#time模块
import time
print(time.time()) #时间戳:用来计算时间差,单位秒。如1556115328.368191秒
print(time.localtime()) #结构化显示当地年月日时分秒,周几(从 0 开始),一年中的第几天
n = time.localtime()
print(n.tm_wday) #显示今天周几
print(n.tm_hour) #显示当前的小时
print(time.gmtime()) #结构化显示世界标准时间,即零经度的时间,与中国的东八区差八个小时
#将时间戳转换成结构化时间
print(time.localtime(1556113312)) #参数是时间戳,如time.localtime(1556115329)
#将机构化时间转换成时间戳
print(time.mktime(time.localtime()))
#将结构化时间转换成字符串型时间,格式可以自定义
"""
两个参数:第一个是设置转换成的时间格式,第二个是要转换的结构化时间
第一个参数的格式“%Y %m %d %X”,字符串中每个元素可用任意字符连接,注意要放在“”中
但%号后的时间代指必须固定:年->Y,月->m,日->d,时->H,分->M,秒->S,除了月日小写,其余都是大写
时分秒也可以直接就用默认格式 X 代替,默认的格式为 时:分:秒
"""
print(time.strftime("%Y-%m-%d %X",time.localtime()))
#将字符串型时间转换成结构化时间
#同样两参数:第一个要转换的字符串型时间,第二个是格式,注意前后格式要保持一致
print(time.strptime("2019-04-24 22:48:33","%Y-%m-%d %X"))
#转成 固定格式 的字符串型时间:周几 月 日 时:分:秒 年
print(time.asctime()) #将结构化时间转成 固定 的字符串型时间:Wed Apr 24 22:56:21 2019
print(time.ctime()) #将时间戳转成 固定 的字符串型时间:Wed Apr 24 22:56:21 2019
import datetime
print(datetime.datetime.now()) #一种更直观的显示时间的方式
#random模块(随机模块)
import random
print(random.random()*2) #随机提供一个(0-1)之间的一个浮点数,可在得出之后做运算
print(random.randint(1,6)) #在给定的一个范围随机选取一个整数:这个范围左边界和右边界都包含
print(random.randrange(1,3)) #在给定的一个范围随机选取一个整数:这个范围包含左边界不包含右边界
print(random.choice([1,2,3,12,23])) #随机选择给定的列表中的某个元素,只能选一个元素
print(random.sample([11,22,33,12,23,13],2)) #随机选择给定列表中的几个元素,第二个参数表示选几个
print(random.uniform(1,4)) #随机选择给定范围内的浮点数
n = [1,2,3,4,5]
random.shuffle(n) #打乱给定的列表顺序,注意这个返回值是None,不能打印它,要打印原列表
print(n)
#设计一个验证码
def v_code():
ret = ""
for i in range(5): #设置有多少位验证码,迭代几次就有几位验证码
num = random.randint(0,9)
alf = chr(random.randint(65,122)) #chr转换成ASCII码,大写A(65)到小写z(122)
s = str(random.choice([num,alf])) #将数字和字母放在一个列表中,然后choice选择
ret += s
return ret
print(v_code())
os模块
"""
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
"""
#sys模块
import sys
sys.exit(0) #退出程序
sys.path #返回模块路径,然后再做其他操作,如.append("路径")
sys.argv[] #获取外部传入的参数,第一个参数程序本身路径,第二个之后都是外部输入的数值
#如sys.argv[1],就是获取外部输入的第一个参数
#设置一个进度条
import time
for i in range(10):
sys.stdout.write("*")
time.sleep(0.1)
