Spark ML 之 推荐算法项目(下)
一、整体思路
图1
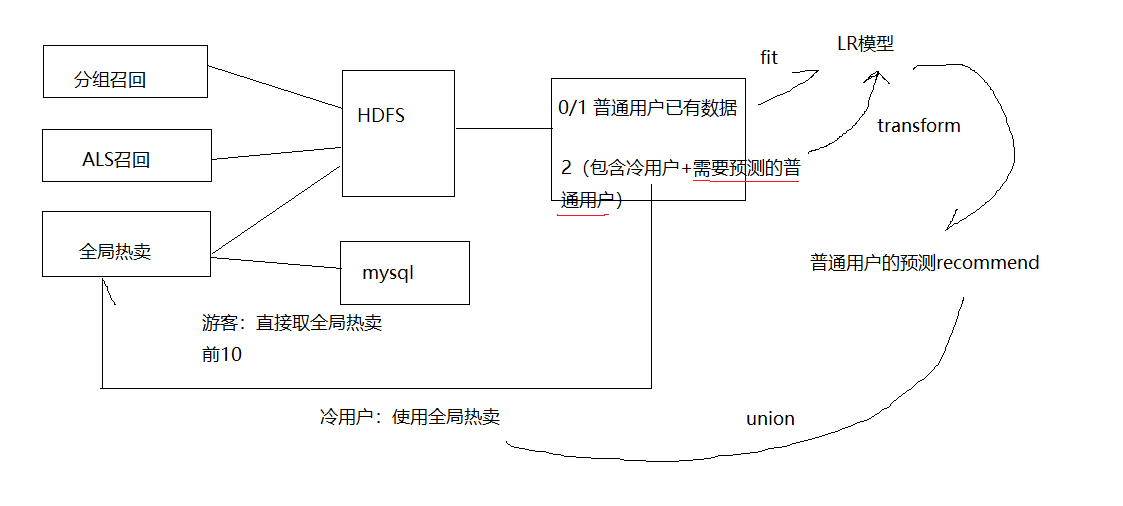
图2

二、代码分析
1)LR数据准备:
1、合并数据。用户见过的商品,根据用户行为,区分喜欢0-不喜欢1;用户没见过的商品,标记为2
// 判断用户是否喜欢商品 假设用户下单或存放购物车 就喜欢 否则不喜欢 val isLove: UserDefinedFunction = udf{ (act:String)=>{ if(act.equalsIgnoreCase("BROWSE") ||act.equalsIgnoreCase("COLLECT")){ 0 }else{ 1 } } }
import spark.implicits._ // 获取全局热卖的数据 // (cust_id,good_id,rank) val hot = HDFSConnection.readDataToHDFS(spark,"/myshops/dwd_hotsell") .select($"cust_id",$"good_id") // 获取分组召回的数据 val group = HDFSConnection.readDataToHDFS(spark,"/myshops/dwd_kMeans") .select($"cust_id",$"good_id") // 获取ALS召回数据 val als = HDFSConnection.readDataToHDFS(spark,"/myshops/dwd_ALS_Iter20") .select($"cust_id",$"good_id") // 获取用户下单数据,用户下单或购物车=> 喜欢 else=> 不喜欢 val order = spark.sparkContext .textFile("file:///D:/logs/virtualLogs/*.log") .map(line=>{ val arr = line.split(" ") (arr(0),arr(2),arr(3)) }) .toDF("act","cust_id","good_id") .withColumn("flag",isLove($"act")) .drop("act") .distinct() .cache() // 三路召回合并(包含冷用户=> 2) // 用户完全没有见过的商品填充为2 val all = hot.union(group).union(als) .join(order,Seq("cust_id","good_id"),"left") .na.fill(2)
2、准备LR模型需要的数据:label:喜不喜欢,features:user和goods的属性,并归一化
// 简单数据归一化 val priceNormalize: UserDefinedFunction =udf{ (price:String)=>{ // maxscale & minscale val p:Double = price.toDouble p/(10000+p) } }
def goodNumberFormat(spark: SparkSession): DataFrame ={ val good_infos = MYSQLConnection.readMySql(spark,"goods") .filter("is_sale=1") .drop("spu_pro_name","tags","content","good_name","created_at","update_at","good_img_pos","sku_good_code") // 品牌的数字化处理 val brand_index = new StringIndexer().setInputCol("brand_name").setOutputCol("brand") val bi = brand_index.fit(good_infos).transform(good_infos) // 商品分类的数字化 val type_index = new StringIndexer().setInputCol("cate_name").setOutputCol("cate") val ct = type_index.fit(bi).transform(bi) // 原和现价归一化 import spark.implicits._ val pc = ct.withColumn("nprice",priceNormalize($"price")) .withColumn("noriginal",priceNormalize($"original")) .withColumn("nsku_num",priceNormalize($"sku_num")) .drop("price","original","sku_num") // 特征值转数字化 val feat_index = new StringIndexer().setInputCol("spu_pro_value").setOutputCol("pro_value") feat_index.fit(pc).transform(pc).drop("spu_pro_value") }
// 每一列添加LR回归算法需要的用户自然属性,用户行为属性,商品自然属性 val user_info_df = KMeansHandler.user_act_info(spark) // 从数据库获取商品中影响商品销售的自然属性 val good_infos = goodNumberFormat(spark) // 将3路召回的数据和用户信息以及商品信息关联 val ddf = all.join(user_info_df,Seq("cust_id"),"inner") .join(good_infos,Seq("good_id"),"inner") // 数据全体转 Double val columns = ddf.columns.map(f => col(f).cast(DoubleType)) val num_fmt = ddf.select(columns:_*) // 特征列聚合到一起形成密集向量 val va = new VectorAssembler().setInputCols( Array("province_id","city_id","district_id","sex","marital_status","education_id","vocation","post","compId","mslevel","reg_date","lasttime","age","user_score","logincount","buycount","pay","is_sale","spu_pro_status","brand","cate","nprice","noriginal","nsku_num","pro_value")) .setOutputCol("orign_feature") val ofdf = va.transform(num_fmt).select($"cust_id",$"good_id",$"flag".alias("label"),$"orign_feature") // 数据归一化处理 val mmScaler = new MinMaxScaler().setInputCol("orign_feature").setOutputCol("features") val res = mmScaler.fit(ofdf).transform(ofdf) .select($"cust_id", $"good_id", $"label", $"features")
