爱学习项目梳理
1. 项目背景
爱学习项目是为央视网搭建的提供稿件、视频、音频等各类资源的存储及检索系统。
2. 基本功能
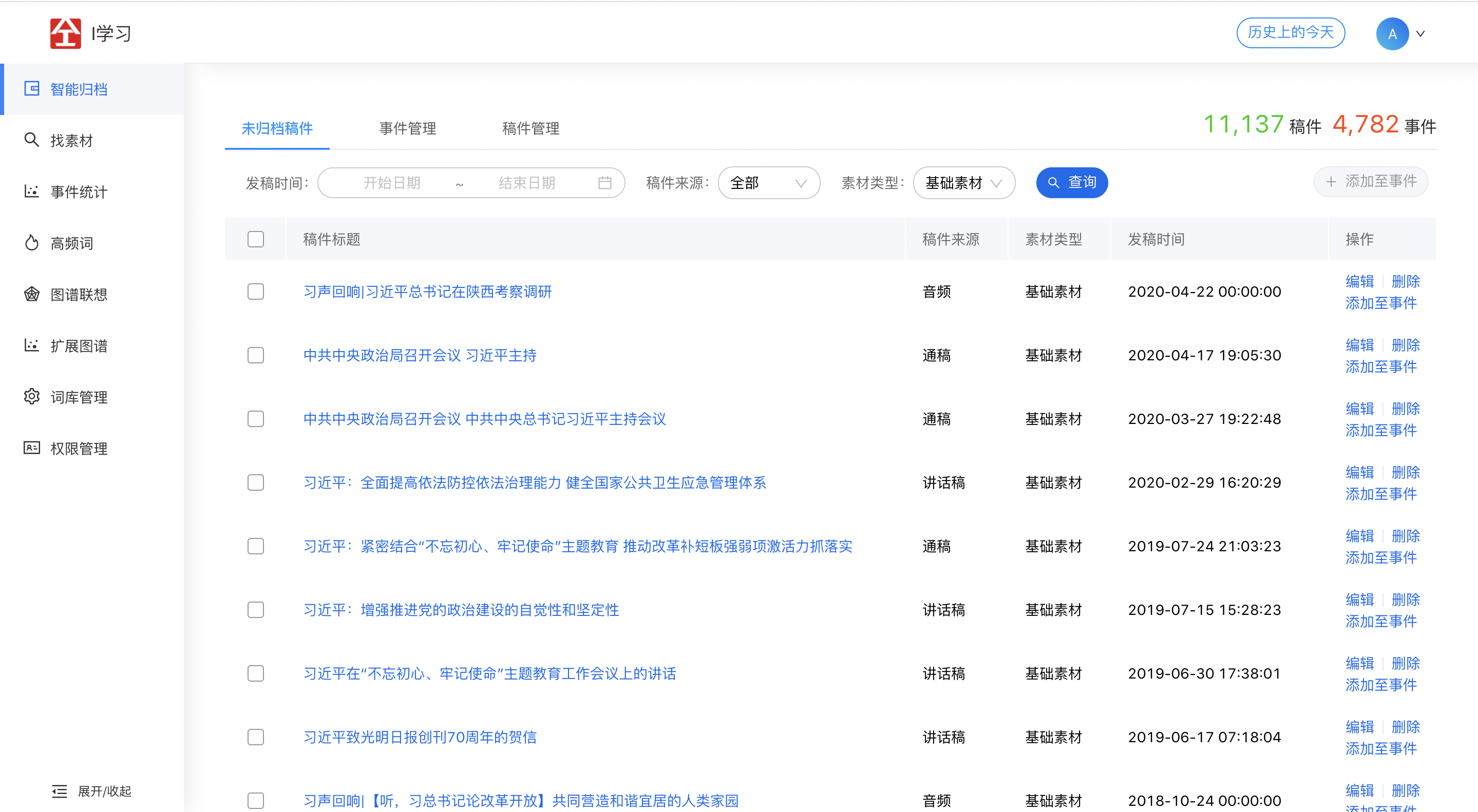
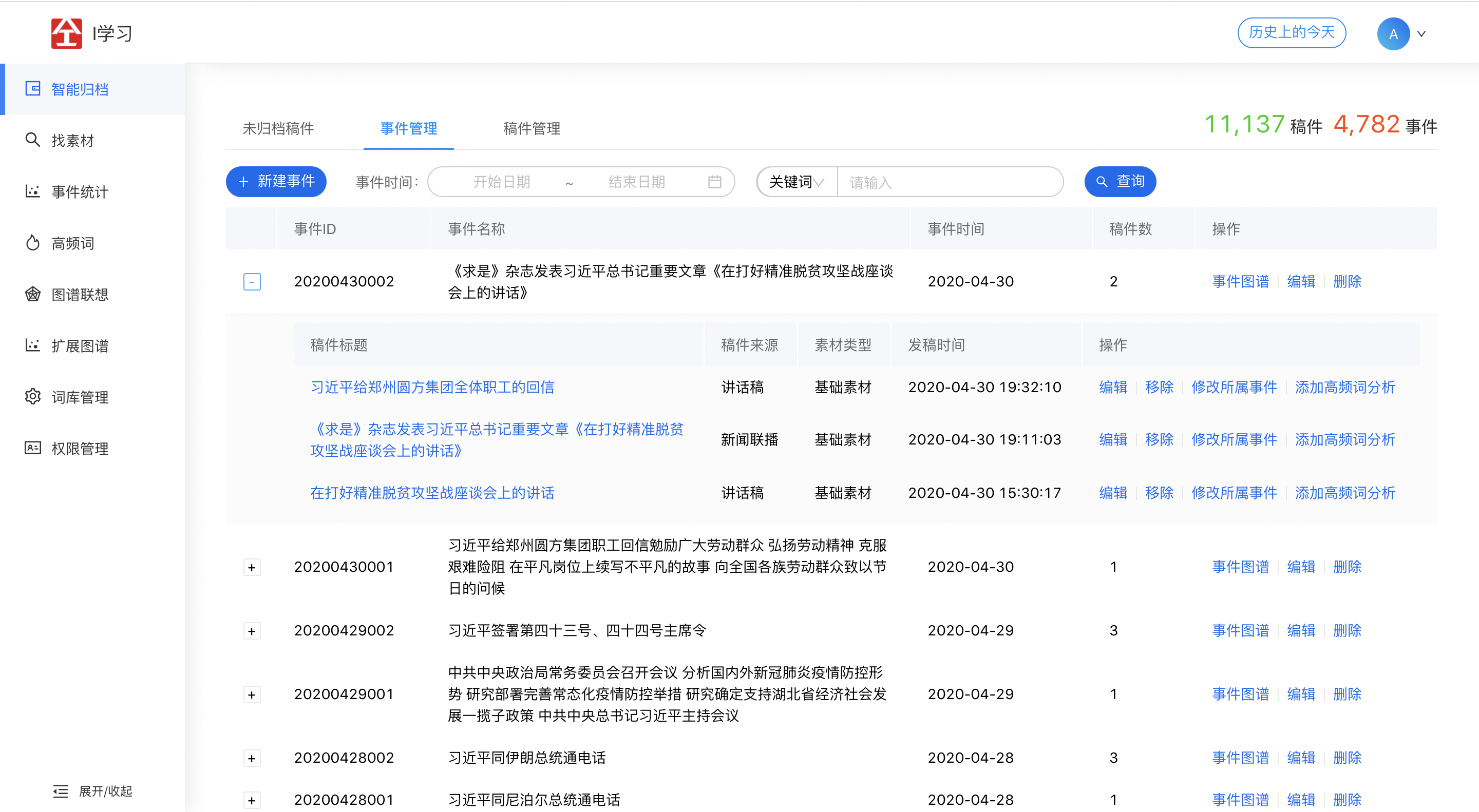
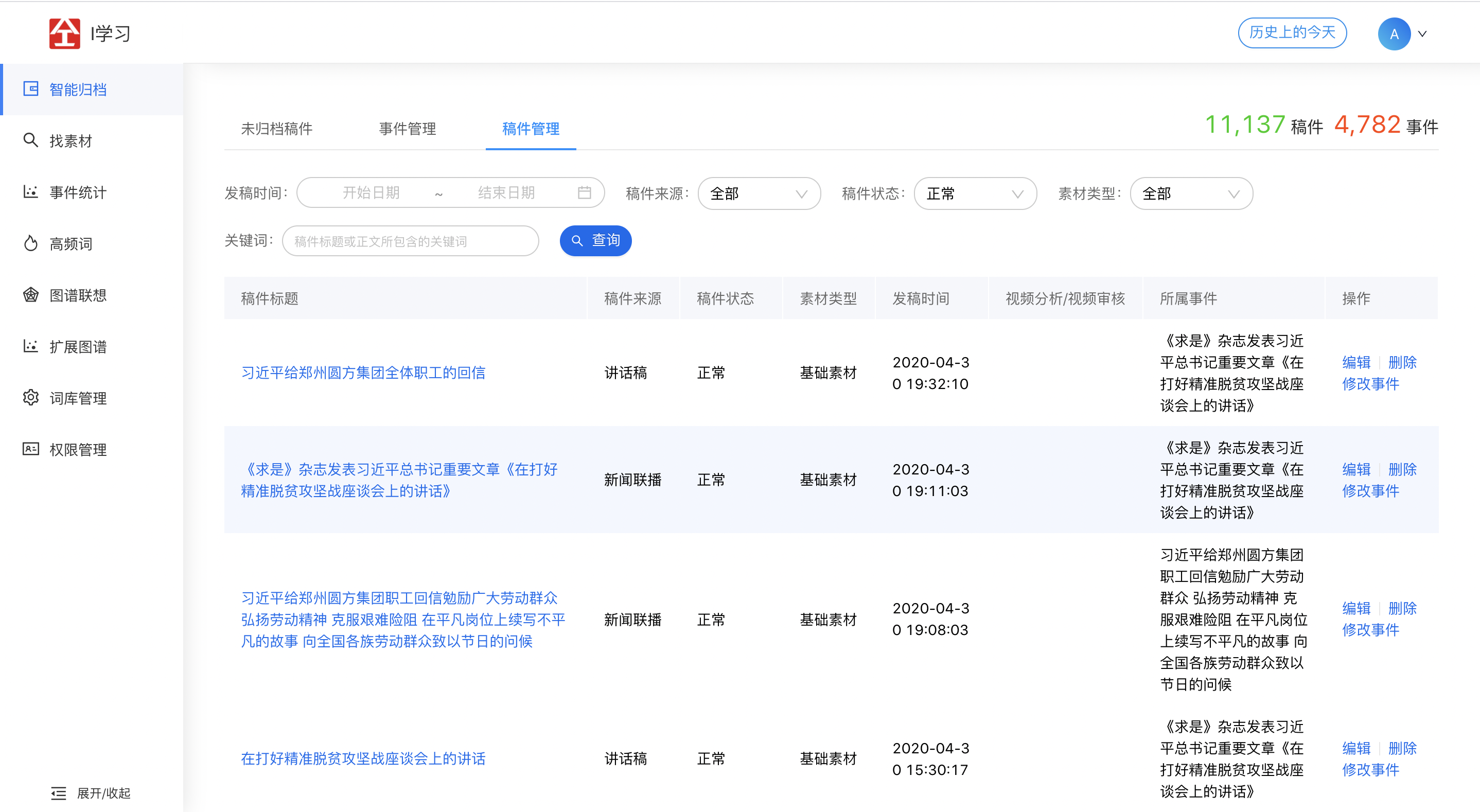
2.1 智能归档
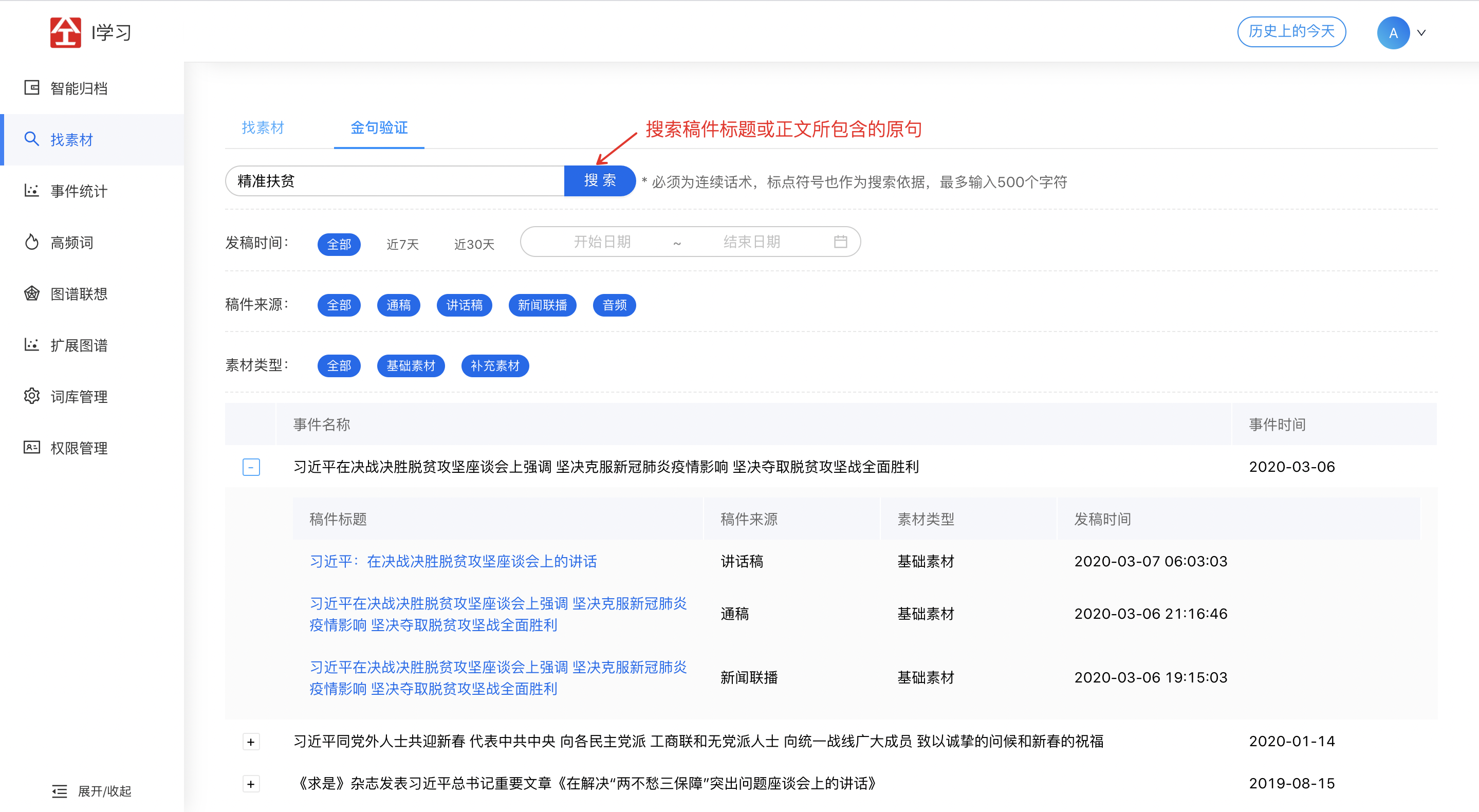
2.2 找素材

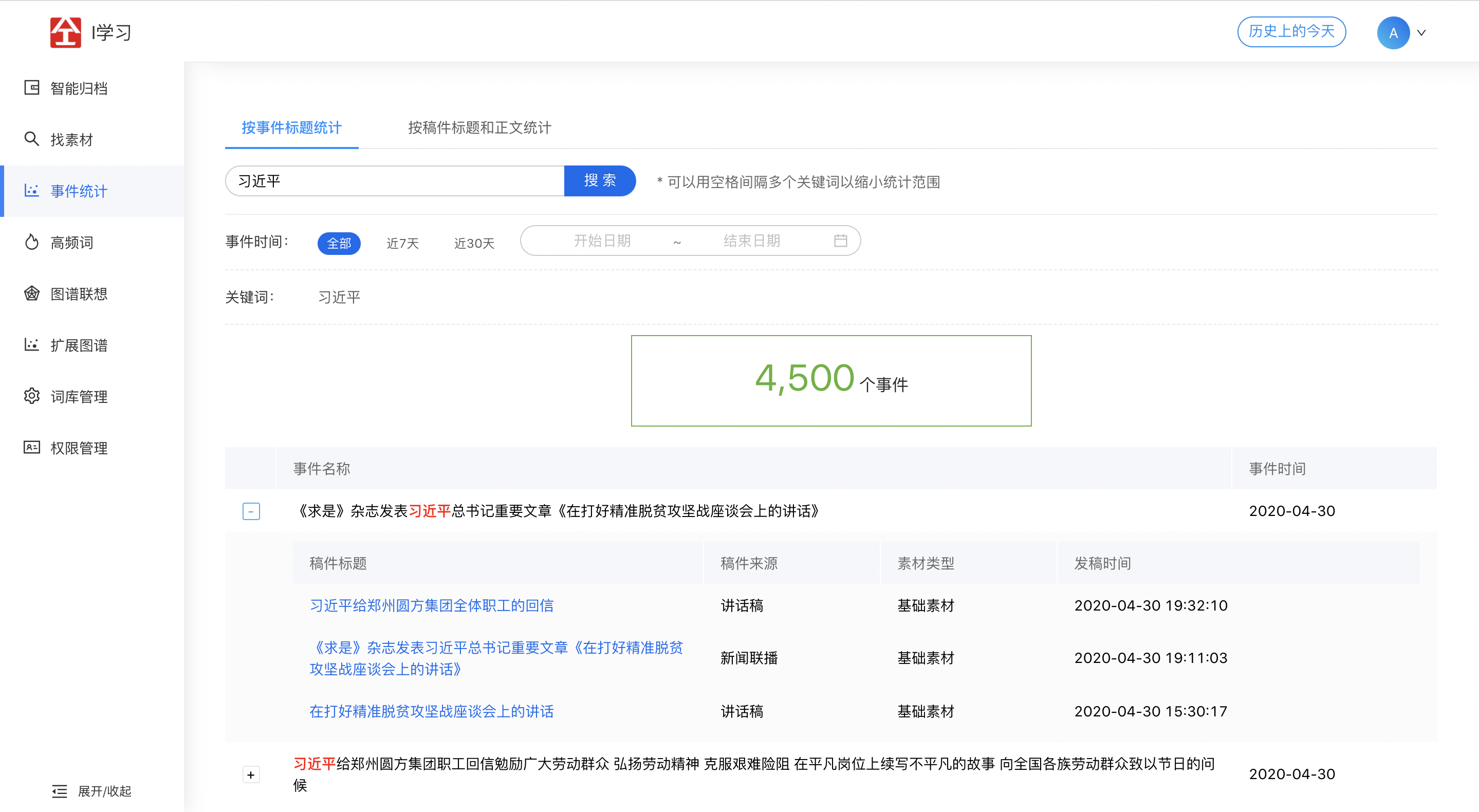
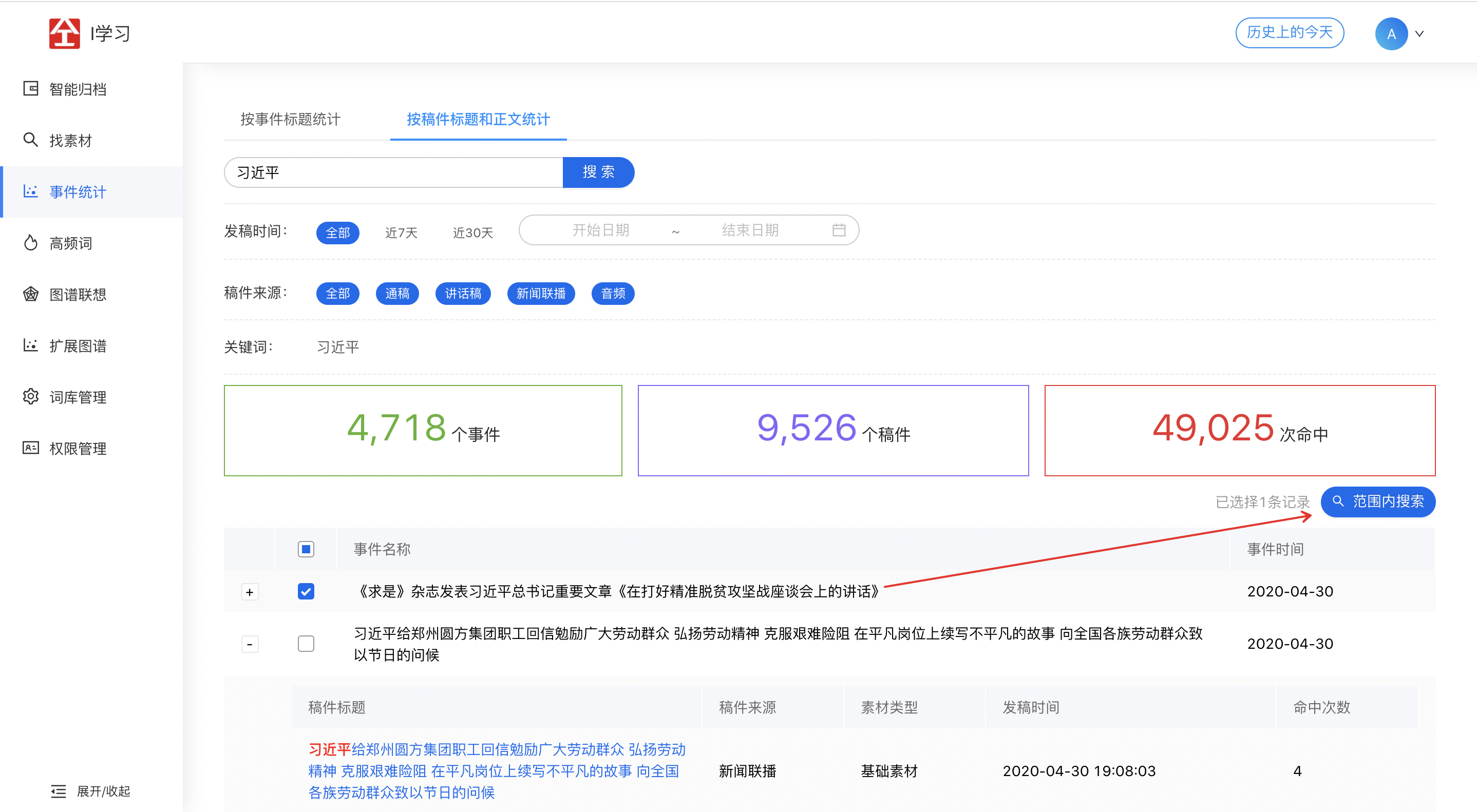
2.3 事件统计
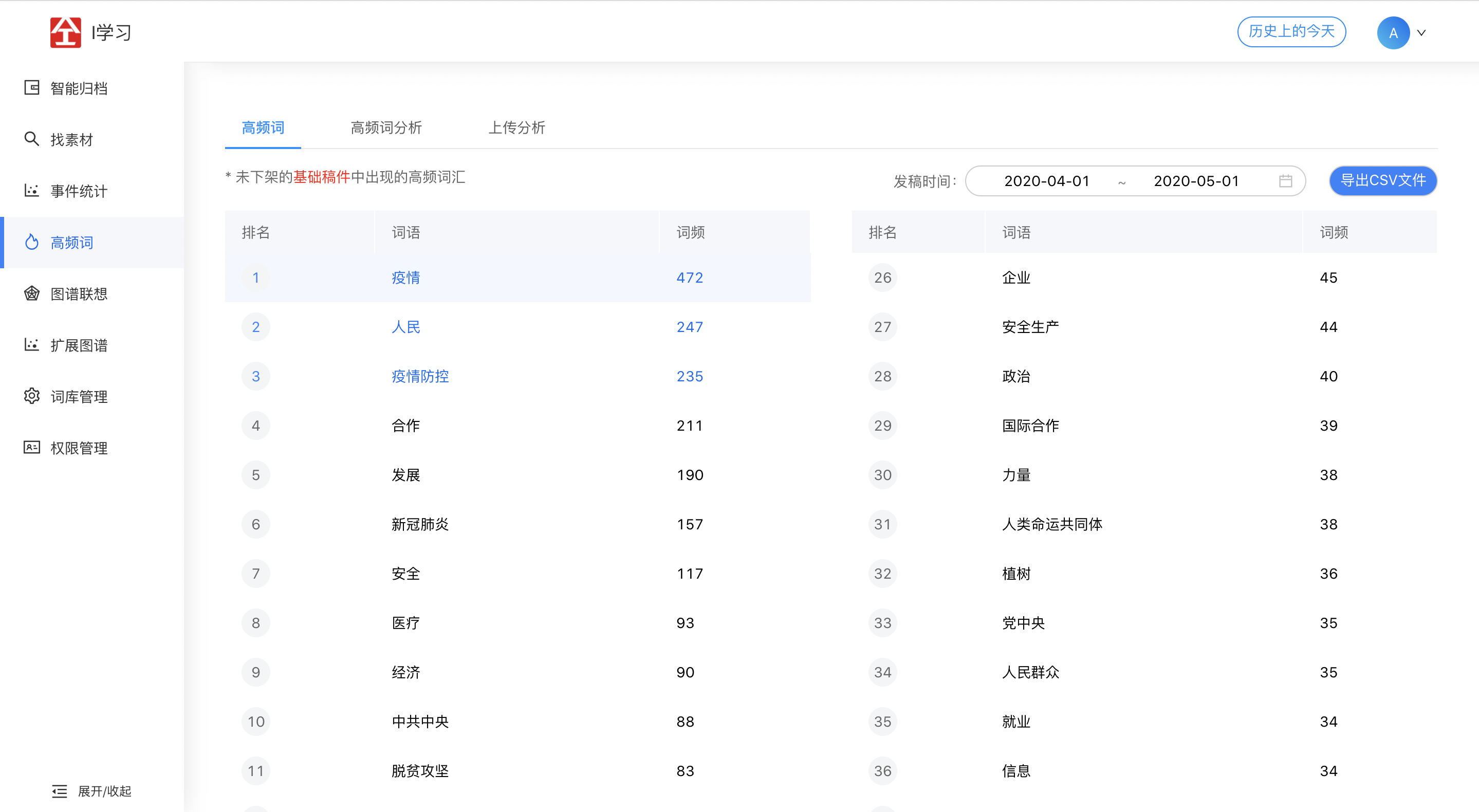
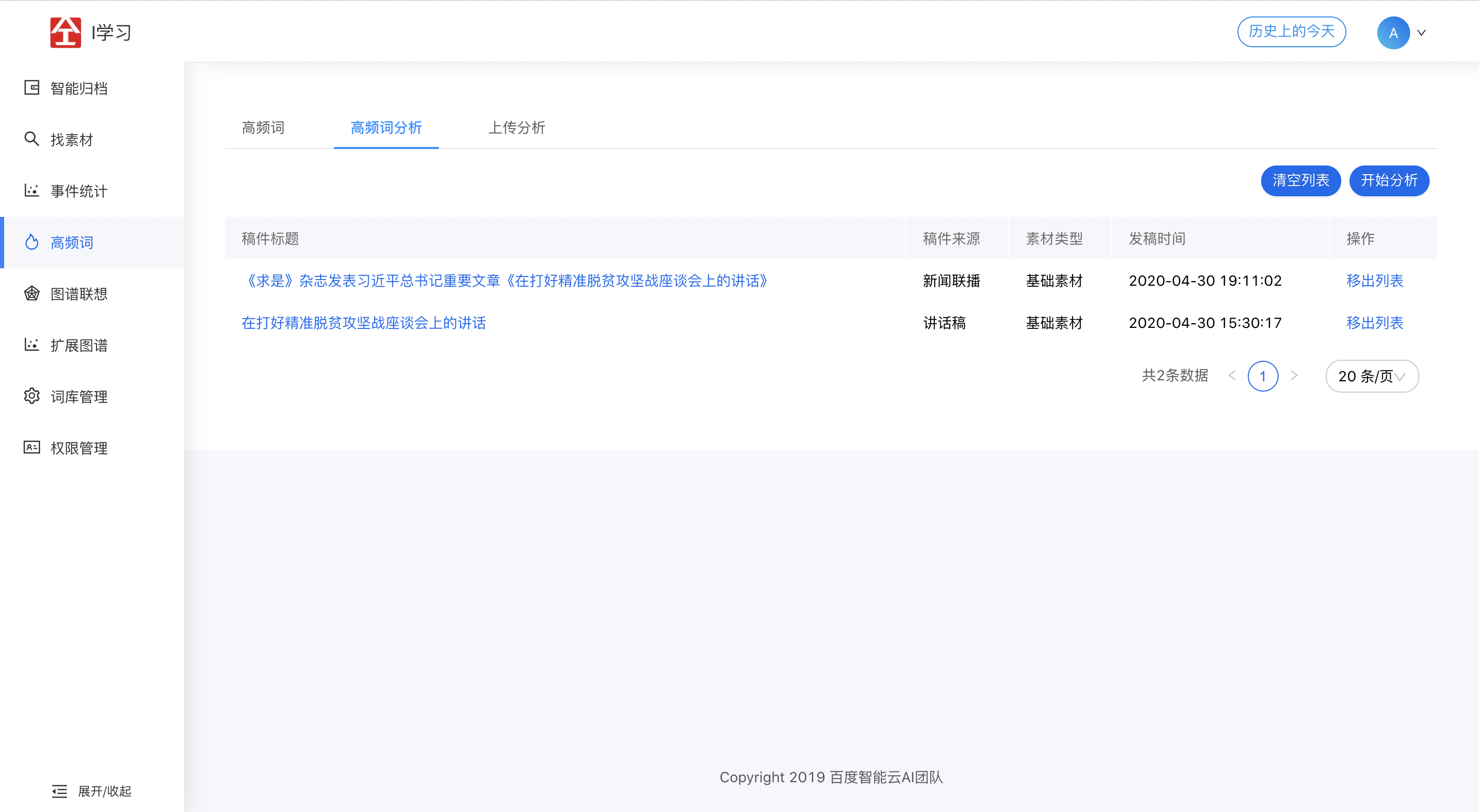
2.4 高频词
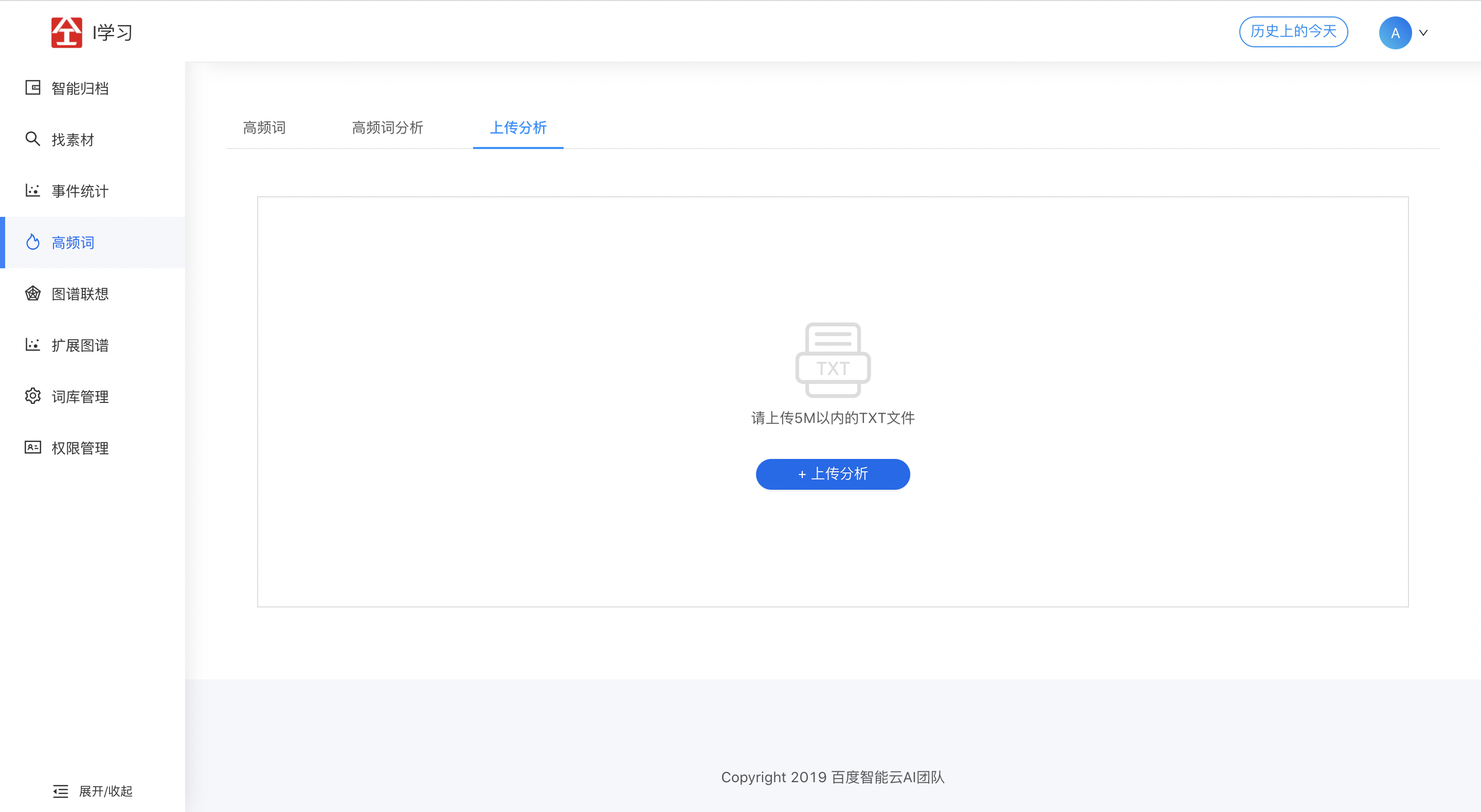
2.5 图谱联想
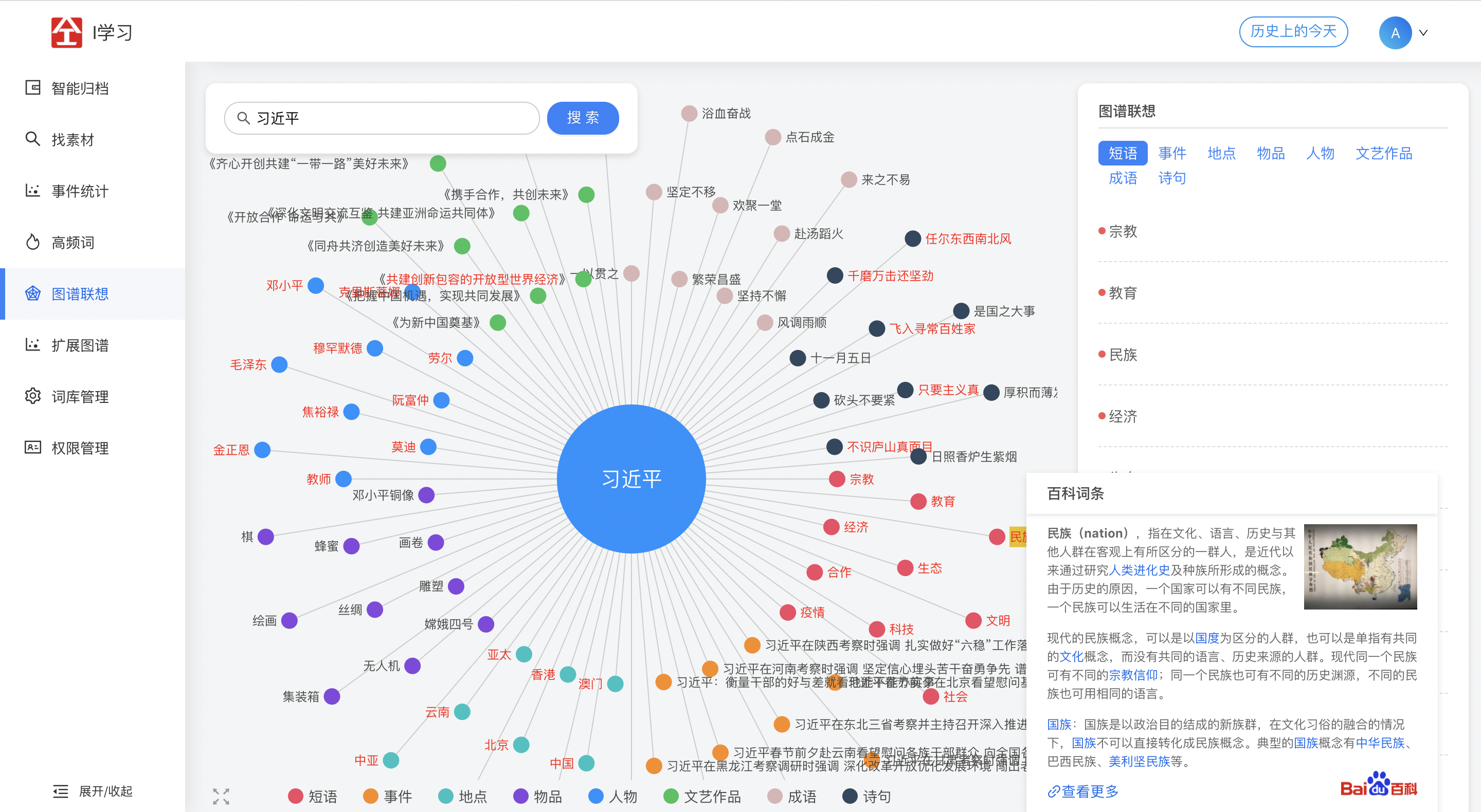
2.6 扩展图谱
2.7 词库管理
2.8 权限管理
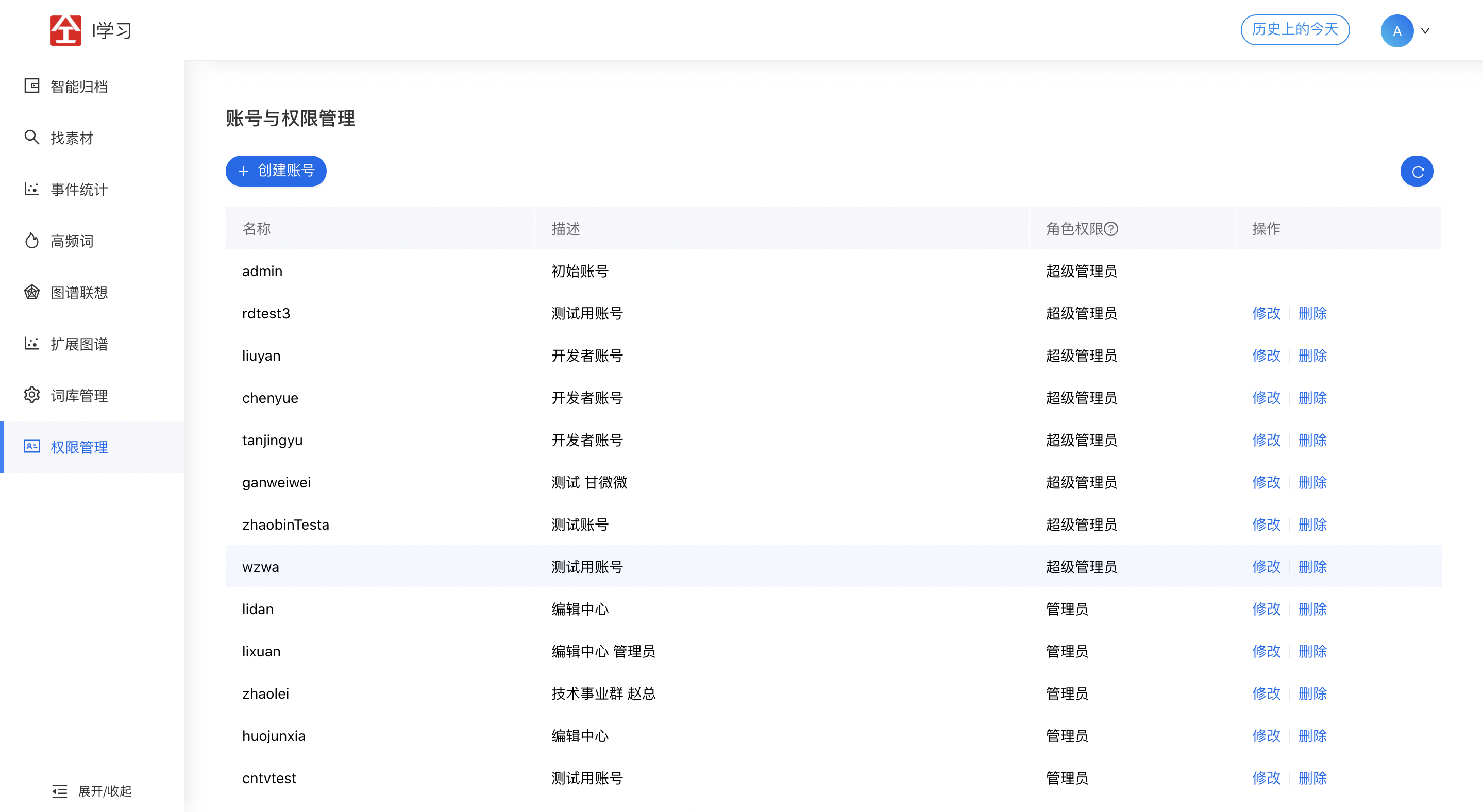
3. 系统架构与关键模块
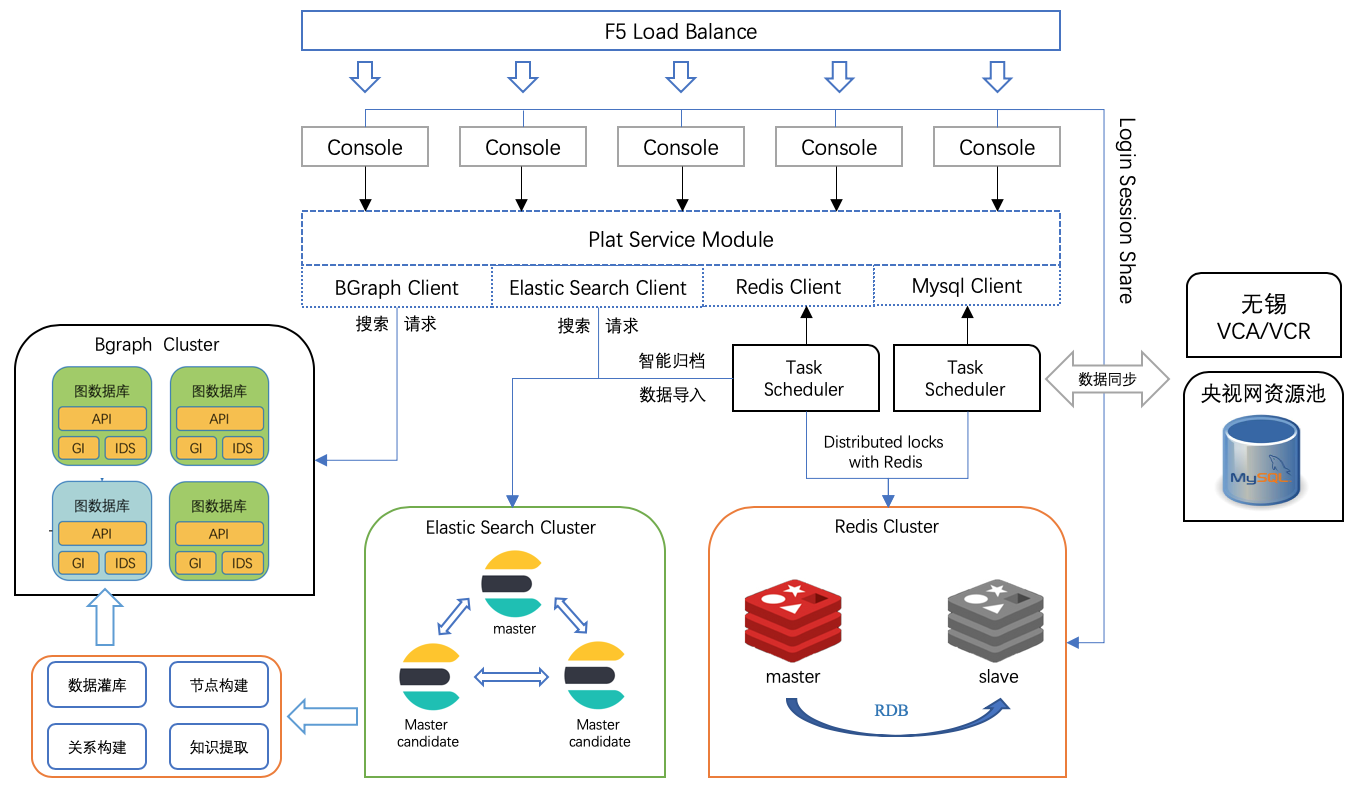
系统架构中,主要的开发内容是在搜索服务的搭建和数据调度服务的开发,其他周边组件为核心服务提供支持。
- F5 LoadBalance:用作load负载均衡;
- Console:业务前端;
- Plat Service Module:公共查询模块,非实例;
- Task Scheduler:任务调度实例,调度数据入库、智能归档、VCA与VCR服务处理;
- Redis Cluster:提供缓存、分布式锁服务;
- Elastic Search Cluster:提供对稿件、事件、账户等数据的持久化与搜索服务;
- Bgraph Cluster:提供图数据库的数据搜索与持久化;
- 央视网资源池:央视网资源接口(暂时是直接暴露的MySQL数据库和表),可以主动拉取央视网的资源数据;
- VCA/VCR:提供视频分析与视频审核服务;
3.1 高可用问题
| 服务 | 节点数 | 说明 |
|---|---|---|
| Console | 3 | 提供前端服务,无状态,通过F5进行分流,只要有一个节点存活即可服务 |
| ElasticSearch | 3 | 提供存储搜索服务,具备自行选主的能力,通过一致性算法,确保数据的最终一致性。至少存活两个节点可提供写入服务,至少存活一个节点可提供搜索服务 |
| Bgraph | 3 | 提供图谱数据的搜索与写入服务,数据可以确保一致性(写更新有延迟),除非所以节点全部失效,否则不会丢失数据,或拒绝查询 |
| ERINE模型归档模型 | 2 | 提供智能归档文本相似度比较,模型固化在docker中,只要有一个节点存活即可提供服务,不存在数据丢失问题 |
| NLP切词模型 | 2 | 提供切词服务,服务于ES的倒排索引构建。只要存活一个节点即可服务,不存在数据丢失问题 |
| Scheduler | 2 | 负责定时数据生成,配合Redis分布式锁保证任意时刻只有一个实例在管理任务调度 |
3.2 双机房问题
双机房问题只影响ES的写服务。
如A机房部署2个节点,B机房部署1个节点
如果B机房损坏,仍存在2个节点,大于1/2节点存活,系统可用;
如果A机房损坏,只存在1个节点,小于1/2节点存活,ES集群只可查询,不可写入;
其他如Bgraph、Redis、Console、Task Scheduler由于实例之间互相独立,不存在问题。
4. ES索引结构
4.1 material_storage索引
存储稿件数据。
PUT {host}:{port}/material_storage
{
"settings": {
"index": {
"number_of_shards": 3, // 3分片
"number_of_replicas": 1, // 1副本
"max_result_window": "10000000", // 默认<=10000
"analyze": {
"max_token_count": 50000
},
"similarity": {
"scripted_simple_freq": {
"type": "scripted",
"script": {
"source": "return doc.freq"
}
}
}
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"titleSmart": { // 稿件标题(单字切碎)
"type": "text",
"analyzer": "one_character",
"search_analyzer": "one_character"
},
"titleNLP": { // 稿件标题(NLP切词)