sys.stdout.flush()
#json模块:任何语言都通用,json它是JavaScript中一个对象
import json
dic = {"name":"sjy"}
date = json.dumps(dic) #这个得到的是json字符串,将传入的数据类型都变成json字符串
#json只认双引号,它会把数据类型的里面的所有单引号变成双引号,实质是变成json中的字符串格式
f = open("new","w")
f.write(date) #将经过json方法处理过的json字符串写进文件中
f.close()
with open("new","r") as f_r:
n = json.loads(f_r.read()) #用json方法读取这个文件,这样得到的内容时json字符串内的数据类型
print(n) #相当于eval()提取字符串中的数据类型,但json是通用的,经过json处理可以直接在其他语言上用
print(type(n))
# json.dump(dic,f) #这个等同于date=json.dumps(dic);f.write(date)这两步
# json.load(f_r) #等同于json.loads(f_r.read())
#这两种用于文件操作,建议用 dumps,loads 这两个可使用范围广些
"""
json 会把给的数据类型里面的单引号变成双引号,并将其变成json字符串,实质是变成json中的字符串格式
例如:原内容 ------> 转换成字符串 ---->显示给用户的内容
dic = {'name':'sjy'} ------> '{"name":"sjy"}'---->{"name":"sjy"}
i = 7 ------> '7' ---->7
s = 'hello' ------> '"hello"' ---->"hello"
l = [1,2,3] ------> "[1,2,3]" ---->[1,2,3]
json是通用的,对一些内容进行json处理后,可以以json字符串的形式存放在硬盘中
而调用这些内容时,可以用json的方法直接调用json字符串里的数据类型,类似eval()
但相比较而言json可以跨语言使用,其他语言可以直接拿取使用
json中dumps方式是将内容序列化,loads是反序列化
"""
#pickle模块,使用方法和json一样,功能也类似
import pickle
dic = {'name':'sjy'}
j = pickle.dumps(dic) #注意和json的区别,pickle是将数据类型转换成字节
with open("new_p","wb") as f: #因为是pickle是将内容转换成字节,要wb方式写入
f.write(j)
with open("new_p","rb") as f_r:
n = pickle.loads(f_r.read())
print(n)
#shelve模块
import shelve
f = shelve.open(r"new_s") #用shelve方法建立文件,再将数据内容写进去,会生成3个文件
f["shout"] = {"name":"sjy"}
f.close()
f.get("shout") #用这个模块可以直接使用写进去的数据类型的方法,这个模块是在内部已做好序列化和反序列化的操作
#xml模块:和json的区别,xml使用的是标签语言
import xml.etree.ElementTree as ET #导入这个模块,并将这个模块赋值给某个变量,模块名太长,赋值给变量,方便书写
tree = ET.parse("xml_lesson") #利用parse方法将xml文件解析出来,并将内容赋值给一个变量,此时这个变量就是一个对象
root = tree.getroot() #获取这个对象的根
print(root.tag) #.tag获取这个根标签的名字
for i in root: #循环遍历这个根,获取根下的内容
print(i) #这里打印出来的是内存地址,因为得到的是一个个对象
print(i.tag) #通过.tag获取每个对象的根标签名字
print(i.attrib) #通过.attrib方法获取每个标签里的属性,放在一个字典中
for j in i: #遍历这个根
print(j.tag) #和上面一样,获取名字
print(j.attrib) #获取标签里的属性
print(j.text) #通过.text获取每个标签里的具体文本内容
for node in root.iter("year"): #通过.iter('标签名")获取某一层级的所有这个名字标签
print(node.tag,node.text)