3、准备数据分两类:一类label=0/1 用于预测,一类label=2 中的普通用户 用于推荐
(res.filter("label!=2"),res.filter("label=2"))
2) LR逻辑回归:
1、取出冷用户,计算冷用户的全局热卖推荐
思路:
普通ID
left join 冷+普通ID
=> cold (cust_id,good_id,rank)
val allHot = HDFSConnection.readDataToHDFS(spark,"/myshops/dwd_hotsell") // 读出有行为的用户 val txt = spark.sparkContext.textFile("file:///D:/logs/virtualLogs/*.log").cache() import spark.implicits._ val normalUser = txt.map(line=>{ val arr = line.split(" ") (arr(2),1) }).toDF("cust_id","flag") .distinct().cache() // 冷用户flag=null,取出冷用户,求每个用户热卖前十 // .select($"cust_id",$"good_id",$"rank") // 所有用户-普通用户flag=1 => 能匹配上的flag=1,不能匹配上的flag=null val win = Window.partitionBy("cust_id").orderBy(desc("sellnum")) // cold (cust_id,good_id,rank) val cold = allHot.join(normalUser,Seq("cust_id"),"left") .filter("flag is null") // cold前10 val coldRecommend = cold.select($"cust_id",$"good_id", row_number().over(win).alias("rank")) .filter(s"rank<=${rank}")
2、从predict中剔除冷用户
思路:
($"cust_id", $"good_id", $"label", $"features")
left join
cold => (cust_id,good_id,rank,flag=1)
.filter flag = null
val (train,predict):Tuple2[DataFrame,DataFrame] = LRDataHandler.LRdata(spark) // 从 predict中剔除冷用户 val coldId = cold.map(x=>{case(cust_id,good_id,rank)=>(cust_id,1)}) .toDF("cust_id","flag") val normalPredict = predict.join(coldId,Seq("cust_id"),"left").filter("flag is null")
3、LR模型是否已经存在,不在就建
// 用户接触过的商品作为建立LR模型的训练数据 // 先检查HDFS上是否已有建造好的LR模型,如果有就直接获取 val path = new Path(HDFSConnection.paramMap("hadoop_url")+"/myshops/LR_model"); //声明要操作(删除)的hdfs 文件路径 val hadoopConf = spark.sparkContext.hadoopConfiguration val hdfs = org.apache.hadoop.fs.FileSystem.get(new URI(HDFSConnection.paramMap("hadoop_url")+"/myshops/LR_model"),hadoopConf) var model:LogisticRegressionModel = null; if(hdfs.exists(path)) { model = HDFSConnection.readLRModelToHDFS("/myshops/LR_model") }else{ val lr = new LogisticRegression().setMaxIter(20).setRegParam(0.01) model = lr.fit(train) HDFSConnection.writeLRModelToHDFS(model,"/myshops/LR_model") }
4、用LR模型预测普通人需要被推荐哪些他没见过的商品
//Transforms dataset by reading from [[featuresCol]] // 只需要predict中的 featuresCol // predict需要踢出冷用户 val res = model.transform(normalPredict).drop("features") import spark.implicits._ val wnd = Window.partitionBy($"cust_id").orderBy(desc("score")) // 普通用户推薦的商品 (三路召回后建立 LR模型) (cust_id,good_id,rank) val normalRecommend = res.select("cust_id","good_id","probability") .rdd.map{case(Row(uid:Double,gid:Double,score:DenseVector))=>(uid,gid,score(1))} .toDF("cust_id","good_id","score") .select($"cust_id",$"good_id",row_number().over(wnd).alias("rank")) .filter(s"rank<=${rank}")
5、普通人用LR预测+冷用户用全局热卖,合并推荐结果
// 合并冷普用户推荐结果 (cust_id,good_id,rank) val recommend = normalRecommend.union(coldRecommend) MYSQLConnection.writeTable(spark,recommend,"userrecommend")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号