"type": "text",
"analyzer": "acg_ner",
"search_analyzer": "acg_ner"
},
"subTitle": { // 子标题
"type": "text",
"analyzer": "acg_ner",
"search_analyzer": "acg_ner"
},
"repairTitle": { // AI智能归档titleNLP无法匹配时的候补标题
"type": "text",
"analyzer": "acg_ner",
"search_analyzer": "acg_ner"
},
"contentSmart": { // 稿件正文(单字切碎)
"type": "text",
"analyzer": "one_character",
"search_analyzer": "one_character"
},
"contentNLP": { // 稿件正文(NLP切词)
"type": "text",
"analyzer": "acg_ner",
"search_analyzer": "acg_ner",
"similarity": "scripted_simple_freq", // 默认的TF-IDF打分由1.7021474改为词频
"term_vector": "with_positions_offsets" // 持久化term_vector
},
"materialType": { // 稿件来源:WIRE_COPY-通稿、SPEECH-讲话稿、XINWEN_LIANBO-新闻联播、CNR_AUDIO-音频、CMS-CMS录入
"type": "keyword"
},
"materialAdditionalType": { // 素材类型:NORMAL-基础素材、SUPPLEMENT-补充素材
"type": "keyword"
},
"publishTime": { // 发稿时间
"type": "date"
},
"relationEvent": { // 关联的事件信息
"properties": {
"eventId": { // 事件ID
"type": "keyword"
},
"eventName": { // 事件名称
"type": "text",
"index": false
},
"eventTime": { // 事件时间
"type": "date"
}
}
},
"source": { // 稿件来源:央视网
"type": "keyword"
},
"systemSource": { // 稿件来源:央视网、央广网
"type": "keyword"
},
"url": { // 央视网资源池稿件地址
"type": "text",
"index": false
},
"status": { // 稿件状态:ENABLE-正常、DISABLE-下架、DELETE-删除
"type": "keyword"
},
"archiveStatus": { // 归档状态:NONE-未归档、AI-AI归档、PERSON-人工归档
"type": "keyword"
},
"createTime": { // 创建时间
"type": "date"
},
"updateTime": { // 更新时间
"type": "date"
},
"vcaRaw": { // 存储VCA分析结果vcaResponse
"type": "text",
"index": false
},
"vcrRaw": { // 存储VCR分析结果vcrResponse
"type": "text",
"index": false
},
"vcaFace": { // VCA分析提取的人脸信息
"type": "object",
"properties": {
"name": { // 人脸标签
"type": "keyword"
},
"confidence": { // 置信度
"type": "float"
}
}
},
"vcrFace": { // VCR分析提取的人脸信息
"type": "object",
"properties": {
"name": { // 人脸标签
"type": "keyword"
},
"confidence": { // 置信度
"type": "float"
}
}
},
"videoUrl": { // 视频url
"type": "text",
"index": false
},
"audioUrl": { // 音频url
"type": "text",
"index": false
}
}
}
}
4.2 event_storage索引
存储事件数据。
PUT {host}:{port}/event_storage
{
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 1,
"max_result_window": "10000000",
"analyze": {