new_year = int(node.text) + 1 #对这个标签里的文本内容进行修改
node.text = str(new_year) #将修改的内容再赋值给这个标签
node.set("date","no") #用.set对这个标签的属性进行修改
tree.write("new_xml.xml") #将修改的内容重新写进xml文件
for count in root.findall("country"): #.findall("标签名")找出所有的这个名字的标签
ran = int(count.find("rank").text)
if ran > 50:
root.remove(count) #移除
tree.write("out_xml.xml")
"""
将一个xml文件通过parse方法解析后,再循环遍历每个层级,
并用.tag方法获取每个层级根标签的名字,注意是根标签,不是所有,不包含根里嵌套的标签
.attrib方法获取每个标签的属性,
.text方法获取标签里具体的文本内容
若想只获取其中一个标签,用.iter("标签名")方法得到这个层级下的所有(含嵌套里的)这个名字的标签
若想修改某个标签里的文本内容:先.next获取内容,再修改获取的内容后传回给.next
修改标签的属性:.set("属性名","属性内容"),最后将修改的内容write写进xml
"""
#创建一个xml
new_xml_lesson = ET.Element("namelist")
#使用模块方法 .Element("标签名") 创建一个根标签namelist并赋值给一个变量
name = ET.SubElement(new_xml_lesson,"name",attrib = {"enrolled":"no"})
#使用模块方法 .SubElement("上一级标签","当前级标签","当天级标签属性") 创建下一级的标签并赋值给一个变量
age = ET.SubElement(name,"age",attrib={"checked":"no"},)
sex = ET.SubElement(age,"sex")
sex.text = "25" #对某个标签添加文本内容
et = ET.ElementTree(new_xml_lesson) #使用模块方法.ElementTree 将整个根内容生成文档对象
et.write("test.xml",encoding="utf8",xml_declaration=True) #把它写进一个xml文件中
# ET.dump(new_xml_lesson) #打印生成的格式
import re
re.findall("alex","asfjsuisjafjxds") #完全匹配
re.findall("a..x","asfjsuisjafjxds") #通配符 . 一个点代表一个任意字符,模糊匹配,注意不能匹配\n
re.findall("^a..x","asfjsuisjafjxds") # ^ 只从开头寻找匹配,第一个字符找不到对应的则为空
re.findall("a..x$","asfjsuisjafjxds") # $ 只看末尾是否有匹配的
re.findall("d*","asdddddddddddghiu") # * 重复多次(0-∞)匹配这个字符,匹配不上返回空
re.findall("alex+","sdfalexxxxxgs") # + 重复多次(1-∞)匹配
re.findall("alex?","sdfalexxxxxgs") # ? 只取(0,1)个
#注意 * , + , ? 这个三个多次匹配的区别,* 可以匹配 0个 ,+ 必须最少匹配1个
# ? 还有一个作用 ,将贪婪匹配变成惰性匹配,惰性匹配,按最少的次数匹配,如“alex*?”这个就只做0次匹配
# 而{}可以自己设置匹配多少次如{2,5}等
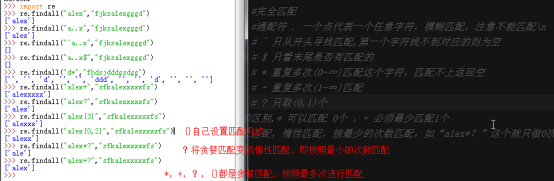
re.findall("x[yz]p","sddxypsfxzpd") #[] 放在这里的字符有一个满足匹配就可以,是一个或的作用
re.findall("x[a*z]","sdxfpfhjxzpfgk") #在元字符【】中没有特殊字符,这里*不代表匹配多次a
re.findall("x[a-z]","sdxfpfhjxzpfgk") #【】这个字符集中只有 - ,^ , \ 这三个有正常功能
re.findall("x[a-z]*","sdxfpfhjxzpfgk")
re.findall("x[^a-z]","sdxfpfhjx32gk") #【】字符集中加上 ^ ,此时这个不在表示开头匹配,而表示非

"""
反斜杠后边跟元字符去除特殊功能,比如\.
