import requests
from bs4 import BeautifulSoup
import re
cookie = {}
f = open('cookie.txt','r')#微信该网页无法直接爬取 添加cookie文件
for line in f.read().split(':'):
name,value=line.strip().split('=',1)
cookie[name]=value
headers={'User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
page = requests.get('https://tophub.today/n/WnBe01o371',headers=headers,cookies=cookie).content.decode('utf-8')
soup = BeautifulSoup(page,'lxml')#构造html解析对象,补全数据
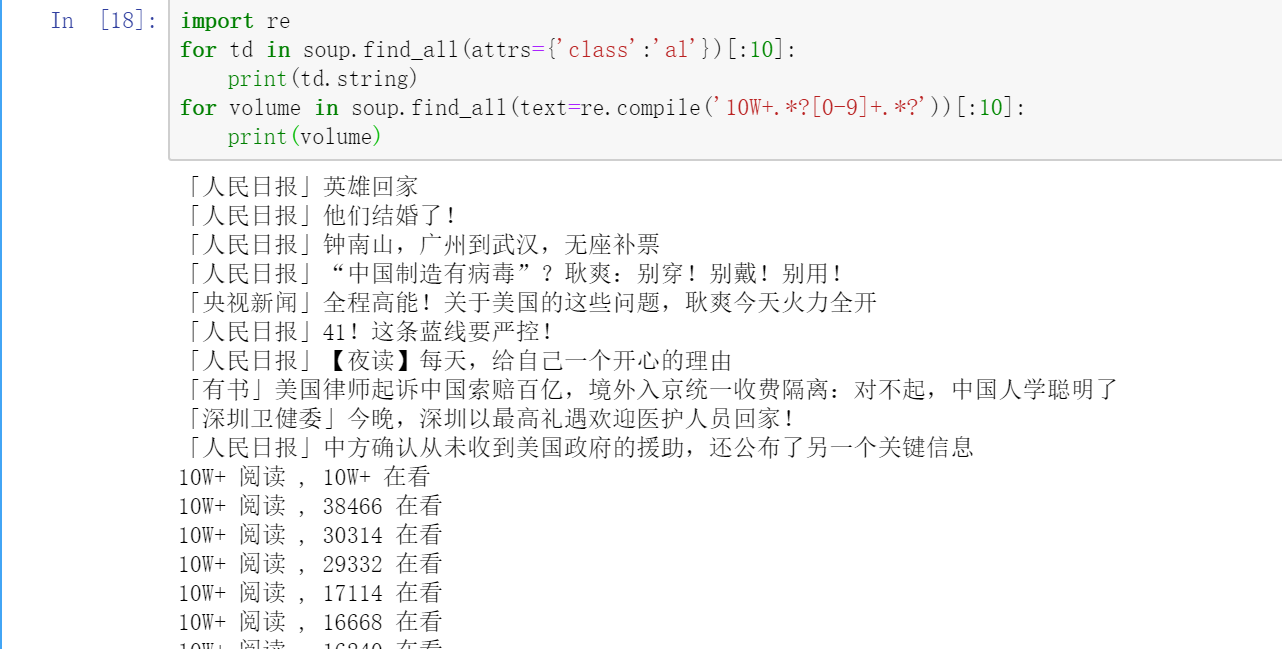
for td in soup.find_all(attrs={'class':'al'})[:10]:
print(td.string)
for volume in soup.find_all(text=re.compile('10W+.*?[0-9]+.*?'))[:10]:
print(volume)
附 输出结果
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号