"max_token_count": 50000
},
"similarity": {
"scripted_simple_freq": {
"type": "scripted",
"script": {
"source": "return doc.freq"
}
}
}
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"createTime": { // 创建时间
"type": "date"
},
"eventDay": { // 事件时间日期
"type": "keyword"
},
"eventIdPrefix": { // 事件时间:20171229
"type": "keyword"
},
"eventIdSeq": { // 事件序号:3(和eventIdPrefix拼接成事件ID:20171229003)
"type": "integer"
},
"eventMonth": { // 事件时间月份
"type": "keyword"
},
"eventNameSmart": { // 事件名称(单字切碎)
"type": "text",
"analyzer": "one_character",
"search_analyzer": "one_character"
},
"eventNameNLP": { // 事件名称(NLP切词)
"type": "text",
"analyzer": "acg_ner",
"search_analyzer": "acg_ner"
},
"eventTime": { // 事件时间
"type": "date"
},
"relationMaterialCount": { // 关联所有稿件数
"type": "integer"
},
"relatedNormalMaterialCount": { // 关联基础素材类型稿件数
"type": "integer"
},
"relationMaterialList": { // 关联稿件
"type": "nested",
"properties": {
"materialId": { // 稿件ID
"type": "keyword"
},
"materialType": { // 稿件来源:WIRE_COPY-通稿、SPEECH-讲话稿、XINWEN_LIANBO-新闻联播、CNR_AUDIO-音频、CMS-CMS录入
"type": "keyword"
},
"materialAdditionalType": { // 素材类型:NORMAL-基础素材、SUPPLEMENT-补充素材
"type": "keyword"
},
"publishTime": { // 发稿时间
"type": "date"
},
"subTitle": { // 子标题
"type": "text",
"analyzer": "acg_ner",
"search_analyzer": "acg_ner"
},
"titleSmart": { // 稿件标题(单字切碎)
"type": "text",
"analyzer": "one_character",
"search_analyzer": "one_character"
},
"titleNLP": { // 稿件标题(NLP切词)
"type": "text",
"analyzer": "acg_ner",
"search_analyzer": "acg_ner"
},
"contentSmart": { // 稿件正文(单字切碎)
"type": "text",
"analyzer": "one_character",
"search_analyzer": "one_character"
},
"contentNLP": { // 稿件正文(NLP切词)
"type": "text",
"analyzer": "acg_ner",
"search_analyzer": "acg_ner",
"similarity": "scripted_simple_freq"
}
}
},
"status": { // 事件状态:ENABLE-启用、DELETE-删除
"type": "keyword"
},
"updateTime": { // 更新时间
"type": "date"
}
}
}
}
4.3 account_storage索引
存储用户数据。
PUT {host}:{port}/account_storage
{
"settings": {
"index": {
"number_of_replicas": 1
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"name": { // 用户名
"type": "keyword"
},
"password": { // 密码
"type": "text",
"index": false
},
"description": { // 描述信息
"type": "text"
},
