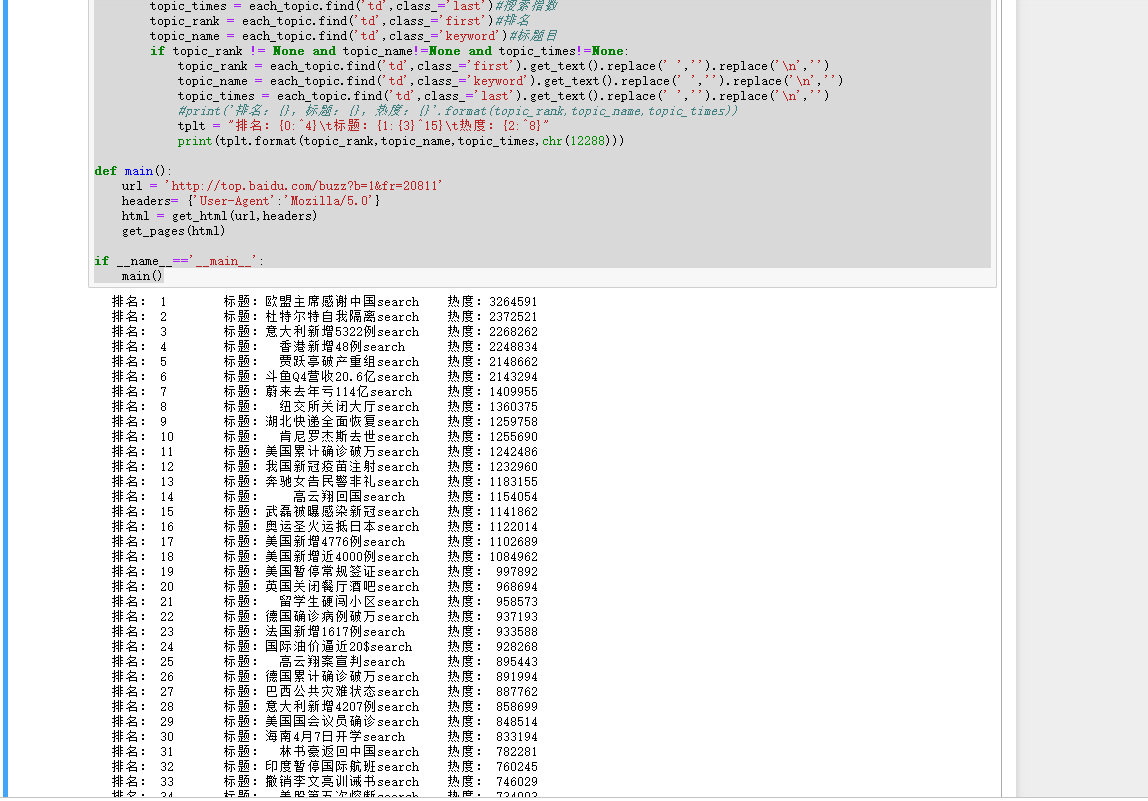
用Python爬取百度热点前50
import requests
from bs4 import BeautifulSoup
import bs4
def get_html(url,headers):
r = requests.get(url,headers=headers)
r.encoding = r.apparent_encoding
return r.text
def get_pages(html):
soup = BeautifulSoup(html,'html.parser')
all_topics=soup.find_all('tr')[1:]
for each_topic in all_topics:
#print(each_topic)
topic_times = each_topic.find('td',class_='last')#搜索指数
topic_rank = each_topic.find('td',class_='first')#排名
topic_name = each_topic.find('td',class_='keyword')#标题目
if topic_rank != None and topic_name!=None and topic_times!=None:
topic_rank = each_topic.find('td',class_='first').get_text().replace(' ','').replace('\n','')
topic_name = each_topic.find('td',class_='keyword').get_text().replace(' ','').replace('\n','')
topic_times = each_topic.find('td',class_='last').get_text().replace(' ','').replace('\n','')
#print('排名:{},标题:{},热度:{}'.format(topic_rank,topic_name,topic_times))
tplt = "排名:{0:^4}\t标题:{1:{3}^15}\t热度:{2:^8}"
print(tplt.format(topic_rank,topic_name,topic_times,chr(12288)))
def main():
url = 'http://top.baidu.com/buzz?b=1&fr=20811'
headers= {'User-Agent':'Mozilla/5.0'}
html = get_html(url,headers)
get_pages(html)
if __name__=='__main__':
main()
输出结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号