反斜杠后边跟普通字符实现特殊功能,比如\d
\d 匹配任何十进制数;它相当于类 [0-9]。
\D 匹配任何非数字字符;它相当于类 [^0-9]。
\s 匹配任何空白字符;它相当于类 [ \t\n\r\f\v]。
\S 匹配任何非空白字符;它相当于类 [^ \t\n\r\f\v]。
\w 匹配任何字母数字下划线字符;它相当于类 [a-zA-Z0-9_]。
\W 匹配任何非字母数字下划线字符;它相当于类 [^a-zA-Z0-9_]
\b 匹配一个特殊字符边界,比如空格 ,&,#等
"""
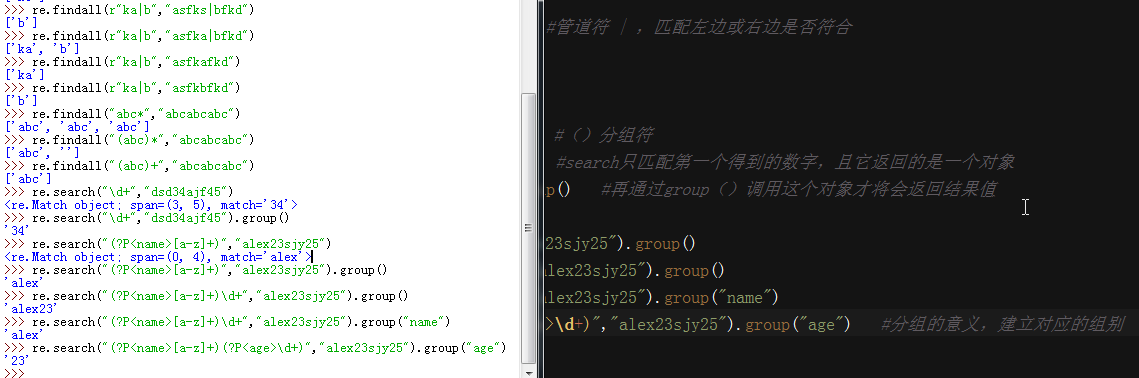
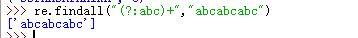
#re模块的方法
re.findall("a","fhajsaja") #匹配所有符合的内容,并将结果返回到一个列表中
re.search("a","sjasfaska") #匹配到第一个内容就返回结果,注意这个返回的是一个对象,需要用group()方法调用
re.match("a","askfjl") #同search,但是匹配开头第一个是否符合
re.split("[ |]","hello abc|def") #分割,可以按照多个字符进行分割
re.split("[ab]","asdabcd") #按照顺序依次分割,注意当左边不存在字符时分割它会出现空字符
re.sub("\d+","AA","sajf23af22sj") #替换,需要三个参数,(匹配规则,替换的字符,原字符串)
re.sub("\d","A","ssf23shf45lk2",3) #第四个参数是匹配替换多少次
re.subn("\d","A","ssf23shf45lk2") #统计匹配替换的次数
res = re.compile("\d") #编译一个规则,下次可以直接用编译好的规则
res.findall("sfkla23jak1j42lk2")
re.finditer("\d","as23ha24ah5a") #得到的是一个迭代对象,调用时next().group()
re.findall("www\.(baidu|163)\.com","aswww.baidu.comaf") #findall()优先给出组内的结果,而不是全部的匹配结果
re.findall("www\.(?:baidu|163)\.com","aswww.baidu.comaf") #在组()内加上?:表示取消优先级
#logging模块
import logging
#通过basicConfig方法设置日志格式,但这种只能在屏显和文件显示中选择其中一个
logging.basicConfig( #设置日志的各种信息
level=logging.DEBUG, #设置级别最低为debug级别
filename="logger.log", #设置创建日志存放的文件
filemode="w", #设置日志填写的模式,默认下是追加模式 a ,设置“w“模式
format="%(asctime)s %(filename)s [%(lineno)d] %(message)s"
#format 参数,对日志的显示内容进行设置
)
# logging 的5中级别,下面级别从低到高
logging.debug("debug message")
logging.info("info message")
logging.warning("warning message")
logging.error("error message")
logging.critical("critical message")
"""
filename:用指定的文件名创建FiledHandler,这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的日志级别
stream:用指定的stream创建StreamHandler。
可以指定输出到sys.stderr,sys.stdout或者文件(f=open('test.log','w')),
默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略
format参数中可能用到的格式化串:
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
%(message)s 用户输出的消息
"""
#设置一个logger,这个设置可以将它封装到一个函数内,使用时再调用
logger = logging.getLogger() #建立一个日志对象
fh = logging.FileHandler("test.log") #创建向文件发送的Handler
ch = logging.StreamHandler() #创建向屏幕发送的Handler
fm = logging.Formatter("%(asctime)s %(message)s") #设置日志显示格式