"role": { // 角色:SUPER_ADMIN、ADMIN、USER、TENANT
"type": "keyword"
},
"status": { // 状态:ENABLED、DISABLED
"type": "keyword"
},
"createTime": { // 创建时间
"type": "date"
},
"updateTime": { // 更新时间
"type": "date"
}
}
}
}
4.4 running_storage索引
每隔1分钟触发一次定时任务,任务从running_storage索引中查出上次拉取央视资源库数据的时间,然后对比当前时间,超过一小时则拉取数据并更新running_storage索引时间戳,否则跳过。
PUT {host}:{port}/running_storage
{
"settings": {
"index": {
"number_of_replicas": 1
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"time": { // 上次拉取央视资源库数据时间
"type": "long"
}
}
}
}
4.5 word_lib_storage索引
存储词频和黑白名单数据。
PUT {host}:{port}/word_lib_storage
{
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 1,
"max_result_window": "10000000"
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"words": { // 词语List
"type": "keyword"
},
"wordFreq": { // 词频(记录30天高频词)
"type": "integer"
},
"type": { // DOCUMENT、PERSON、POSITION、GOODS、EVENT、PHRASE、LITERARY、CENTER、CONSTANT、IDIOM、VERSE、CK
"type": "keyword"
},
"position": { // WHITE、BLACK
"type": "keyword"
},
"updateTime": { // 更新时间
"type": "date"
}
}
}
}
4.6 bad_case_storage索引
用于图谱词库 -> 添加黑名单反馈切词错误信息。
PUT {host}:{port}/bad_case_storage
{
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 1,
"max_result_window": "10000000"
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"words": { // 关键词
"type": "keyword"
},
"materialIds": { // 关键词所在稿件ID
"type": "keyword"
},
"type": { // DOCUMENT、PERSON、POSITION、GOODS、EVENT、PHRASE、LITERARY、CENTER、CONSTANT、IDIOM、VERSE、CK
"type": "keyword"
},
"createTime": { // 创建时间
"type": "date"
}
}
}
}
4.7 system_config索引
存储bgraph_database_name。
PUT {host}:{port}/system_config
{
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 1
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"value": { // bgraph_database_name
"type": "text",
"index": false
}
}
}
}
4.8 cache_material_content_pedia索引
缓存稿件百科词条数据。
PUT {host}:{port}/cache_material_content_pedia
{
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 1
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"termVector": { // json串形式存储词条百科信息
"index": false,
"type": "text"
},
"materialVersion": { // 版本号
"type": "integer"
}
}
}
}
4.9 cart_index_template索引模板
创建账号的同时会创建对应的cart索引,索引字段用于前端数据展示。
