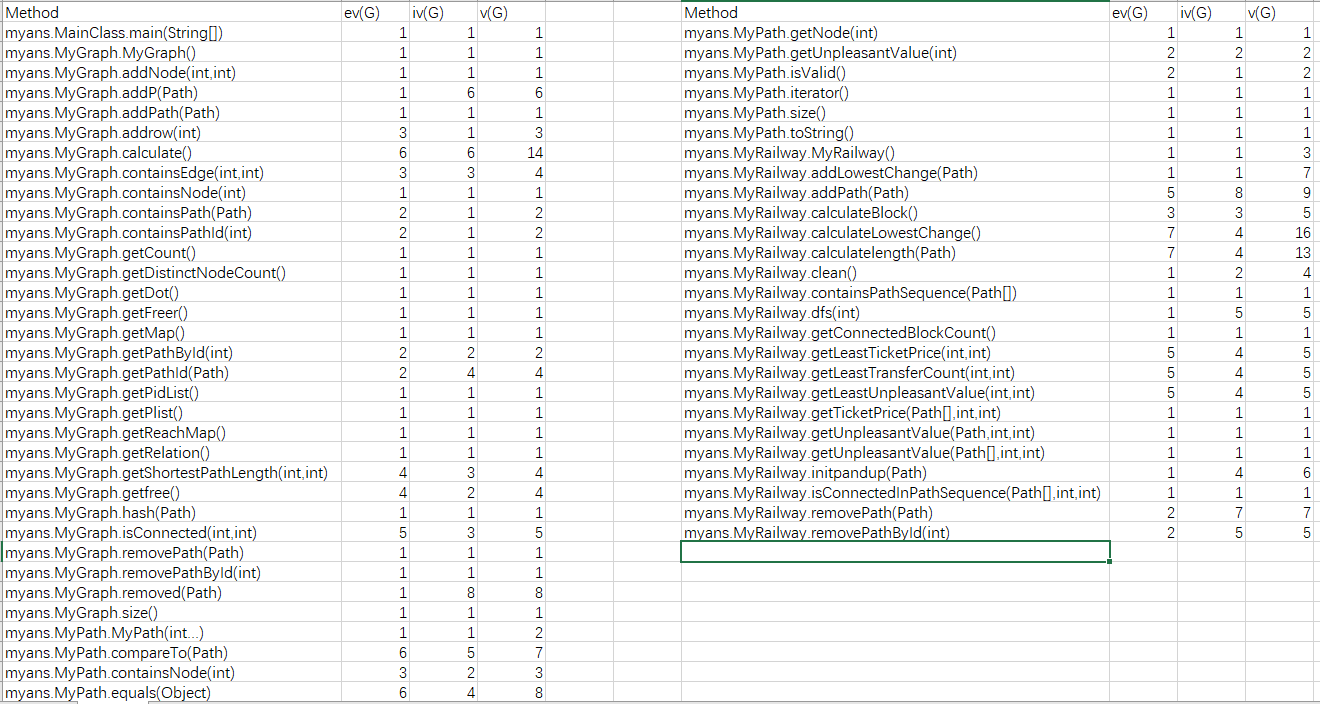
本次作业终于找到了继承的正确方法。父类的所有属性设置为private,子类中也同样设置这些属性,但是在构造时将这个属性赋值为super.*,这样能够使得子类同父类用的是同一个对象,这个对象如果在子类中发生变化,父类中的这个变量同样会发生变化,在父类中发生变化也是如此。由于使用了继承,本次的代码写起来较上次舒适了不少,本次作业总体上使用了不拆点的做法,因为我认为使用不拆点能够继续使用原来的架构,即将所有点映射到大小为120*120的二维数组中,能够较为便捷的计算。在上次的基础上新增了用来存储最低票价,最少换乘,最低不满意度的二维数组。每次add时重新计算这三个矩阵。但是由于算法的问题,每次remove时需要将所有路径重新添加,并计算每一条,这样能够直接将换乘的代价加入,较为简便。但是这样写也就牺牲了增加和删除路径时的不满意度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号