Kaldi搭建语音识别系统—语言模型
在上几篇文章我们已经介绍了数据处理、特征提取及声学单元处理,本节我们要介绍语音识别系统中关键的语言模型训练。关于语音识别系统整体流程,我们本应该在第一篇文章就该拿出来,小编最近日夜颠倒,时差有点乱,逻辑混乱,语音识别系统流程图现在给大家奉上:
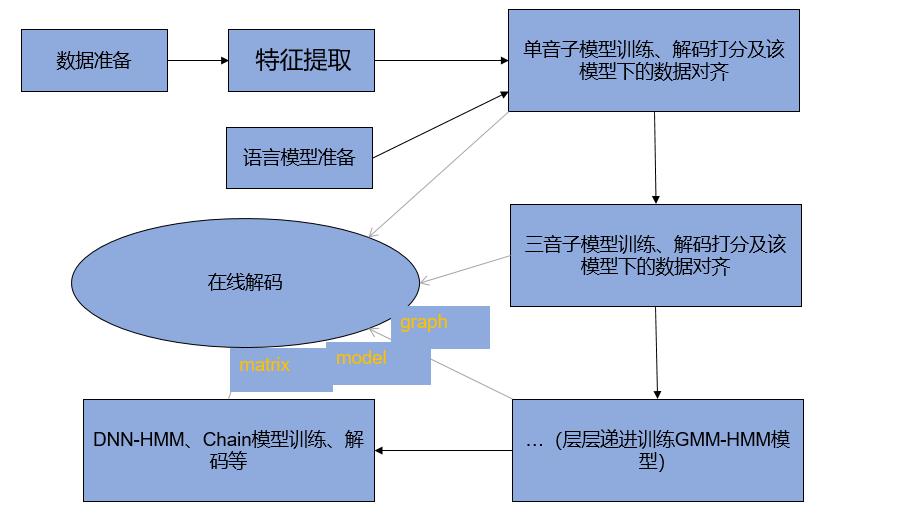
语言模型训练
声学单元建模转换L.fst
在讲解语言模型训练之前,我们弥补上一节声学单元一小段代码,在语音识别系统中,所有的数据处理最终要生成一个称作WFST(加权有限状态转换器)的解码器,而这个WFST本质是一个HCLG静态网络,由H.fst、C.fst、L.fst及G.fst组成,其中声学单元建模要通过utils/prepare_lang.sh装换为L.fst,代码如下:
#3.词典文件转化L.fst
utils/prepare_lang.sh --position-dependent-phones false data/local/dict \
"<SPOKEN_NOISE>" data/local/lang data/lang || exit 1;
语言模型
在该项目实践中,我们使用的n元语法模型,即Ngram,其中n值为3。在kaldi中要使用该工具,需要在kaldi/tools下安装srilm工具包,由于该工具不太好下载,有需要的小伙伴可以联系我。该工具安装前需要安装lib库——liblbfgs,该库也是小编手工下载。有需要的同样关注我的公众号"每日猿码",留言给小编。

下载好liblbfgs和srilm.zip安装包后,可以在tools下运行
tools/install_srilm.sh
安装完,就可以使用ngram工具,我们主要使用ngram-count工具生成arpa语言模型文件。
代码如下:
#!/usr/bin/env bash
# To be run from one directory above this script.
source ./path.sh
#set -x
text=data/local/train/text
lexicon=data/local/dict/lexicon.txt
lm_dir=data/local/lm
mkdir -p $lm_dir
order=3
# ngram 语言模型训练
cat $text | cut -d" " -f2- > $lm_dir/corpus.txt
ngram-count -order $order -write-vocab $lm_dir/vocabs.txt -wbdiscount -text $lm_dir/corpus.txt -lm $lm_dir/aishell-1.${order}gram || exit 1;
echo "$0: ngram train succeeded"
# 转换为G.fst
lang_lm=data/lang
arpa2fst --disambig-symbol=#0 --read-symbol-table=$lang_lm/words.txt $lm_dir/aishell-1.${order}gram $lang_lm/G.fst
fstisstochastic $lang_lm/G.fst
echo "$0: G.fst generated succeeded! "
exit 0;
关于ngram-count工具的使用,此处附上一个链接,关于ngram-count的参数讲解
https://blog.csdn.net/GavinLiu1990/article/details/81363936
本节语言模型的代码实践到此结束,欢迎有兴趣的小伙伴私信我,一起研究kaldi呀~

未经作者允许,请勿私自转载用于商业用途

 浙公网安备 33010602011771号
浙公网安备 33010602011771号