PUT {host}:{port}/_template/cart_index_template
{
"index_patterns": [
"cart_*"
],
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 1
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"materialTitle": { // 稿件标题
"index": false,
"type": "text"
},
"publishTime": { // 发稿时间
"index": false,
"type": "date"
},
"materialType": { // 稿件来源:WIRE_COPY-通稿、SPEECH-讲话稿、XINWEN_LIANBO-新闻联播、CNR_AUDIO-音频、CMS-CMS录入
"index": false,
"type": "text"
},
"materialAdditionalType": { // 素材类型:NORMAL-基础素材、SUPPLEMENT-补充素材
"index": false,
"type": "text"
}
}
}
}
4.10 word_analyze_task索引
存储购物车高频词分析结果。
PUT {host}:{port}/word_analyze_task
{
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 1
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"materialCartList": { // json串存储List<MaterialCart> materialCartList
"index": false,
"type": "text"
},
"createTime": { // 创建时间
"index": false,
"type": "date"
},
"name": { // 用户名
"type": "keyword"
},
"updateTime": { // 更新时间
"index": false,
"type": "date"
},
"detail": { // json串形式存储分析结果,包括List<String> words和List<Integer> freq
"index": false,
"type": "text"
},
"status": { // 状态:ENABLED、DELETE
"index": false,
"type": "text"
}
}
}
}
4.11 file_analyze_result索引
存储高频词上传分析结果。
PUT {host}:{port}/file_analyze_result
{
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 1
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"name": { // 用户名
"type": "keyword"
},
"fileName": { // 上传文件名
"type": "keyword"
},
"detail": { // json串形式存储分析结果,包括List<String> words和List<Integer> freq
"index": false,
"type": "text"
}
}
}
}
4.12 vca_vcr_task索引
存储VCA&VCR任务。
PUT {host}:{port}/vca_vcr_task
{
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 1
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"createTime": { // 创建时间
"type": "date"
},
"contentId": { // 稿件ID
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
},
"subTaskType": { // 子任务类型:BOS、VCA、VCR
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
},
"url": { // 视频地址
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
}
}
}
}
5. 搜索策略
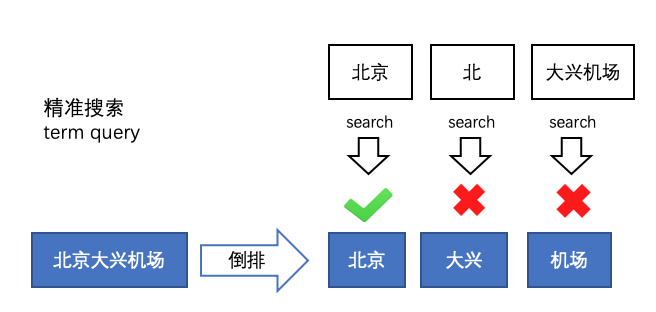
5.1 精准搜索
输入的词不再切分,然后匹配通过切词处理好的稿件。
5.2 模糊搜索
对输入内容进行切词,然后以模糊match的方式进行比对。
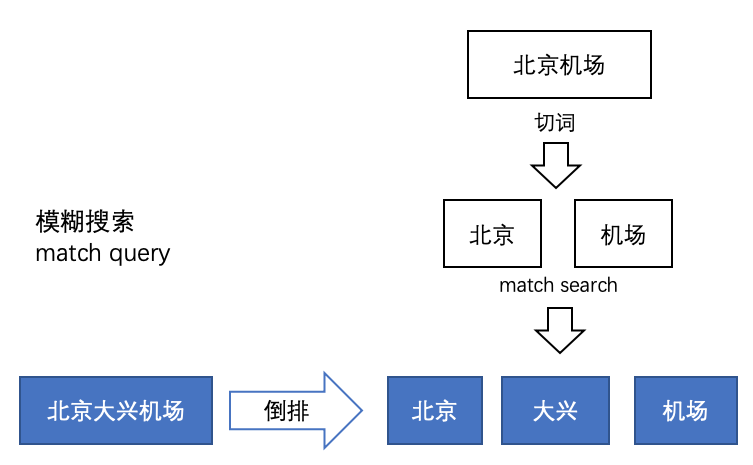
匹配次数可以设置,最少一个,或者按照%来。
5.3 短语搜索