fh.setFormatter(fm) #将格式传到文件
ch.setFormatter(fm) #将格式传到屏显
logger.addHandler(fh) #拿取文件显示的内容
logger.addHandler(ch) #拿取屏显的内容
logger.setLevel("DEBUG") #设置最低级别
#调用
logger.debug("hello")
logger.info("hello")
logger.warning("hello")
logger.error("hello")
logger.critical("hello")
"""
#如果创建两个logging对象,而这两个对象的根目录名是相同的,则后面创建的对象会覆盖上面创建的对象,
#这样无论前面是怎么设置的,都不会生效
logger1 = logging.getLogger("mylogger")
logger2 = logging.getLogger("mylogger")
#如果创建存在层级关系的对象,如下创建一个在根目录下的对象,再创建根下子目录下的对象
#则若logger运行,logger1会运行两次,因为他会从根开始运行,以此类推,只有上一级不运行,下一级才会只运行一次
logger = logging.getLogger()
logger1 = logging.getLogger("mylogger")
"""
#configparser模块:配置解析模块
import configparser
config = configparser.ConfigParser() #创建一个配置解析对象
config["DEFAULT"] = {
"name":"sjy",
"age":"25",
} #添加配置内容,类似创建字典,再添加到文件中去
with open("confile.ini","w") as f: #文件名的扩展名任意
config.write(f) #注意配置文件写入和单纯文件写入的不同,单纯文件写入是f.write()
#查
config.read("example.ini") #需要先导入需要操作的配置文件
print(config.sections()) #打印出配置文件中(除了默认的DEFAULT)其他的块名
print("bytebong.com" in config) #判断这个块名是否在这个配置文件中
print(config["bitbucket.org"]["user"]) #取到块中的具体内容,不区分大小写
for i in config["topsecret.server.com"]:
print(i) #不管遍历哪个块,默认的DEFAULT块都会被遍历出来
print(config.options("topsecret.server.com")) #遍历这个块,并将得到的内容放到列表中,注意默认块也会被遍历
print(config.items("topsecret.server.com")) #遍历这个块,并以键值对的方式放到字典中
print(config.get("topsecret.server.com","compressionlevel")) #获取块里的内容
#删,改,增
config.add_section("yuan") #添加块
config.set("yuan","k1","22") #添加块中的键值对
config.remove_section("bitbucket.org") #删除配置文件中的块
config.remove_option("topsecret.server.com","forwardx11") #删除块中的键值对
config.write(open("new_example.ini","w"))
#hashlib模块:用于加密操作,做hash算法,摘要算法
import hashlib
obj = hashlib.md5("53sb".encode("utf8")) #md5加密,括号里的参数自己设置放在需要加密信息前使得密文改变,防止撞库解密
obj.update("hello".encode("utf8")) #原生md5加密的密文对应关系固定,自己加点东西,使其与原生不一样
print(obj.hexdigest()) #得到一个密文,密文长度是固定的,不可逆的加密
obj.update("admin".encode("utf8")) #在上面做过加密后,再次调用,是在原先基础上再加密
print(obj.hexdigest()) #这里得到的密文是helloadmin的密文
hash = hashlib.sha256() #sha256加密,方法与md5类似
hash.update("hello".encode("utf8"))
print(hash.hexdigest())


 浙公网安备 33010602011771号
浙公网安备 33010602011771号