短语搜索和模糊搜索的match方式是一致的,都是对输入内容进行切词后进行match匹配。
但是搜索到的内容必须连续在一起的。
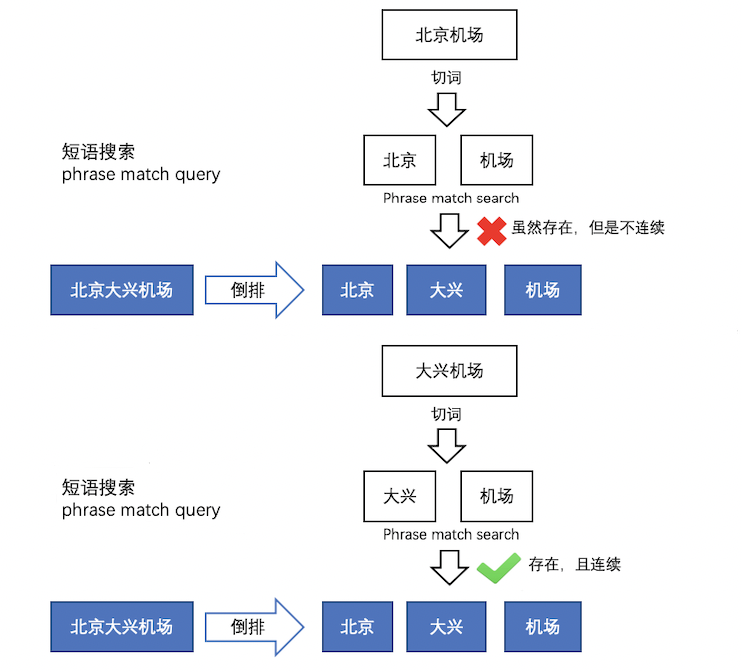
事件管理、稿件管理的搜索就是基于短语搜索,可以满足全局随意匹配的搜索效果。
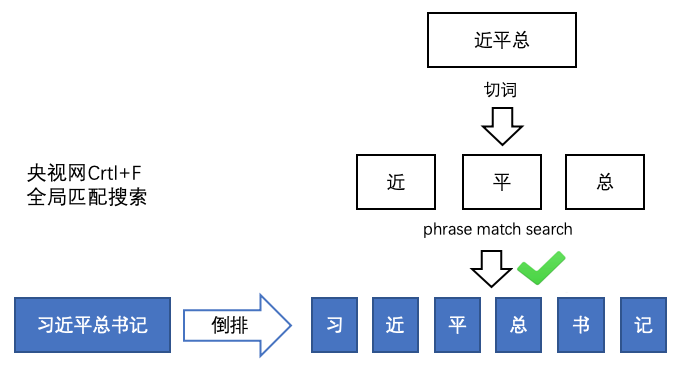
5.4 接口搜索策略汇总
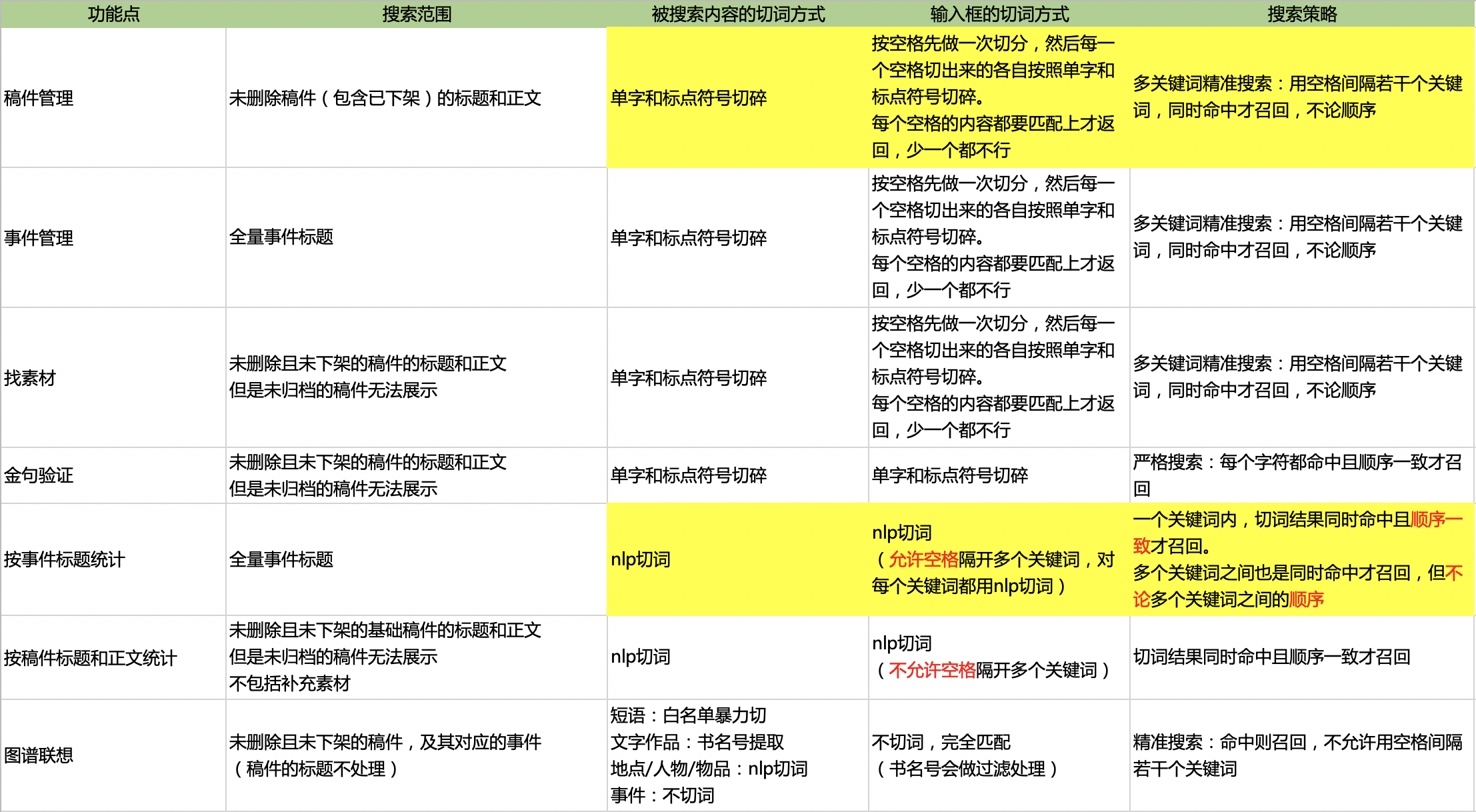
6. 定时任务
定时任务都加锁。
6.1 智能归档
触发时间:早上7点与晚上11点
实现方案:
- 记当前时间为T,一天时间为1D
- 依次处理T-3D到T-2D、T-2D到T-D、T-D到T时间段内的事件与稿件归档
- 以T-3D到T-2D为例,ES查询出T-3D到T-2D时间段内所有的未归档稿件,然后查询出T-3D-D到T-3D+D时间段内所有的事件
- 然后依次遍历所有查询到的稿件和事件,对稿件标题和事件名应用Erine模型可以得到相似度打分,高于阈值0.999994则建立事件与稿件的关联关系
- 如果相似度达不到阈值,接着判断稿件标题与事件名的编辑距离(java-string-similarity)是否小于3,或者稿件标题是否包含事件名,是则建立事件与稿件的关联关系
- 如果5不满足,用acg_smart切词分别获取稿件标题和事件名的切词结果termList1和termList2,然后判断termList1和termList2之间是否为子集关系,是则建立事件与稿件的关联关系
6.2 更新NLP切词
触发时间:凌晨0点
任务内容主要是根据ES中的词库全量生成一个文件,发送至NLP模型所在的docker目录,文件拷贝过去会立即生效,任务大约耗时不超过三分钟。
6.3 刷新稿件库(附加获取百科信息)
触发时间:凌晨1点
任务内容是重新构建稿件内容切词的倒排索引。因为NLP切词更新后,要使新的切词生效,需要取出来再写回去,写回去的同时写百科缓存数据。
在爱学习中,有两处涉及到百科,一处是稿件详情页里面,这一部分由于单个稿件中可能存在大量的百科词条,考虑到用户的查询体验,需要提前离线生成好相应词条的百科数据存入到ES对应的索引中。另外一处是6.6图谱页面上诸如地点、人名、短语、诗词、文艺作品等存在百科信息的节点,这一部分由于数据量比较小,所以没有提前缓存数据,直接发起百科请求即可。
实现方案:
- Scroll查询分批查询出material
- 对一批次中的所有material,依次执行写回去的操作(注意版本号)
- 然后根据doc的rawContent得到Map<String, List<Material.Position>> word2Positions,具体步骤包括
3.1 从ES索引加载黑名单到内存
3.2 调用接口得到contentNLP的NLP切词结果
3.3 根据黑名单、词性、是否包含中文、长度是否>=2过滤切词结果
3.4 遍历切词结果到原文中找到位置即List<Material.Position> - 更新doc的缓存索引cache_material_content_pedia,CopyOnWriteArrayList配合ForkJoinPool+缓存使得任务耗时大大缩短(4.5h -> 1.5h)
public CacheMaterialPedia updatePedia(MaterialDocument doc, Map<String, List<Material.Position>> word2Positions) {
List<Term> termList = new CopyOnWriteArrayList<>();
forkJoinPool.submit(() -> word2Positions.keySet().parallelStream().forEach(word -> {
if (cache.containsKey(word)) {
addTerm(cache.get(word), termList, word, word2Positions);
} else {
try {
PediaAnalyzeResponse response =
CommonUtils.doWithRetry(() -> clientFactory.getVcaClient().pediaAnalyze(word));
if (response.getErrno() == 0 // 说明有对应的百度百科
&& StringUtils.isNotEmpty(response.getAbstractHtml())
&& StringUtils.isNotEmpty(response.getPicUrl())
&& StringUtils.isNotEmpty(response.getUrl())) {
cache.put(word, response);
addTerm(response, termList, word, word2Positions);
}
} catch (Exception ex) {
log.error("Exception occur when get pedia data.");
}
}
})).join();
List<Term> collect = termList.stream().sorted(
Comparator.comparing(k -> Collator.getInstance(Locale.CHINA).getCollationKey(k.getTermText())))
.collect(Collectors.toList());
// 写入cache_material_content_pedia
CacheMaterialPedia pedia = CacheMaterialPedia.builder()
.termVector(JsonUtils.toJsonString(collect))
.materialVersion(doc.getVersion())
.build();
esCommonDaoService.createDoc(Constant.CACHE_MATERIAL_CONTENT_PEDIA, doc.getId(), pedia, true);
return pedia;
}
6.4 刷新事件库
触发时间:凌晨1点
任务内容是重新构建事件内容切词的倒排索引。
实现方案:
// 原索引数据复制到临时索引 同步
reIndex(schemaConfig.getEvent(), Constant.TEMP_EVENT_STORAGE, false);
// 临时索引数据复制到原索引 异步
reIndex(Constant.TEMP_EVENT_STORAGE, schemaConfig.getEvent(), true);
6.5 高频词生成
触发时间:凌晨3点
任务内容是生成高频词统计。
实现方案:
- word_lib_storage索引加载白名单和黑名单
- material索引查询近30天所有稿件的ids
- 根据ids调用MultiTermVectors得到词频
- 写入word_lib_storage索引
6.6 图谱数据生成
触发时间:凌晨3点
任务内容是生成图谱数据,即点和边对应的csv文件,生成后scp至bgraph服务器重刷数据。
在爱学习中,知识图谱的应用是:从事件、稿件中提取出有效知识实体,并挖掘出实体间的关系,进而形成知识图谱,为客户提供可视化的信息展示。
6.6.1 数据格式说明
爱学习会从稿件中分析出图谱所需的数据(顶点与关系),顶点数据和关系数据分别存储在vertex.csv和edge.csv文件中,进而导入数据到bgraph中,以支持系统中的图谱功能。
6.6.1.1 顶点数据
顶点数据存储在vertex.csv文件中,一行一条数据,首行为数据格式说明。
id:ID#name#type#offset
ev-20150831001#***举行仪式欢迎哈萨克斯坦总统纳扎尔巴耶夫访华#EVENT#[16-21,9-13,0-2]
VIDEoG7FSx6TEgNLSFLtGCPJ191003#***在河北调研指导党的群众路线教育实践活动#DOCUMENT#
pe-1e328001dd82ebd738a27521bf26c726#哈尔·辛德贝格#PERSON#
pe-586a40b22be792cd973f2b9113b74f28#弗赖贝加等外方#PERSON#
pe-8fea3d145241247b652f6d43d33dbffd#郭凯#PERSON#
po-a293941a5b00d445507669cefce0b8bc#中国美术学院#POSITION#
每行数据以#分割,可以分割出顶点的4个属性:
ID:顶点Id
name:顶点名称
type:顶点类型,包括:稿件DOCUMENT、人物PERSON、地点POSITION、短语PHRASE、事件EVENT、物品GOODS、文艺作品LITERARY、成语IDIOM和诗句VERSE
offset:具有百科词条的词语位置,没有时为空
6.6.1.2 顶点数据来源
事件和稿件是直接按照系统中的数据生成,即每篇稿件生成一个DOCUMENT顶点,每篇事件生成一个EVENT顶点。
而剩下的其他类型的顶点则需要通过分析稿件的内容获取,基于NLPC算子可以分析出稿件正文中的关键词和词性,如GOODS分类的关键词汽车。
针对每一种顶点,均有黑白名单机制,可以进行自定义配置。
6.6.1.3 关系数据
关系数据存储在edge.csv文件中,一行一条数据,首行为数据格式说明。
_outV:START_ID#_inV:END_ID#label:LABEL#weight
VIDEpnbSwgIe5eswHfwt26rY190114#dy-ad6ee407f5969e0632143d3a261f1b2c#PHRASE#2.0
po-4347dbf8a60c48f3ab673ac8cd00214b#VIDEkoJFklTVWDQtowNXHdoQ180305#POSITION#5
dy-c17b6f8c6608ddcc0a27f89eddb78362#VIDEqEbfcob96KqCTnHjIc4t180201#PHRASE#1.0
dy-9d219e9be9f6f7086faf4a0316702dbe#VIDEzYJuPouAa6VT80ThjJa8180612#PHRASE#2.0
ARTI1504507487330585#dy-59a5844ccc64964b1d1dc49364faa312#PHRASE#3.0
dy-5b9f3fef9e909ab125de6835bd9b9984#VIDE1416309298496395#PHRASE#3.0
dy-e6363d10bb56aa703a3b43585ad69b3a#ARTI1463569857782101#PHRASE#3.0
每行数据以#分割,可以分割出关系的4个属性:
_outV:START_ID关系的开始顶点ID
_inV:END_ID关系的结束顶点ID
label:LABEL关系标签,包括:人物PERSON、地点POSITION、短语PHRASE、事件EVENT、物品GOODS、文艺作品LITERARY、成语IDIOM和诗句VERSE
weight:关系权重
6.6.1.4 关系数据来源
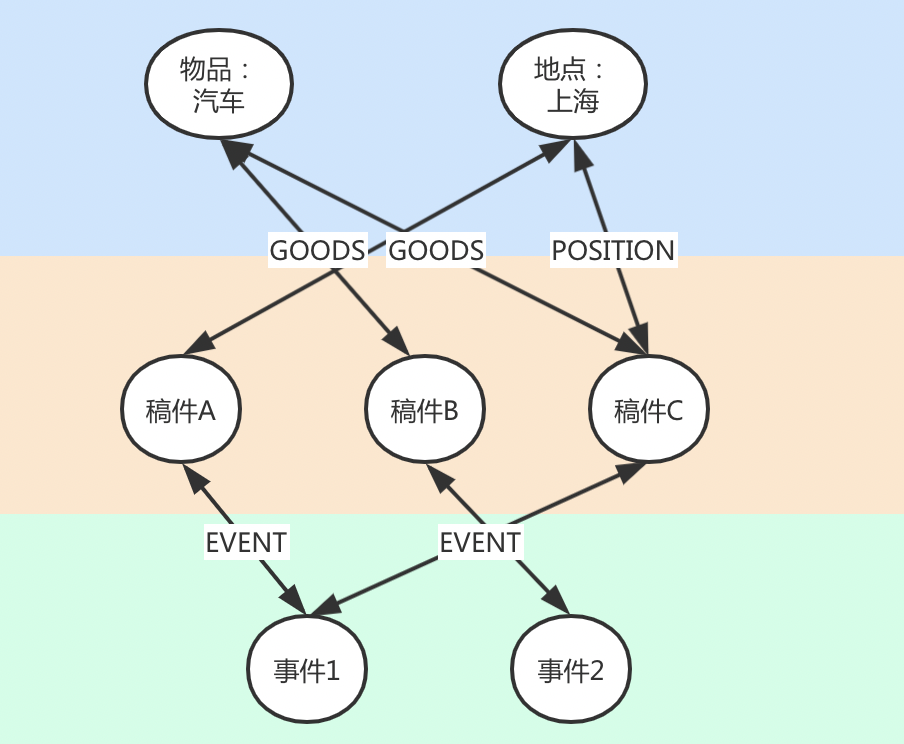
从图中可以看出,图谱中边可以分为两类
1. 事件与稿件关系:即通过事件绑定的稿件关系获得
2. 其他分类与稿件关系:即通过分析稿件正文获取到的其他分类的顶点
所以在图谱中边是围绕着稿件类型的顶点进行的,边数据包含开始与结束两个顶点,边类型(除DOCUMENT以外的其他顶点类型)和边权重(在某稿件中出现的次数)。
6.6.2 图谱构建流程
6.6.2.1 流程概要
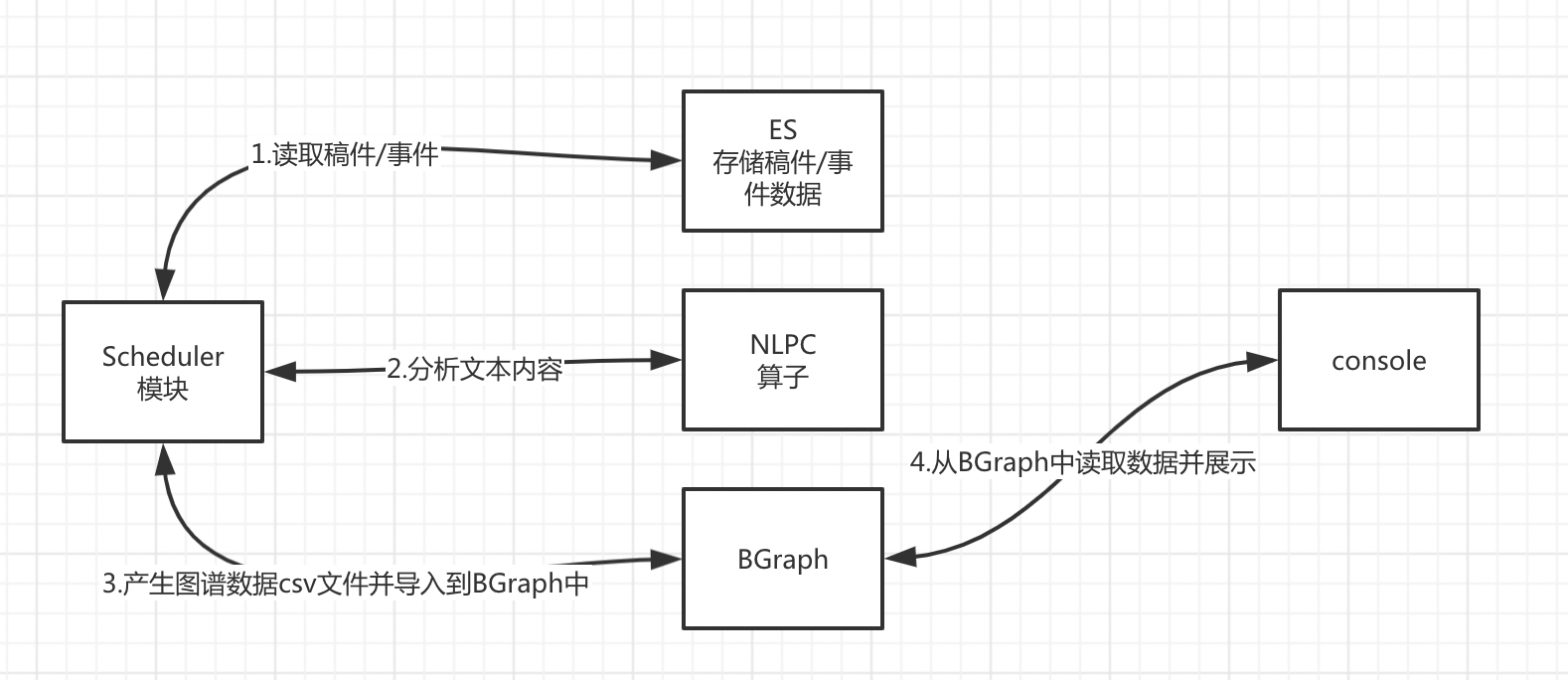
6.6.2.2 流程细节
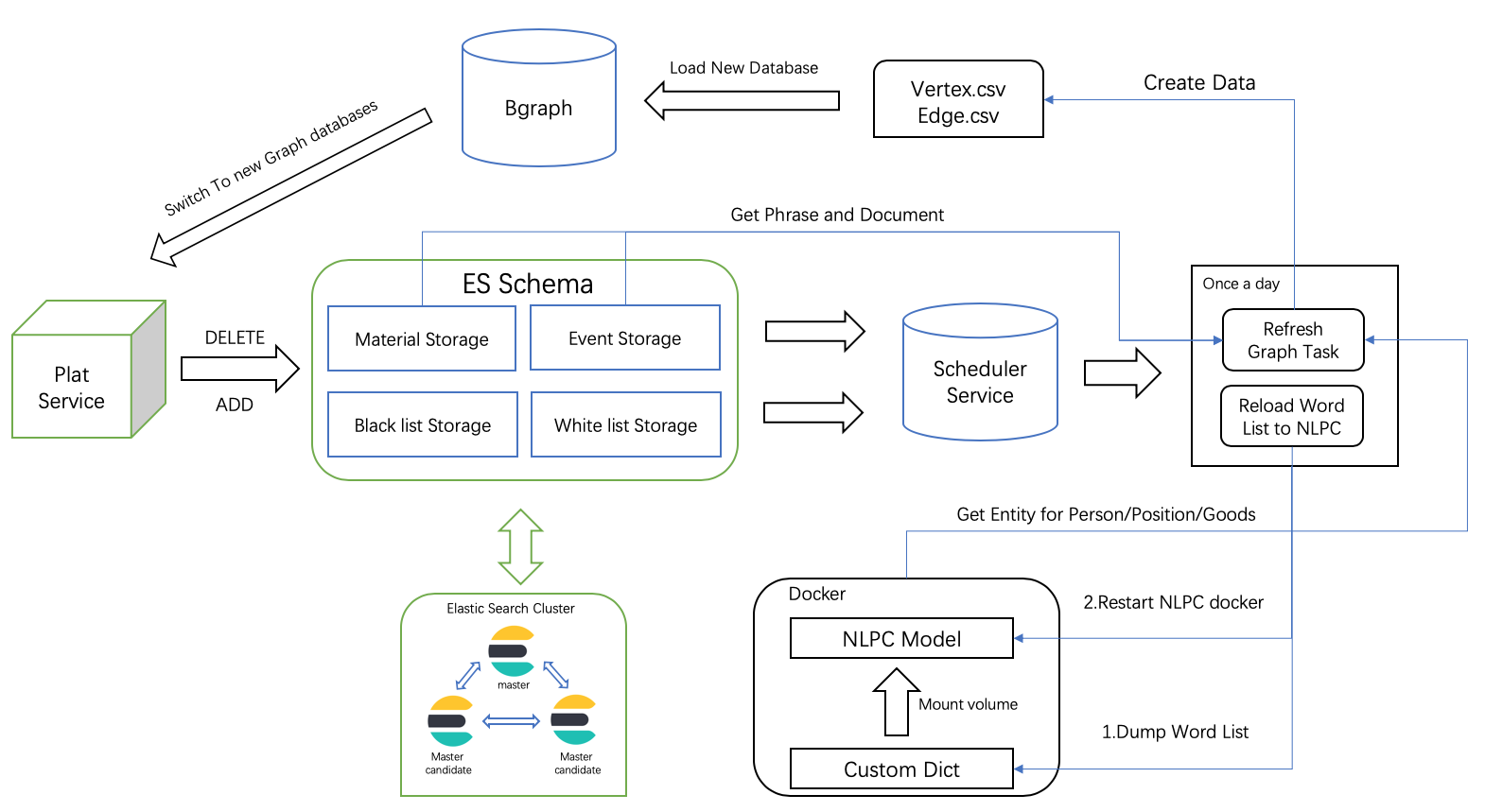
6.6.2.3 NLPC模型更新
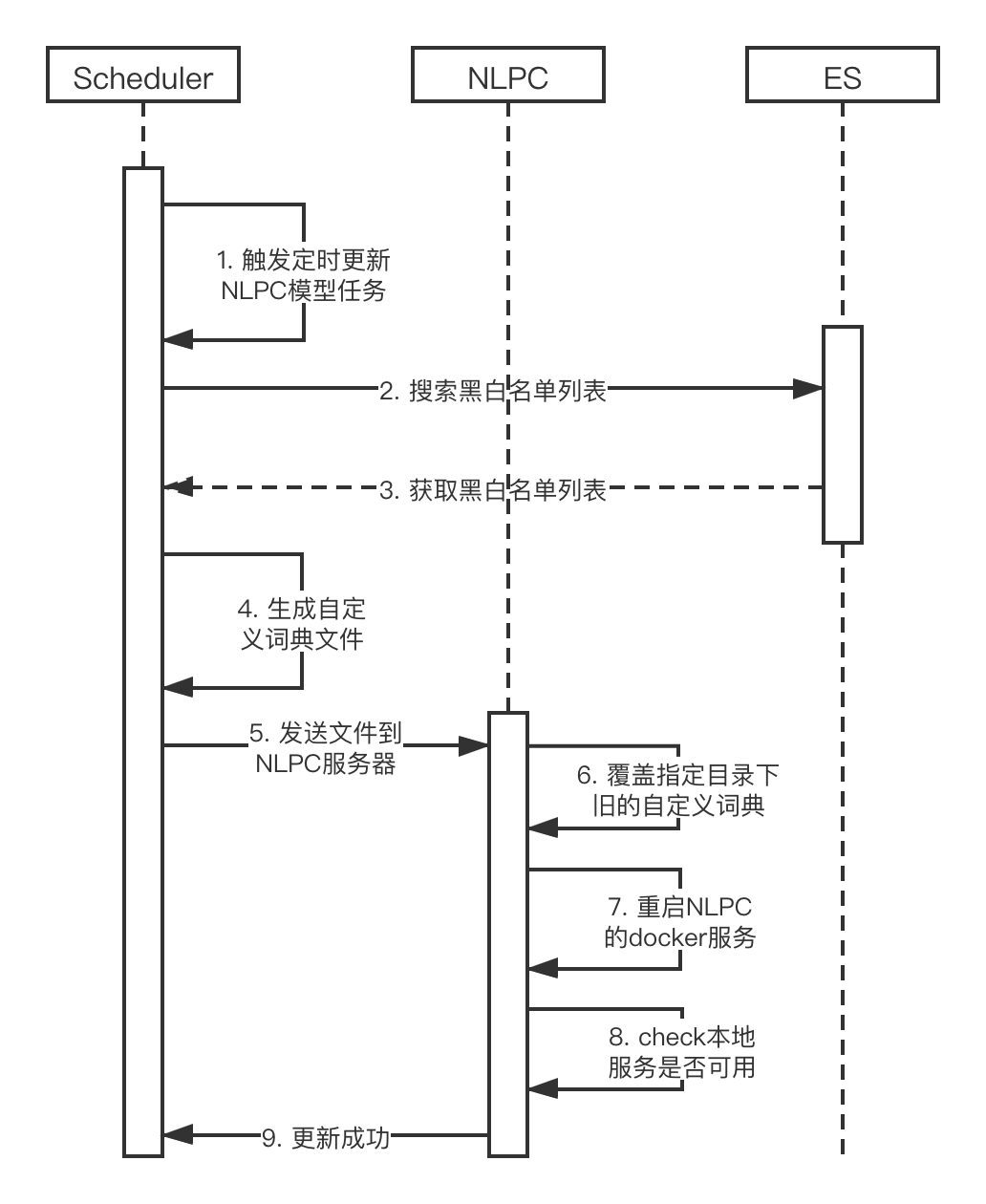
双节点docker部署确保服务的高可用,但docker重启的容错机制还没有很好的设计。
6.6.2.4 图谱数据更新
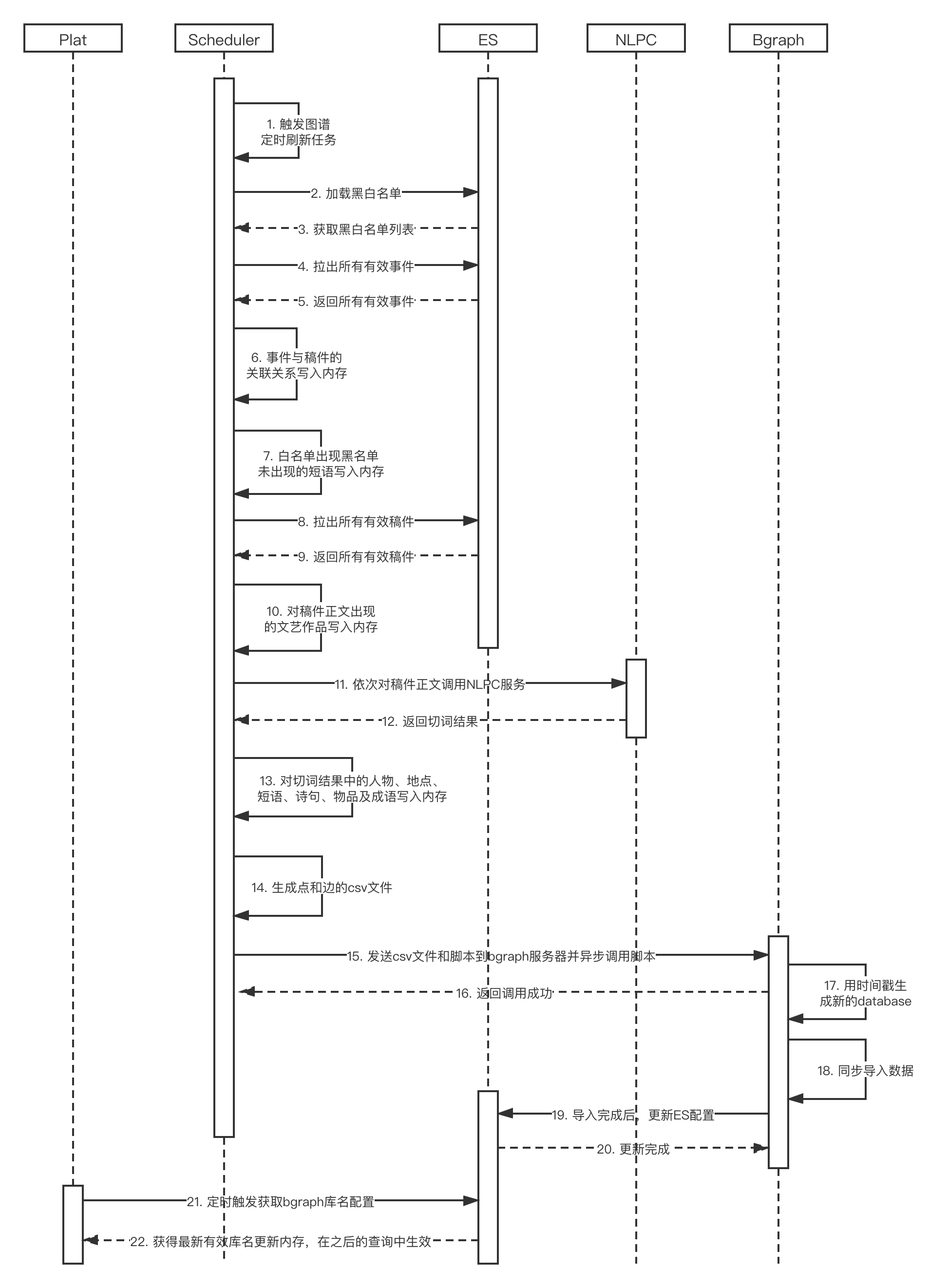
实现方案:
- word_lib_storage索引加载白名单和黑名单
- 生成点和边的csv文件,具体步骤包括
2.1 事件与稿件的关联关系写入内存,事件为点vertex,事件与稿件存在正反边edge
2.2 对短语白名单出现但短语黑名单没出现的短语写入内存,短语为点vertex,短语与存在短语的稿件存在正反边edge
2.3 查询ES material索引所有的material
2.4 对稿件正文出现的文艺作品写入内存,文艺作品为点vertex,文艺作品与存在文艺作品的稿件存在正反边edge
2.5 得到稿件正文的NLP切词结果(黑白名单过滤)存入ConcurrentHashMap<String, TermCountEntity>中,TermCountEntity包含id、name、count、type
2.6 遍历ConcurrentHashMap,对人物、地点、短语、诗句、物品及成语写入内存,点vertex为[人物 ... 成语],[人物 ... 成语]与存在[人物 ... 成语]的稿件存在正反边edge
2.7 生成vertex.csv和edge.csv文件 - 连接bgraph,拷贝vertex.csv、edge.csv及加载bgraph数据的脚本到指定目录,然后执行脚本。脚本内容包括
3.1 创建当前时间的database,如istudy20200506
3.2 执行灌库命令,即导入vertex.csv和edge.csv数据到istudy20200506
3.3 发送一条curl请求,更改system_config索引中的value为istudy20200506
然后scheduler存在定时检查任务,每隔一分钟请求system_config索引得到bgraph_database_name,然后覆盖内存中的BgraphConfig。这样下次再次请求图谱接口数据就用的istudy20200506数据库的数据了。
注意2.2中的短语、2.4中的文艺作品及2.6中的人物、地点、短语、诗句还需要判断是否存在百科词条,存在的话vertex记录需要加上[start, end],前端根据[start, end]标红,鼠标移上去会调用百科接口。此外,2.2、2.4、2.6中写vertex和edge在各个维度都用了forkJoinPool加速,整个任务的耗时大大缩短(7h -> 2.2h)
private <T> void multiThreadAccelerate(List<T> clazz, Consumer<T> consumer) {
forkJoinPool.submit(() -> clazz.parallelStream().forEach(consumer)).join();
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号